我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!
资讯
微软甩开OpenAI自研大模型,还计划用DeepSeek
微软正在加速自研人工智能模型的开发,以降低对OpenAI的依赖。微软曾是OpenAI的主要支持者,投入巨资并广泛部署GPT系列模型,但随着技术突破和双方分歧加剧,微软开始开发内部模型MAI,目标是替代OpenAI的核心模型o1和o3-mini。目前,微软正在测试MAI模型在Copilot AI智能助手中的应用,Copilot旨在处理广泛用户问题并提供具体建议。除了自研模型,微软还在测试来自xAI、Meta、Anthropic和DeepSeek的替代模型,以提升Copilot的技术能力。
微软与OpenAI的合作曾使其在AI领域占据先发优势,但微软一直致力于减少对OpenAI的依赖。去年秋季,微软AI部门负责人Mustafa Suleyman要求OpenAI提供o1模型的详细技术文档,尤其是模型的“思维链”推理过程,但OpenAI拒绝透露,导致双方关系紧张。为实现AI业务的独立发展,Suleyman加码微软自身的AI研究团队,由Karén Simonyan领导,专注于开发MAI模型。目前,MAI模型在通用基准测试中已达到与OpenAI、Anthropic顶尖模型相当的性能水平,并通过思维链技术提升对复杂问题的处理能力,形成差异化竞争。
微软已启动MAI模型在Copilot产品中的替代测试,新一代MAI在参数量级与场景适应性方面实现显著提升。微软还计划在今年晚些时候推出MAI的API,供外部开发者集成微软AI模型到自己的应用程序中,届时微软将与OpenAI、Anthropic、DeepSeek等成为直接竞争对手。
https://mp.weixin.qq.com/s/Wnr00XERVywkol80x0hxHw
目标超级智能,前DeepMind科学家离职创业,获1.3亿刀融资
3月8日,两名前谷歌DeepMind研究人员Misha Laskin和Ioannis Antonoglou宣布成立名为Reflection AI的公司,目标是开发超级智能。该公司已获得1.3亿美元融资,估值达5.55亿美元。创始人背景强大,Misha曾参与谷歌Gemini大语言模型的训练工作,Ioannis是AlphaGo的幕后功臣。团队成员多来自DeepMind、OpenAI等前沿实验室,曾主导开发AlphaGo和Gemini等先进AI系统。
Reflection AI计划开发自主编程工具,将其作为构建超级智能的第一步。该工具将包括扫描代码漏洞、优化内存使用、测试可靠性等功能,并生成代码文档,管理应用程序运行基础设施。公司计划使用大语言模型和强化学习驱动软件,探索新型架构,超越Transformer架构。此外,公司还计划使用数万块显卡训练模型,并开发类似vLLM平台的工具以减少语言模型内存使用。
7B级形式化推理与验证小模型,媲美满血版DeepSeek-R1,全面开源!
近日,由香港科技大学牵头,联合中国科学院软件研究所、西安电子科技大学和重庆大学等单位的研究团队开源了一系列7B级形式化推理与验证大模型。这些模型在相关任务上达到了与671B满血版DeepSeek-R1相当的水平,并已全面开源。研究团队由香港科技大学研究助理教授曹嘉伦、中科院软件所副研究员陆垚杰等核心成员组成,专注于AI与形式化验证等领域。
随着DeepSeek-R1的流行和AI4Math研究的深入,大模型在辅助形式化证明写作方面的需求增长。然而,现有的形式化推理大模型大多只针对单一形式化语言,缺乏对多语言和多任务场景的深度探索。此次开源的模型通过7B参数规模,实现了对多种形式化语言(如Coq、Lean4、Dafny、ACSL、TLA+)的支持,并在六种细分任务上进行了能力对比。
研究团队对形式化验证任务进行了分层拆解,从非形式化的自然语言输入到可验证的形式化证明或模型检测,将传统端到端形式化验证流程细化为六个子任务,包括需求分解、规约片段生成、规约补全等。通过从GitHub收集并整理数据,团队构建了包含14k数据的微调数据集(fm-alpaca)和4k数据的测试集(fm-bench)。
实验结果显示,未经微调的通用指令大模型在从代码生成形式化证明方面表现较好,但在从自然语言生成形式化证明方面表现较差。满血版DeepSeek-R1平均准确率为27.11%,而其他8B至72B的模型平均准确率仅为7.32%至18.39%。此外,较大规模模型在形式化规约填空任务中表现不如小规模模型,可能是因为大规模模型生成的内容过多导致准确率下降。
在不同形式化语言上,大模型在ACSL上的表现最好,Dafny次之。通过增加生成次数和上下文学习,模型准确率可显著提升。经过形式化数据(fm-alpaca)微调后,7~8B模型在各类形式化任务上的性能几乎翻倍,且仅使用14k形式化相关指令数据即可实现显著提升。混合形式化数据和对话型指令数据微调时,模型性能进一步提升。
此外,形式化数据微调还提升了模型在数学、推理和编程任务上的性能,平均提升1.37%至5.15%。这表明形式化验证能力训练可能帮助模型习得推理、数学等“元能力”。此次开源的微调模型基于LLaMA-3.1、Qwen-2.5和Deepseek-coder-v1.5等基础模型,性能媲美671B的DeepSeek-R1。开源的执行上下文和自动验证流程将降低形式化验证的门槛,减少人力消耗和部署成本。
https://mp.weixin.qq.com/s/oyhICTRo2fJL5MZkDrutXg
推特
推理模型的现状:12 篇关于提升大模型推理能力的新研究
我刚刚分享了一篇新文章《推理模型的现状》,在其中探讨了 12 篇关于提升大模型推理能力的新研究(均发表于 DeepSeek R1 发布之后):
5. 关联思维链(Chain-of-Associated-Thoughts)
10. 内部思考变换器(Inner Thinking Transformer)
2025 年第一季度在推理模型研究方面确实非常活跃!
https://x.com/rasbt/status/1898382212174643511
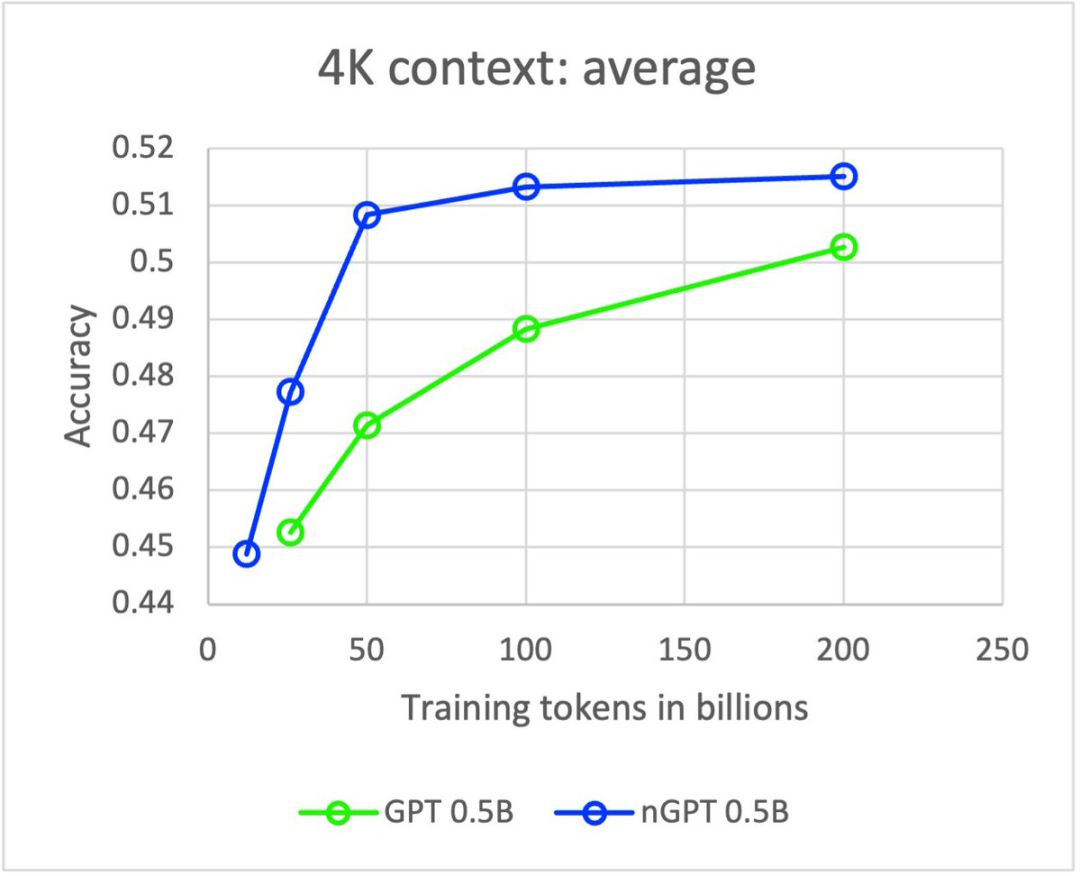
Nous Research分享:NVIDIA nGPT 论文的开源实现
我们自豪地宣布推出 NVIDIA nGPT 论文的开源实现!
我们的研究员@Joeli5050复现了实验结果,证明 nGPT 训练速度显著加快,并且在大幅减少训练步数的情况下,依然能达到与 GPT 相当的性能。
🔗 开源代码地址:GitHub – JoeLi12345/nGPT
https://x.com/NousResearch/status/1898073676433551630
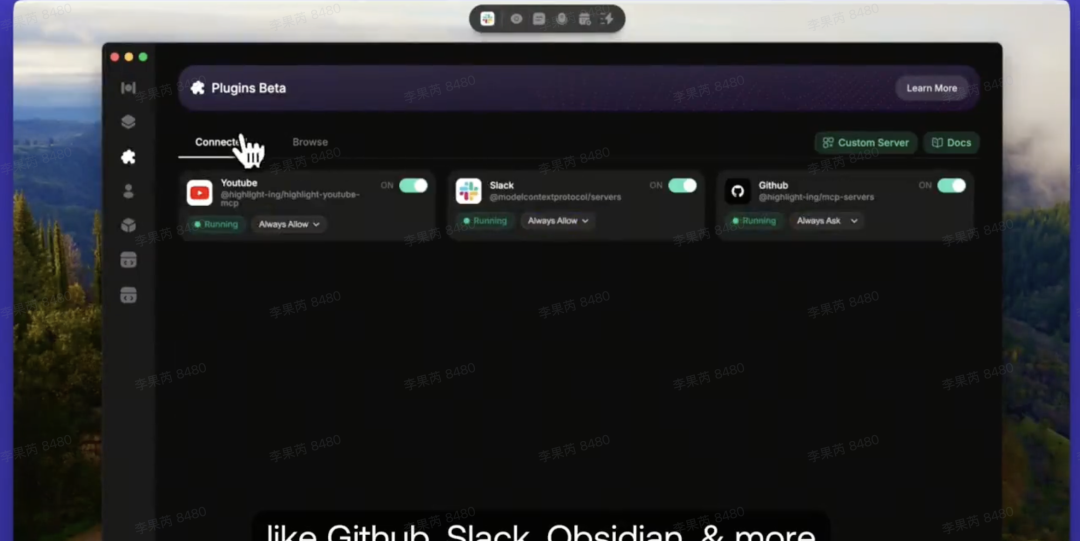
在过去两周里,我们与 Vinayak Mehta 和 Adis Banda 合作开发了一款桌面应用,让你可以将自己喜爱的应用连接到 Claude。
这是一种让非技术用户轻松发现和安装 MCP 的最佳方式!


https://x.com/0xferruccio/status/1898429209388675554
Highlight AI:发布 MCP 服务器的首选界面
你喜欢的 Cursor 体验,现在覆盖你电脑上的所有应用。
这本该是 Apple Intelligence 和 Copilot 该做到的。
1. 屏幕锚定:在任何服务内 @ 直接调用,并通过 Tab 键轻松输入。
https://x.com/PimDeWitte/status/1898023432937521592
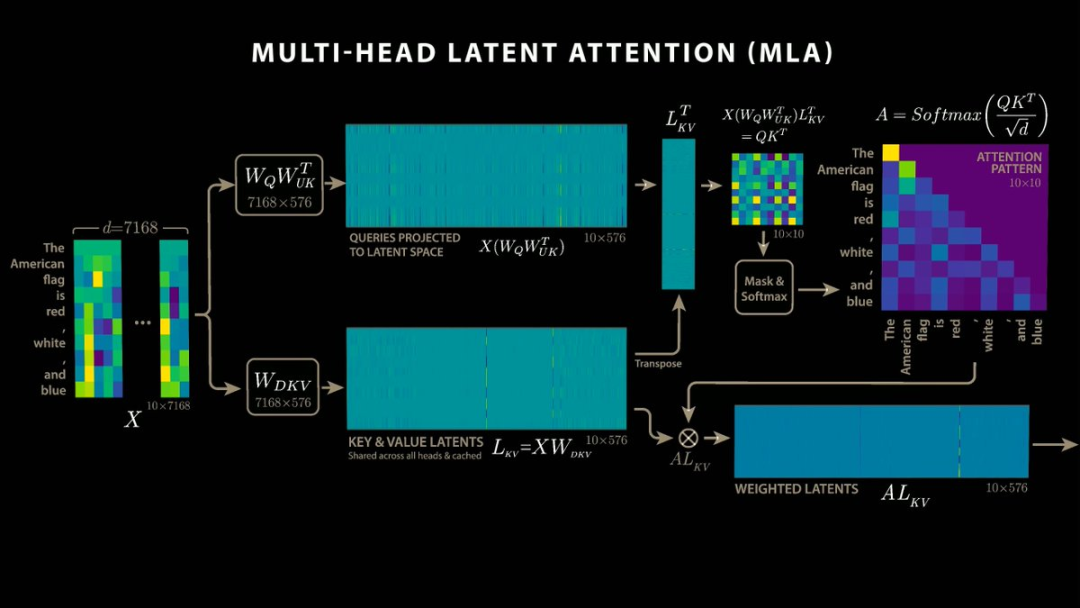
Welch Labs分享:DeepSeek 57 倍效率提升的奥秘【MLA】
Welch Labs 的新视频 关于 DeepSeek-R1 和 多头潜在注意力(MLA) 太炸裂了!
视频深入讲解了 KV 缓存、不同的优化策略,并且可视化效果非常出色。
📺 观看链接:YouTube – DeepSeek-R1 MLA
https://x.com/skalskip92/status/1898048842458689783
Opennote Journals:以思维的速度学习,结合 多模态、实时协作 记录,与 Feynman 无缝集成,助力学习以思维的速度学习,结合 多模态、实时协作 记录,与 Feynman 无缝集成,助力你的学习之旅。
https://x.com/abh1a0/status/1898073496170725774
产品
忘掉传统平台上没完没了的来回沟通吧 ——Lanceboard 让你可以为任务发布 “工单”,我们基于人工智能的系统会根据自由职业者的技能和专长,立即为你匹配到合适的人选。整个过程快速、流畅且高效。
-
任务管理:简化从任务列出到完成的整个流程,任务管理系统高效。
-
人才匹配:提供经过预筛选的人才,整合职位发布和人才匹配功能 。
-
-
-
投融资
AI编程助手领域投资热潮:Anysphere拟以100亿美元估值融资
随着AI编程助手的需求激增,Anysphere公司正在与风险资本家洽谈融资,目标是以近100亿美元的估值筹集资金。据彭博社报道,此轮融资将发生在Anysphere完成上轮1亿美元融资的三个月后,上一轮的融资估值为25亿美元,TechCrunch曾率先报道。预计此次融资将由回头投资人Thrive Capital主导。
Anysphere的上一轮融资时,公司年化经常性收入(ARR)为1亿美元,估值为其ARR的25倍,而如今该公司的ARR已攀升至1.5亿美元,按此计算,新一轮融资的估值将是其ARR的66倍。这一估值倍数远超投资者的普遍预期,凸显了AI编程领域的迅速扩张与高增长潜力。
除了Anysphere外,AI编程公司Codeium也在进行融资,估值接近30亿美元。据TechCrunch报道,Codeium的最新融资估值约为其年收入的70倍,Codeium背后的AI编程编辑器Windsurf已经获得Kleiner Perkins的投资。AI工具在编程领域的应用速度远超其他行业,包括销售、法律、医疗等,吸引了大量风险资本的关注。
此外,AI编程公司Poolside也在近期引起投资者的兴趣,该公司同样开发自有的大型语言模型(LLM)。尽管Poolside尚未回应采访请求,但其在AI编程领域的潜力已引起行业广泛关注。
总的来看,AI编程工具正成为风险投资的新宠,相关公司通过快速增长吸引了高估值,并且这一趋势很可能会在2025年继续延续。
https://techcrunch.com/2025/03/07/cursor-in-talks-to-raise-at-a-10b-valuation-as-ai-coding-sector-booms/
2025年初,美国AI行业继续显示出强劲的融资势头。截至目前,已有9家AI初创企业成功融资超过1亿美元,其中包括多个数亿级的大额融资。2024年,美国共有49家初创企业完成了价值超过1亿美元的融资,其中有三家公司筹集了两轮以上的超大规模融资,七家公司融资超过10亿美元。而在2025年初,这一趋势似乎并未减弱。
3月初,AI研究和大型语言模型公司Anthropic完成了35亿美元的E轮融资,估值达615亿美元,由Lightspeed领投,Salesforce Ventures、Menlo Ventures、General Catalyst等参与。2月,Together AI完成了3.05亿美元的B轮融资,估值33亿美元,融资由Prosperity7和General Catalyst联合领投,参与方包括Salesforce Ventures、Nvidia、Lux Capital等;Lambda获得了4.8亿美元的D轮融资,估值接近25亿美元,由SGW和Andra Capital共同领投,Nvidia、G Squared、ARK Invest等也参与其中。位于宾夕法尼亚州匹兹堡的Abridge在2月17日宣布了2.5亿美元的D轮融资,估值达27.5亿美元,IVP和Elad Gil领投,Lightspeed、Redpoint和Spark Capital等也参与了此次融资。
此外,AI法律技术公司Eudia在2月13日完成了1.05亿美元的A轮融资,由General Catalyst主导,Floodgate、Defy Ventures、Everywhere Ventures等也参与其中。AI硬件公司EnCharge AI也在同日宣布完成了1亿美元的B轮融资,由Tiger Global领投,Scout Ventures、Samsung Ventures和RTX Ventures等参与。Harvey,这家AI法律技术公司,在2月12日宣布完成了3亿美元的D轮融资,估值达到30亿美元,由Sequoia领投,OpenAI Startup Fund、Kleiner Perkins、Elad Gil等也参与了此轮融资。
1月,合成语音初创企业ElevenLabs完成了1.8亿美元的C轮融资,估值超过30亿美元,由ICONIQ Growth和Andreessen Horowitz共同领投,Sequoia、NEA、Salesforce Ventures等也参与其中。Hippocratic AI,这家专注于医疗行业的大型语言模型开发公司,在1月9日宣布完成了1.41亿美元的B轮融资,估值超过16亿美元,由Kleiner Perkins领投,Andreessen Horowitz、Nvidia和General Catalyst等也参与了此次融资。
2025年美国AI初创企业融资规模不断攀升,展示了AI行业的强劲增长势头,投资者对这一领域的兴趣与日俱增。
https://techcrunch.com/2025/03/08/9-us-ai-startups-have-raised-100m-or-more-in-2025/
— END —
快速获得3Blue1Brown教学动画?Archie分享:使用 Manim 引擎和 GPT-4o 将自然语言转换为数学动画
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43282.html