
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


信号
Region-Adaptive Sampling for Diffusion Transformers
本文提出了一种名为RAS的扩散模型采样策略,首次实现了在采样过程中对图像不同区域分配不同采样比例,显著提高了生成质量和效率。扩散模型(DMs)在图像合成、超分辨率、视频生成等众多领域表现出色,但其采样过程需要多次通过大型神经网络,限制了实时应用。现有加速方法虽能减少采样步数,但对图像所有区域进行统一处理,忽略了不同区域的复杂性差异。本文通过实验发现,扩散模型在相邻采样步中关注的区域具有高度连续性,且模型倾向于聚焦于图像中语义上有意义的区域。基于这一发现,RAS方法利用前一步的输出噪声识别当前步模型关注的重点区域(快更新区域),仅对这些区域进行DiT去噪处理,而对其他区域(慢更新区域)直接复用前一步的噪声输出。这种区域差异化采样方式减少了计算量,同时通过动态更新快区域选择和定期重置推理,确保全局一致性。实验表明,RAS在相同推理预算下显著提升了生成质量,与空间均匀采样器相比,大幅降低了推理成本且FID增加极小,在FVD指标上也优于均匀采样基线。在LuminaNext-T2I和Stable Diffusion 3等模型上,RAS实现了超过两倍的加速且图像质量损失可忽略。用户研究进一步显示,该方法在1.6倍加速率下仍能保持与均匀采样相当的生成质量。

研究节点:扩散模型
https://arxiv.org/abs/2502.10389
Diverse Inference and Verification for Advanced Reasoning
本文提出了一种通过多样化推理、测试时模拟与强化学习以及元学习代理图的方法,显著提升了推理型大语言模型(LLMs)在数学、编程和问题解决等领域的性能。研究在三个具有代表性和挑战性的基准测试中展示了多样化推理的优势:国际数学奥林匹克竞赛(IMO)组合问题、抽象与推理语料库(ARC)和人类最后的考试(HLE)。通过这些方法,IMO的准确率从33.3%提升至77.8%,ARC中人类未能解决的谜题解决了80%,HLE的准确率从8%提升至37%。
研究的三个关键方法贡献如下:
-
多样化推理:在测试时聚合多个模型、方法和代理,而非依赖单一模型或方法。对于IMO组合问题,使用八种不同方法(如LEAP、Z3等)显著提升准确率,并将英语问题自动形式化为Lean语言以实现完美验证;对于ARC,通过合成代码解决方案在训练样本上进行单元测试验证;对于HLE,使用最佳N选一作为不完美验证器,增加样本量可提升解题率。
-
测试时模拟与强化学习:在推理时生成额外问题特定信息。例如,在IMO中,将组合问题转化为互动游戏环境,并应用组合搜索或深度强化学习以得出部分结果或界限;在ARC中,通过合成代码探索谜题变换,修剪错误解并优化候选解。强化学习微调在这些任务中表现优于监督微调,因此研究在测试时运行模拟和强化学习,生成额外数据以正确证明IMO问题和解决复杂ARC谜题。
-
元学习代理图:使用LLMs和工具追踪流程运行,生成超参数、提示、代码变体和数据的A/B测试,并自适应修改代理图。
此外,研究还探讨了从专家混合到多样化模型和方法的演变。最近的语言模型大多采用专家混合架构,多个专家针对输入空间的不同方面进行训练,通过门控机制选择或加权专家。这种多样性使得模型能够使用广泛的解题策略,并更好地处理输入变化。研究通过多样化模型和方法提升准确率,而非依赖单一模型。
研究还讨论了完美和不完美验证器的使用。完美验证器不会产生假阳性结果,而假阳性结果会限制准确率的提升。在IMO和ARC中使用完美验证器,而在HLE中使用不完美验证器。例如,在IMO中使用Lean作为完美验证器,并通过模拟生成额外的真实样本;在ARC中使用代码执行作为完美验证器;在HLE中使用最佳N选一作为不完美验证器。
此外,研究识别了第三个经验性扩展法则:多样化模型和方法的数量与可验证问题性能之间的关系。这与模型大小、数据大小和损失之间的关系以及模型性能与测试时计算量之间的关系并列。
除了核心贡献和结果,研究还提供了方法论贡献和对这三个挑战性数据集的广泛评估。例如,在IMO中,研究提供了问题的视觉游戏表示,这些游戏求解器可以作为数学教育中的辅导工具,提供视觉解释、验证学生解决方案或提供个性化练习实例。在ARC中,研究对o3高计算量失败案例和948名人类集体失败案例进行了评估。在HLE中,研究按方法、问题类别和问题类型进行了评估。
最后,研究还讨论了三个基准测试的背景。IMO是面向高中生的全球性数学竞赛,涵盖代数、几何、数论和组合学等领域。ARC旨在通过视觉网格上的谜题模式衡量人工通用智能的视觉推理能力。HLE是一个包含3000个问题的基准测试,涵盖数十个学科领域,由全球专家开发。
未来工作将探索如何进一步优化多样化推理方法,并将其应用于更多领域和任务。

研究节点:模型推理
https://arxiv.org/abs/2502.09955
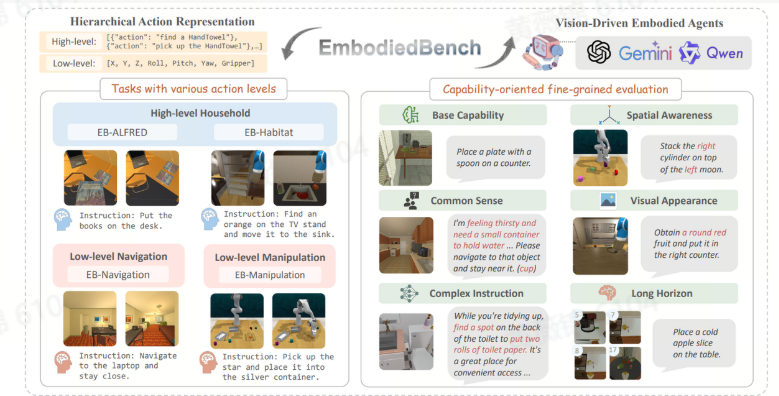
EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents
本文提出了一种用于评估多模态大型语言模型(MLLM)驱动的具身智能体的综合基准测试框架——EMBODIEDBENCH。该框架包含1,128个测试实例,覆盖四种环境,旨在填补现有基准测试在低层次任务(如导航和操作)评估方面的空白。EMBODIEDBENCH具有两大创新点:一是任务多样化且具有层次化的动作级别,既包含高层次任务分解与规划(如“将书放在桌子上”),也涵盖低层次动作规划(如平移/旋转控制);二是能力导向的评估方式,通过细粒度框架评估具身智能体的六项关键能力,包括基本任务解决、常识推理、复杂指令理解、空间感知、视觉感知和长时规划。
为便于评估MLLM作为具身智能体的表现,研究者设计了一个统一的智能体框架,整合了以自我为中心的视觉感知、少量样本上下文示例、交互历史和环境反馈等信息,以支持决策。基于该框架,研究者对13种领先的闭源MLLM(如GPT-4o、Gemini、Claude-3.5)和7B-90B参数量的开源模型(如Llama-3.2 Vision、InternVL 2.5、Qwen2-VL)进行了广泛评估。结果表明:MLLM在高层次任务中表现出色,但在低层次操作任务中表现欠佳;长时规划是最具挑战性的子任务;视觉输入对低层次任务至关重要,移除后性能下降40%-70%,而对高层次任务影响较小。此外,消融实验为MLLM智能体设计提供了实用见解,特别是在图像分辨率、多步图像输入和视觉上下文学习方面。
本文的贡献主要包括:提出了一套全面的MLLM具身智能体评估基准测试框架;开发了一种高效的MLLM智能体框架;通过广泛的评估和消融实验,为基于视觉的智能体设计提供了有价值的见解。
研究节点:模型评估
https://arxiv.org/abs/2502.09560
Direct Ascent Synthesis: Revealing Hidden Generative Capabilities in Discriminative Models
本文提出了Direct Ascent Synthesis(DAS)方法,挑战了传统机器学习中判别模型和生成模型的二分法。传统方法中,判别模型将输入映射到语义表示,而生成模型从潜在空间合成数据,但这些方法通常需要在大规模数据集上进行大量训练,引发了对复杂训练过程是否必要的质疑。
DAS的核心观点是,预训练的判别模型通过优化可以隐式地编码丰富的生成知识。然而,直接将判别模型的语义表示逆向映射为图像通常会产生无意义的噪声。这是因为优化过程虽然在数学上实现了表示的对齐,但忽略了人类视觉感知的质量。DAS的关键创新是通过多分辨率分解来打破这种退化现象。多尺度分解为优化过程提供了自然的正则化,符合人类视觉先验,避免了高频噪声解,同时允许对生成过程进行显式控制。
实验表明,DAS能够在无需任何生成训练的情况下生成高质量、语义上有意义的图像,仅需在单个GPU上进行秒级计算。这表明预训练的判别模型可能蕴含比之前认为的更丰富的生成能力。此外,DAS还揭示了对抗性样本与图像合成之间的意外联系。通常用于生成对抗性模式的优化过程,通过适当的正则化可以转向有意义的生成,这表明对抗性样本可能是优化过程忽略了自然图像结构的结果,而非判别模型的固有缺陷。
ASD在图像生成、可控修改、重建、风格迁移和修复等任务上进行了验证,结果表明,结合判别模型的表示和适当的优化先验,可以在不依赖传统生成训练的计算和数据需求的情况下实现高质量的合成。该研究不仅为生成任务提供了一种高效的新方法,还为理解深度神经网络中判别与生成之间的关系提供了新的视角。

研究节点:生成模型
https://arxiv.org/abs/2502.07753
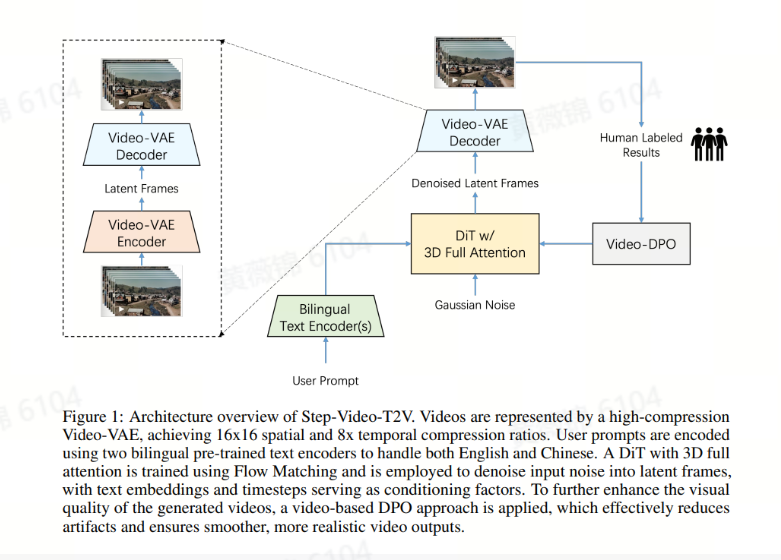
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model
本文介绍了一种名为Step-Video-T2V的先进视频生成模型,旨在通过高质量视频生成推动人工智能通用性(AGI)的发展。语言模型虽然在自然语言处理方面取得了显著进展,但其符号化的抽象性难以捕捉现实世界的复杂动态过程。因此,视频生成作为一种新兴技术,能够弥补这一差距,并为内容创作者降低创作门槛。
Step-Video-T2V是一个拥有300亿参数的扩散Transformer(DiT)基础模型,能够从文本生成高质量视频,具备强大的运动动态、高审美性和内容一致性。该模型通过深度压缩变分自编码器(VAE)实现16×16的空间压缩和8倍的时间压缩,显著降低了大规模视频生成的计算复杂度。此外,模型配备了双语文本编码器,支持中英文提示输入。
为了加速模型收敛并充分利用不同质量的视频数据集,Step-Video-T2V采用了级联训练流程,包括文本到图像预训练、文本到视频预训练、监督微调(SFT)和直接偏好优化(DPO)。这一流程不仅提升了模型的视觉质量,还减少了生成视频中的伪影。
在开发过程中,团队总结了关键经验:文本到图像预训练为模型提供了丰富的视觉知识基础;低分辨率的文本到视频预训练对学习运动动态至关重要;高质量视频和准确的字幕在SFT阶段对模型稳定性和生成风格有显著影响。
尽管取得了显著进展,Step-Video-T2V仍面临挑战,例如视频字幕模型的幻觉问题、低频概念组合的困难以及长时长、高分辨率视频生成的计算成本。为推动研究进展,团队开源了Step-Video-T2V,并创建了Step-Video-T2V-Eval基准数据集,包含128个多样化提示和多个开源及商业引擎的生成结果。
本文的主要贡献包括:开源Step-Video-T2V模型,提出深度压缩Video-VAE技术,优化模型超参数以提高训练效率,并发布新的基准数据集。这些成果为视频生成技术的发展提供了强有力的基线,并为未来研究指明了方向。
研究节点:视频模型
https://arxiv.org/abs/2502.10248
OWLS: Scaling Laws for Multilingual Speech Recognition and Translation Models
本文介绍了OWLS(Open Whisper-style Large-scale neural model Suite for Speech Recognition and Translation),一套开源的大型神经模型,用于语音识别(ASR)和语音翻译(ST)。OWLS包含13个基础模型,预训练了多达360K小时的多语言数据,覆盖150种语言,模型参数从0.25B到18B不等。研究重点在于模型和数据规模对下游ASR/ST性能的影响,并推导出针对这些任务的神经扩展规律。此外,通过上下文学习评估了大规模ASR/ST模型在测试时的能力,发现大模型在小模型中不存在的几种新能力。
论文的创新点和重点工作包括:首先,开源了13个Whisper风格的ASR/ST模型,这些模型基于公开数据训练,覆盖150种语言,最大模型参数达18B,是目前公开的ASR/ST模型中最大的规模,几乎是之前工作的两倍。其次,系统地评估了模型和数据规模对ASR和ST的影响,开发了针对这些任务的神经扩展规律,不仅衡量了模型规模的效用,还识别了其无法克服的失败案例。最后,通过上下文学习研究了大规模语音基础模型在测试时的能力,揭示了大模型中出现的新能力。

研究节点:ASR
https://arxiv.org/abs/2502.10373
HuggingFace&Github
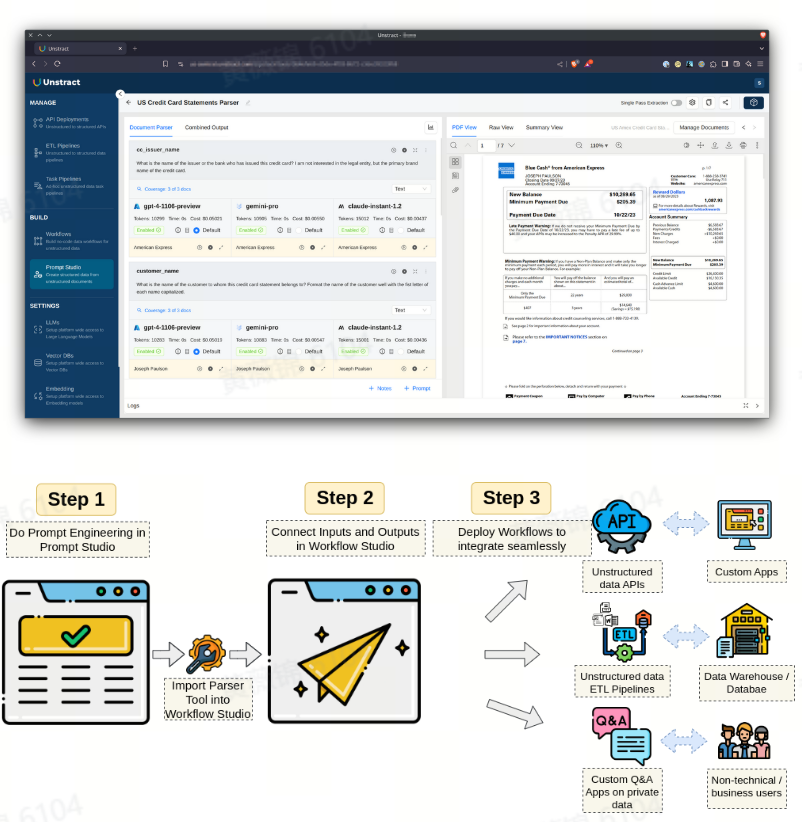
Unstract:智能文档处理 2.0 (IDP 2.0) 平台
Unstract 是一个开源的无代码平台,帮助你自动化处理复杂的业务流程,包括冗长,复杂文档任务。与现有的智能文档处理(IDP)和机器人流程自动化(RPA)系统相比,Unstract 利用最新的大语言模型,提供更强大的自动化能力。
自动化冗长、复杂文档的业务:
-
文档类型自定义与提示工程:通过 Prompt Studio(无代码环境),结合 LLM、矢量数据库和嵌入模型,监控字段提取率和文档提示成功率。
-
连接存储与数据目标:从不同存储系统中提取非结构化文档,将结构化数据发送到数据平台。
-
部署工作流:非结构化API ,ETL 管道,构建自定义问答应用。
https://github.com/Zipstack/unstract
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/38600.html