我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
非常感谢一直以来大家对101文档、llmspace公众号、小红书大模型空间站的喜爱与支持~为了进一步打造高质量的AI社媒账号并且帮助大家链接资源,我们欢迎大家花1分钟来填写【反馈问卷】,一起打造更优质的AI交流平台!
信号 OpenAI Model Spec 这是是OpenAI 2月12日发布的一份重要文档,旨在明确AI模型的行为规范,以确保人工智能(AGI)能够造福全人类。OpenAI的使命是确保AGI的益处能够惠及所有人。AGI被定义为能够在多个领域以人类水平解决复杂问题的系统。AGI是人类进步的延续,类似于电力、计算机和互联网等重大技术突破。
最大化用户自主性:AI助手应当是一个工具,旨在赋能用户和开发者,尽可能满足他们的需求。
最小化伤害:AI系统可能带来潜在的伤害风险,因此需要制定规则来降低这些风险。
选择合理的默认设置:模型规范包括平台级和用户级的默认设置,这些设置可以根据具体情况进行覆盖。
目标不一致:模型可能误解用户意图,导致追求错误目标。
执行错误:模型理解任务但在执行中出错,可能造成严重后果。
有害指令:模型可能因遵循用户指令而造成伤害,这需要在赋能用户与防止伤害之间找到平衡。
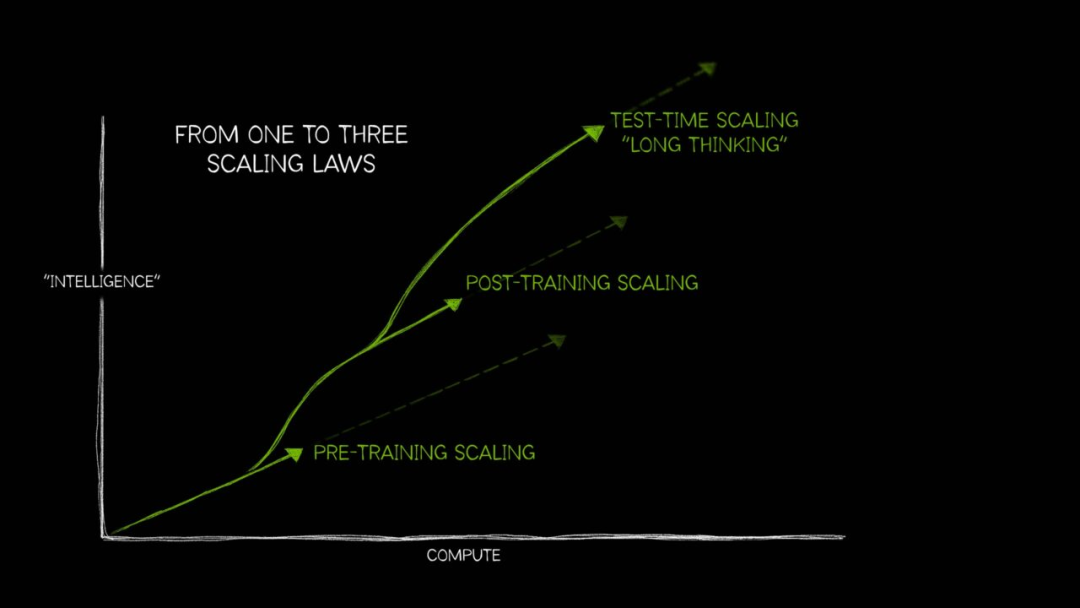
模型规范为每条指令分配了权威层级,以帮助模型在复杂场景中处理目标冲突。权威层级从高到低依次为平台级、开发者级、用户级和指南级。高权威的指令将覆盖低权威的指令。 文档提到,AGI的影响将是不均衡的,某些行业可能变化不大,而科学进步可能会显著加快。确保AGI的收益广泛分配是至关重要的,OpenAI将继续探索如何在安全与个体赋权之间找到平衡。 原文链接:https://model-spec.openai.com/2025-02-12.html#overview How Scaling Laws Drive Smarter, More Powerful AI 本文探讨了AI领域中的三种扩展定律:预训练扩展、后训练扩展和测试时扩展(也称为长思考),并分析了它们如何推动AI模型变得更智能、更强大。 预训练扩展是AI发展的基础定律,表明通过增加训练数据集规模、模型参数数量和计算资源,可以提升模型的智能水平和准确性。这三者相互关联,更大的模型需要更多的数据和计算资源来实现性能提升。这一原理推动了大规模模型的出现,如数十亿甚至万亿参数的Transformer模型和混合专家模型等,同时也催生了新的分布式训练技术。随着人类产生越来越多的多模态数据,预训练扩展定律将继续发挥作用,为未来的AI模型提供训练基础。 后训练扩展关注的是在预训练模型的基础上进行进一步的优化和适应性调整。预训练一个大型基础模型需要大量的投资和专业知识,但一旦完成,其他组织可以利用这些预训练模型作为基础,通过微调、剪枝、量化、蒸馏、强化学习和合成数据增强等技术,针对特定的领域和应用场景进行定制化训练,从而提高模型在特定任务上的效率、准确性和领域相关性。这一过程会带来额外的计算需求,开发衍生模型的计算量可能是预训练原始基础模型的30倍左右。 测试时扩展或长思考,是近年来兴起的一种技术,它在推理阶段应用更多的计算资源来提高模型的准确性。与传统AI模型快速生成单一答案不同,测试时扩展允许模型在推理时进行多次推理,通过探索不同的解决方案来找到最佳答案。这种方法特别适用于处理复杂问题,如生成复杂的定制代码或进行多步骤的推理任务。测试时扩展的计算需求可能比传统LLM的单次推理高出100倍以上,但它能够使模型更好地处理复杂、开放式的用户查询,为用户提供更合理、准确的回答。
原文链接: https://blogs.nvidia.com/blog/ai-scaling-laws/?ncid=so-twit-910081&linkId=100000338838010 Three Observations 这篇文章是由Sam Altman撰写的博客,探讨了人工智能(AI)特别是通用人工智能(AGI)的发展趋势及其对社会经济的潜在影响。以下是他的观点:AGI被定义为能够以人类水平解决多个领域中日益复杂问题的系统,被视为人类进步的延续,类似于电力、晶体管、计算机和互联网等重大发明。AI发展的三个观察论断:
AI模型的智能与训练资源成对数关系:通过投入更多的资源,可以实现持续且可预测的性能提升,且这种提升在多个数量级上都是准确的。
AI使用成本的快速下降:使用特定水平AI的成本大约每12个月下降10倍,这种下降速度远超摩尔定律(每18个月性能翻倍),而更低的价格会显著增加其使用量。
线性增加的智能带来的超指数增长价值:我们认为没有理由在短期内停止投资的指数级增长。
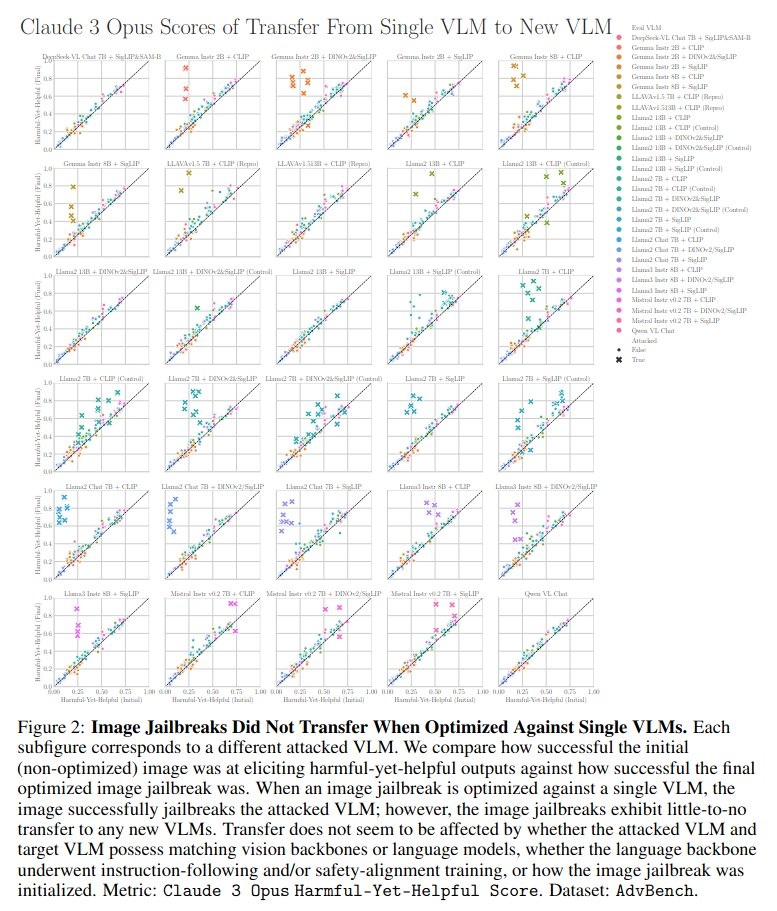
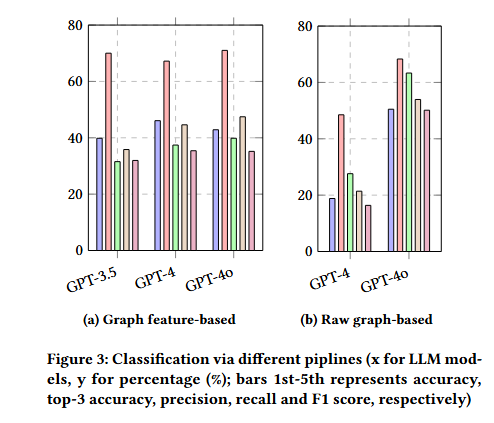
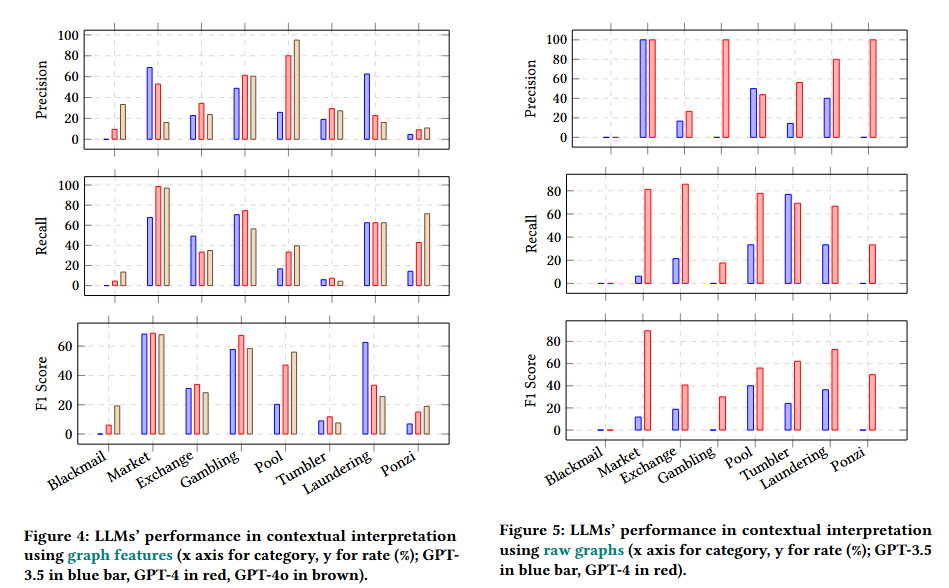
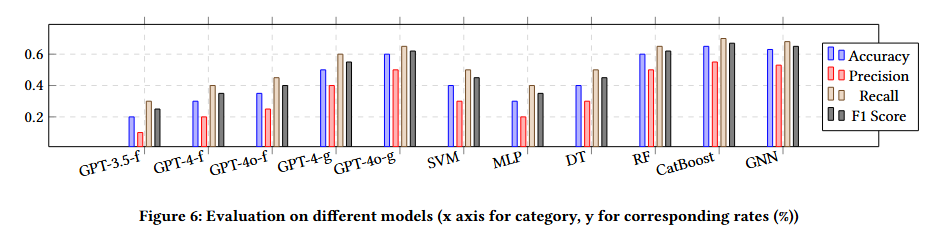
文章认为agent将会大大改变人类的工作和生活。短期内,人们的生活方式不会发生巨大变化,但长期来看,AI将带来巨大的变化。人们将找到新的方式来相互帮助和竞争,但这些方式可能与今天的工作大不相同。个体的决策能力、适应性和韧性将成为重要的技能。AGI将极大地增强人类的意志力,使个体能够产生比以往更大的影响。 文章最后提到AGI的影响将是不均衡的。虽然某些行业可能变化不大,但科学进步可能会比今天快得多。许多商品的价格最终可能会大幅下降,而奢侈品和土地等有限资源的价格可能会大幅上升。技术上,未来的道路相对清晰,但公共政策和集体意见在如何将AGI整合到社会中起着重要作用。 原文链接:https://arxiv.org/abs/2412.16145 Large Language Models for Cryptocurrency Transaction Analysis:A Bitcoin Case Study 加密货币分析的挑战在于当前黑盒模型的不透明性和不灵活性,阻碍了对交易行为的有效理解。本文提出了一个三层框架来评估 LLM 在比特币交易图上的分析能力。该框架使用一种新的图形表示格式和一种采样算法来增强 LLM 输入。级别包括基础指标、特征概述和上下文解释。提出了一种称为 LLM4TG 的新的人性化图形表示格式LLM4TG 。在保持数据完整性的同时最大限度地减少了冗余和令牌使用。它按类型分层组织节点,并集成节点内的边缘细节。为了在 LLM 令牌限制内处理大型图,引入了连接增强事务图采样 (CETraS) 算法。CETraS 根据节点重要性指标删除不太重要的节点,同时保留关键连接,从而压缩图。LLM 在理解基础图指标方面表现出强大的能力。它们准确地提取节点级信息,如度数和交易值。尤其是 GPT-4o,有效地提供了交易图的特征概述。它们识别与分析相关的关键特征和模式。即使标记示例有限,LLM 在地址分类等任务的上下文解释方面也显示出良好的前景。 在基础指标评估中,LLM 在节点级指标识别方面的准确率达到了 98.50% 到 100.00%。全局度量准确率范围为 24.00% 至 58.00%。→ 对于特征概述,GPT-4o 实现了 95% 的有意义响应率,而 GPT-4 为 70%。→ 在基于原始图形的分类中,GPT-4o 实现了 50.49% 的整体准确率,明显优于 GPT-4 的 18.81%。→ GPT-4o 在原始图形分类中的准确率达到 63.33%,召回率为 53.95%,F1 分数达到 50.14%。
信号源:Monash University
原文链接:https://arxiv.org/pdf/2501.18158
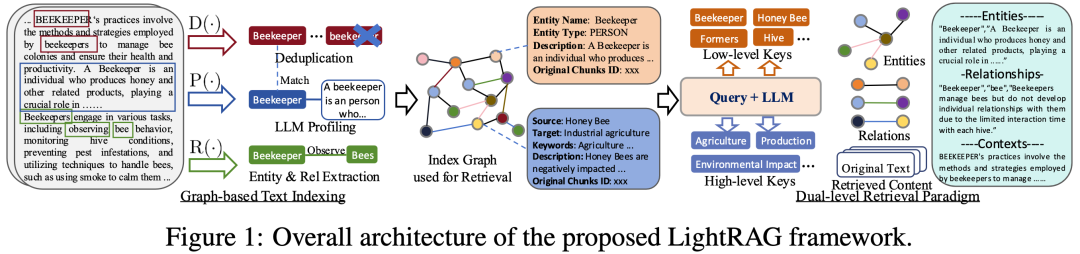
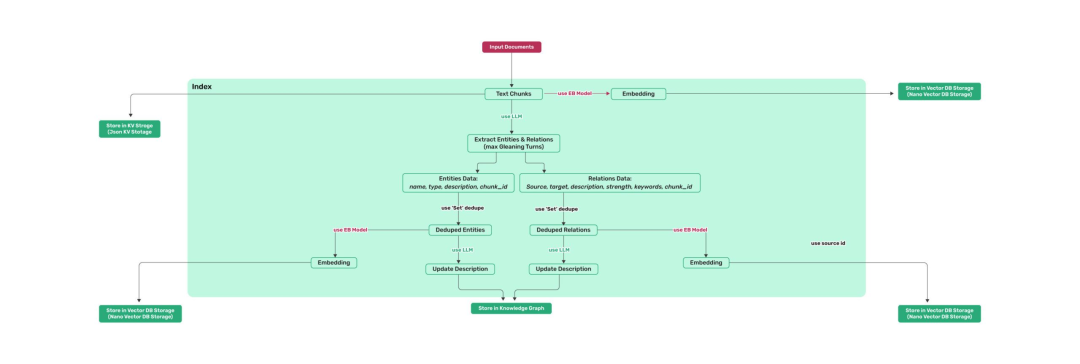
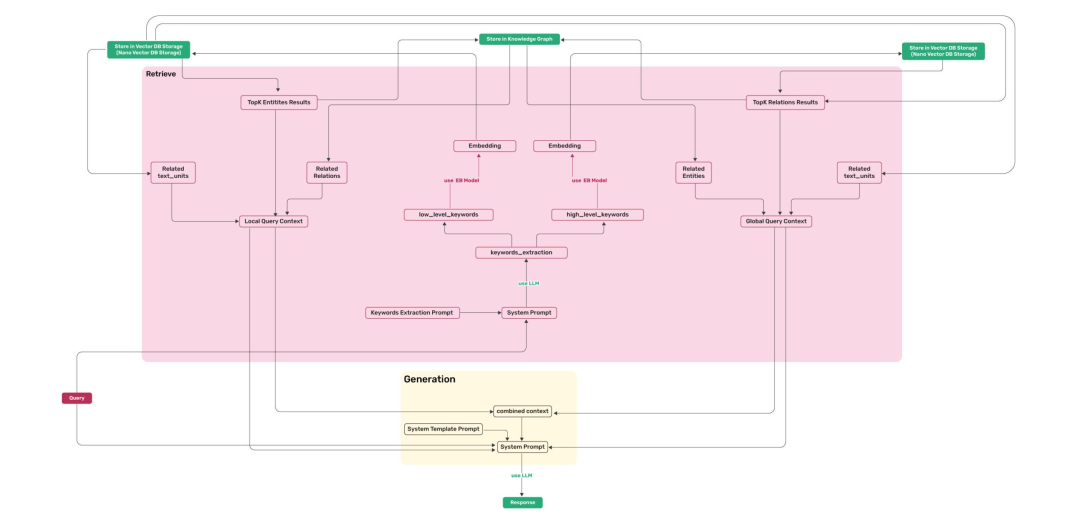
LIGHTRAG: SIMPLE AND FAST RETRIEVAL-AUGMENTED GENERATION LightRAG是一个开源的检索增强型生成(Retrieval-Augmented Generation, RAG)系统,由香港大学数据科学实验室(HKUDS)开发,旨在提供简单且高效的文本生成解决方案。它基于nano-graphrag构建,支持多种功能,包括多文件类型支持(如PDF、DOC、PPT和CSV)、批量插入、增量插入、知识图谱可视化和自定义知识图谱插入等。
检索增强生成:结合知识图谱和向量检索技术,提供更准确和丰富的文本生成结果。
灵活的存储选项:支持多种存储后端,如Neo4J、PostgreSQL和Faiss,适用于不同的生产环境需求。
多模型支持:支持OpenAI、Hugging Face和Ollama等多种语言模型,用户可以根据需求选择合适的模型。
对话历史和自定义提示支持:支持多轮对话和自定义提示,以适应不同的应用场景。 性能优化:通过批量处理和增量插入等功能优化内存使用和处理速度。
信号源:University of Hong Kong 原文链接:https://arxiv.org/pdf/2410.05779 项目地址:https://github.com/HKUDS/LightRAG
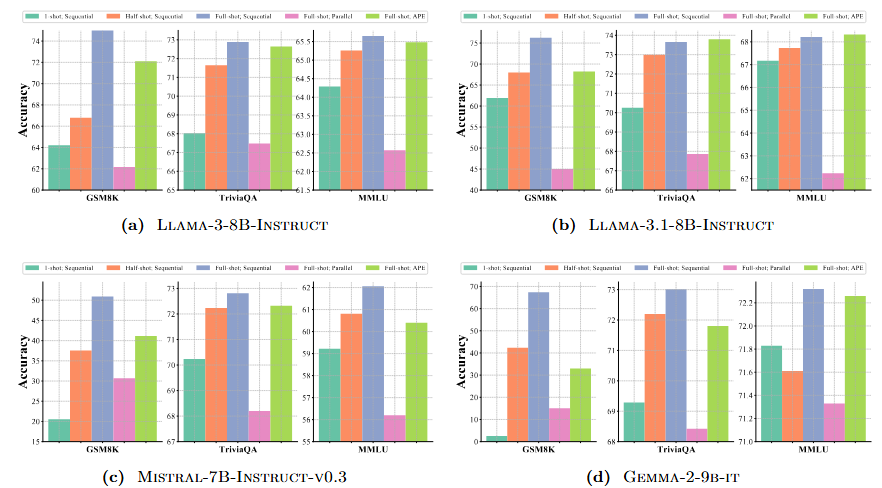
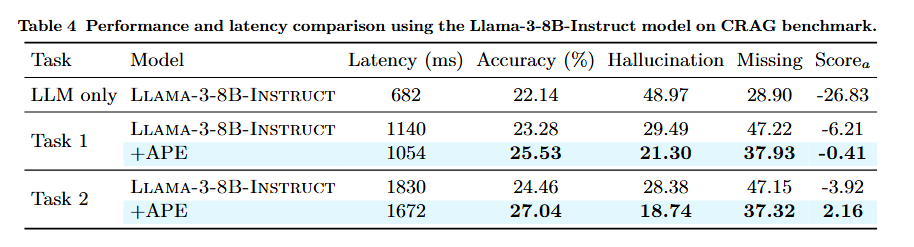
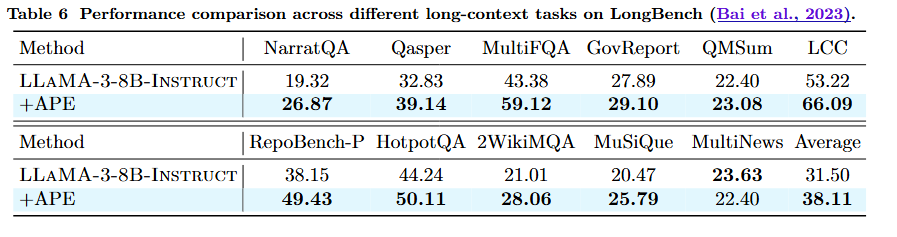
APE: Faster and Longer Context-Augmented Generation via Adaptive Parallel Encoding 本文介绍了一种名为 Adaptive Parallel Encoding (APE) 的方法,旨在通过并行编码技术提升上下文增强生成(Context-Augmented Generation, CAG)任务的效率和性能。CAG 技术如检索增强生成(RAG)和上下文学习(ICL)需要高效地结合多个上下文来生成对用户查询的响应,但传统的序列编码方法在处理长输入时存在效率瓶颈。APE 通过独立预计算和缓存每个上下文的键值(KV)状态,避免了在每次请求时重新编码,从而显著提高了效率。然而,直接应用并行编码会导致性能下降,APE 通过引入共享前缀、注意力温度调整和缩放因子来对齐并行编码与序列编码的分布,从而解决了这一问题。 实验结果表明,APE 在 RAG 和 ICL 任务中分别保留了 98% 和 93% 的序列编码性能,同时比并行编码分别提高了 3.6% 和 7.9%。此外,APE 能够扩展到多轮 CAG 任务,有效并行处理数百个上下文,并在长上下文生成中实现高达 4.5 倍的速度提升,显著减少了预填充时间。 文章还详细分析了 APE 的各个组成部分对性能的贡献,并通过实验验证了 APE 在实际应用中的有效性,包括在长上下文理解和多轮对话问答任务中的表现。APE 的提出为 CAG 任务提供了一种高效且准确的解决方案,尤其适用于需要处理大量上下文信息的场景。 信号源:Carnegie Mellon University & Nvidia 原文链接:https://arxiv.org/pdf/2502.05431 项目地址:https://github.com/Infini-AI-Lab/APE
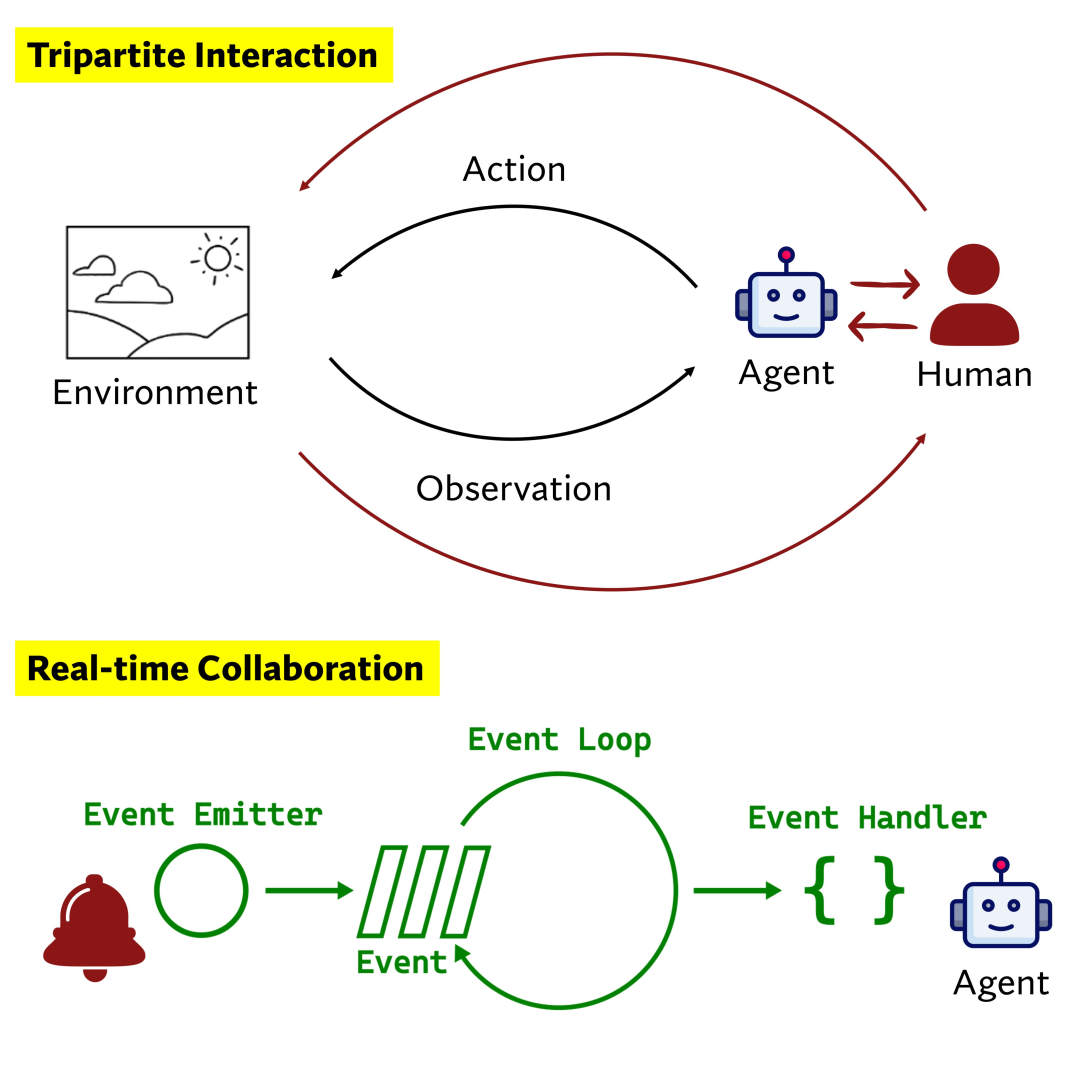
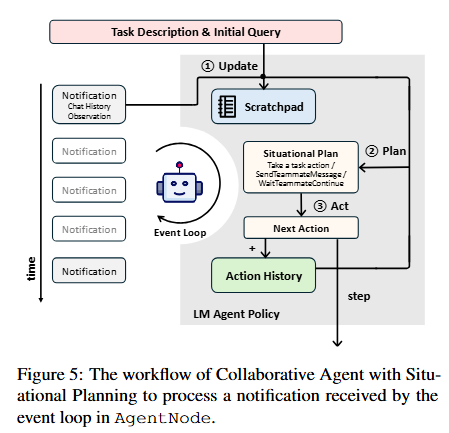
Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration 本文介绍了Collaborative Gym(Co-Gym),这是一个用于促进和评估人类与语言模型(LM)代理协作的框架。Co-Gym支持异步的三方交互,包括代理、人类和任务环境,并提出了一个综合评估框架,用于衡量协作的结果和过程。研究发现,协作代理在任务表现上优于完全自主的代理,但在通信能力、情境意识和平衡自主性与人类控制方面仍面临挑战。
Co-Gym框架:Co-Gym通过定义一个环境接口,允许人类和代理在共享工作空间中交互。它支持异步交互,允许双方根据需要采取行动,而不是强制轮流操作。此外,Co-Gym还引入了协作行为(如发送消息和等待对方继续)和通知协议,以支持实时变更监控。
任务环境:Co-Gym支持三种代表性任务——旅行规划、撰写相关工作部分和表格分析,这些任务在模拟和真实条件下进行实验。
评估框架:Co-Gym从任务结果和协作过程两个维度评估协作代理,包括交付率、任务表现、协作得分、主动性、受控自主性和人类满意度等指标。
协作优势:在模拟和真实条件下,协作代理在任务表现上均优于完全自主代理,例如在旅行规划任务中,协作代理的胜率达到86%。
协作过程:协作代理在通信、情境意识和规划方面表现出挑战,尤其是在真实条件下。例如,代理在通信方面的问题(如忽略人类消息或重复提问)是导致协作失败的主要原因之一。
人类满意度:在真实条件下,人类对协作过程的满意度因任务而异,其中表格分析任务的满意度最高(平均评分4.06),而撰写相关工作部分的任务满意度较低(平均评分3.06)。
Co-Gym为研究人类与LM代理协作提供了一个通用框架,揭示了协作代理的潜力和挑战,为未来的研究和开发提供了方向。
研究的局限性在于任务类型的有限性、模拟条件的局限性以及真实条件下人类参与者的数量和多样性不足。未来的研究需要扩展任务类型,改进模拟条件以更好地指导代理开发,并在更广泛的人群中验证Co-Gym的有效性。
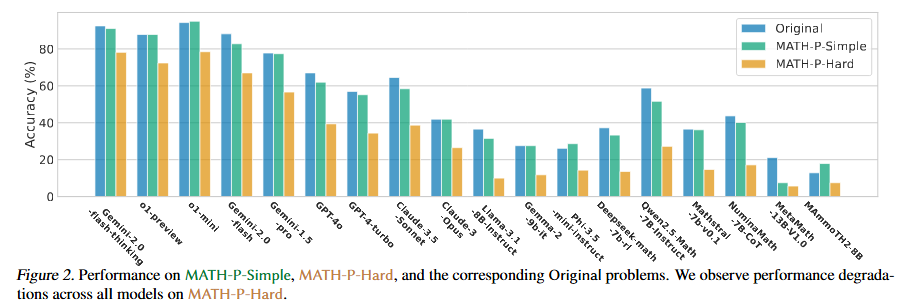
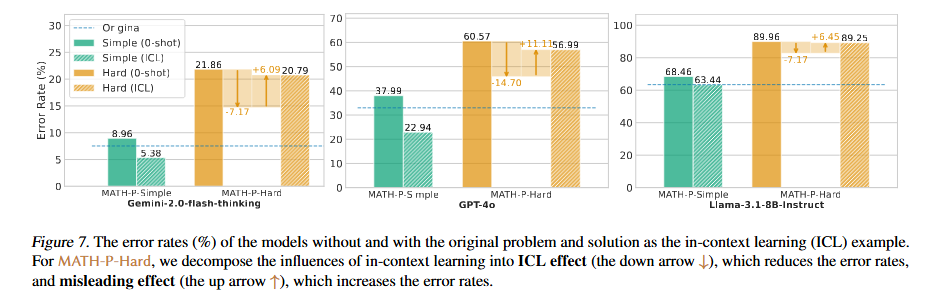
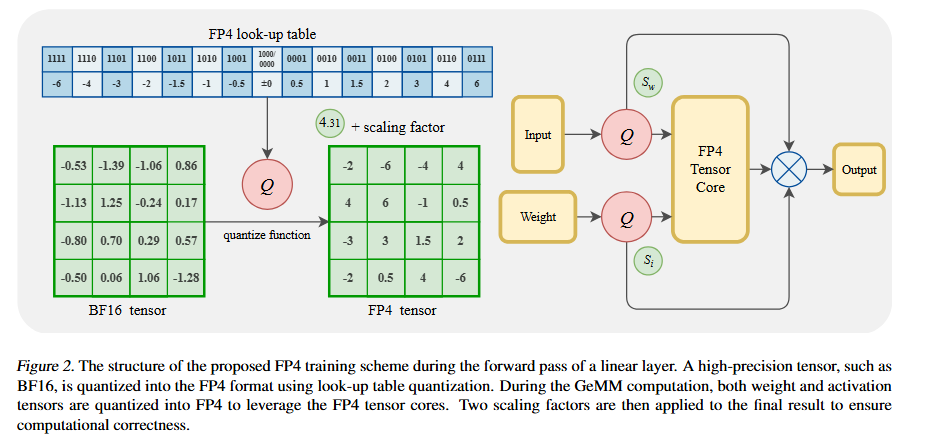
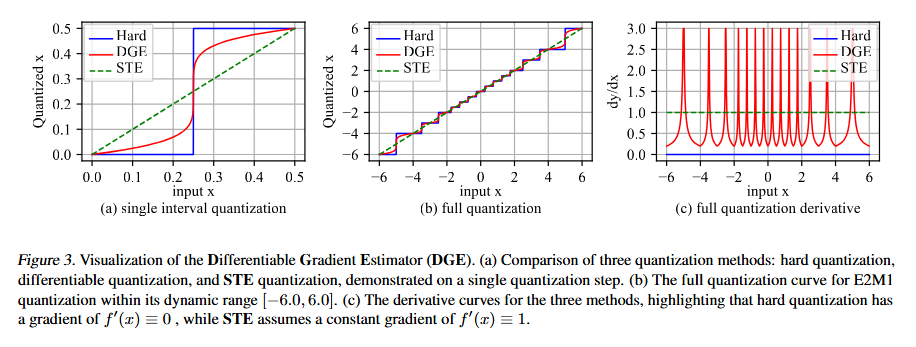
原文链接:https://arxiv.org/abs/2412.15701 MATH-Perturb: Benchmarking LLMs’ Math Reasoning Abilitiesagainst Hard Perturbations 本文介绍了MATH-Perturb基准测试,旨在评估大型语言模型(LLMs)在面对数学问题的复杂扰动时的推理能力。研究者们构建了MATH-P-Simple和MATH-P-Hard两个数据集,分别包含279个经过简单扰动和复杂扰动的数学问题,这些问题均源自MATH数据集的5级(最困难)问题。实验结果表明,所有模型在MATH-P-Hard上的性能显著下降,例如o1-mini下降了16.49%,gemini-2.0flash-thinking下降了12.9%。研究还发现,模型在面对复杂扰动时,存在一种新型的“记忆化”问题,即模型盲目应用训练中学到的解题技巧,而不评估这些技巧在修改后的情境中的适用性。此外,研究还探讨了使用原始问题进行上下文学习(ICL)的影响,发现ICL可能会误导模型,导致在MATH-P-Hard上的表现更差。本文的研究结果表明,开发更健壮、可靠的推理模型需要解决模型在面对复杂扰动时的泛化能力问题。 信号源:Princeton University & Google 原文链接:https://arxiv.org/pdf/2502.06453 Optimizing Large Language Model Training Using FP4 Quantization 本文提出了一种针对大型语言模型(LLMs)的FP4量化训练框架,旨在通过低比特运算降低训练成本。研究者们通过两项关键创新解决了FP4训练中的挑战:一是可微量化估计器,用于精确更新权重;二是异常值钳制与补偿策略,防止激活值坍缩。实验表明,该框架在13B参数的LLMs上实现了与BF16和FP8相当的准确率,且在100B tokens的训练规模下性能几乎无损。随着支持FP4的新一代硬件的出现,该框架为超低精度训练奠定了基础。 研究背景方面,LLMs的训练需要大量计算资源,而量化训练是一种有效的解决方案。尽管FP8精度已被证明可行,但FP4的使用仍面临量化误差大和表示能力有限的问题。本文的FP4训练框架通过混合精度训练方案和向量量化技术确保稳定性,并在多种模型规模下验证了其有效性。在方法论上,研究者们针对权重和激活值分别提出了不同的量化策略。对于权重,提出了可微量化估计器(DGE),通过分析量化对神经网络前向和反向传播的影响,推导出用于准确梯度估计的校正函数。对于激活值,开发了异常值钳制与补偿策略(OCC),通过分析LLMs中激活值的分布,引入钳制方法和稀疏辅助矩阵来保持量化精度并维持模型性能。实验结果表明,FP4框架在不同模型规模下均实现了与BF16相当的训练损失,并且在下游任务的零样本评估中表现出与BF16模型相媲美的性能。此外,通过在Nvidia H100 GPU上使用FP8张量核心模拟FP4计算,研究者们成功训练了多达13B参数的LLMs,并处理了高达100B的训练tokens。研究者们还进行了消融研究,证明了DGE和OCC方法的有效性,并探讨了量化粒度对训练性能的影响。 信号源:University of Science and Technology of China & Microsoft 原文链接:https://arxiv.org/abs/2501.17116
HuggingFace&Github
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
DeepScaleR-1.5B-Preview:R1 1.5B微调模型 DeepScaleR-1.5B-Preview 是经过 分布式强化学习(RL) 微调的语言模型,基于 DeepSeek-R1-Distilled-Qwen-1.5B 优化以适应长上下文长度。该模型在 AIME 2024 上实现 43.1% 的 Pass@1 准确率,相比基础模型准确率提升了 15%,在 1.5B 参数下超越了 OpenAI O1-Preview。
在模型逐步提高的过程中使用越来越长的上下文,节省成本并减少端到端训练时间
https://huggingface.co/agentica-org/DeepScaleR-1.5B-Preview
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
OpenR1-Math-220k 数据集:大规模数学推理数据集 OpenR1-Math-220k 是一个大型的数学推理数据集,包含了来自 NuminaMath 1.5 的 220K 道数学题,且每道题目有两到四个推理过程,这些推理过程是通过 DeepSeek R1 生成的。 其中大多数样本的推理过程已通过 Math Verify 验证,而12%的样本则由 Llama-3.3-70B-Instruct 作为判定工具验证。每道题目至少包含一个正确答案的推理过程。
默认子集:包含 94K 题目,在 SFT(微调)后表现最佳。 扩展子集:包含 131K 题目,加入了如 cn_k12 等数据源。这个子集提供了更多的推理过程,但经过 SFT 处理后的性能不如默认子集,可能是因为来自 cn_k12 的问题相较其他数据源来说难度较低。 Open-R1 是一项开源项目,旨在以完全透明和协作的方式复制和扩展DeepSeek-R1 背后的技术。
https://huggingface.co/datasets/open-r1/OpenR1-Math-220k
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/38210.html