我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
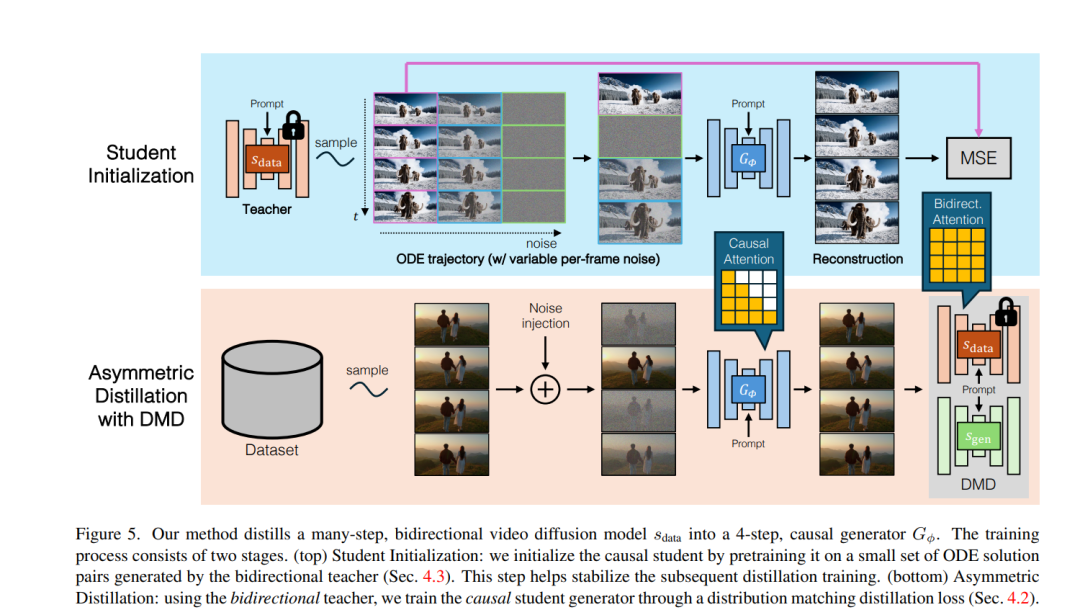
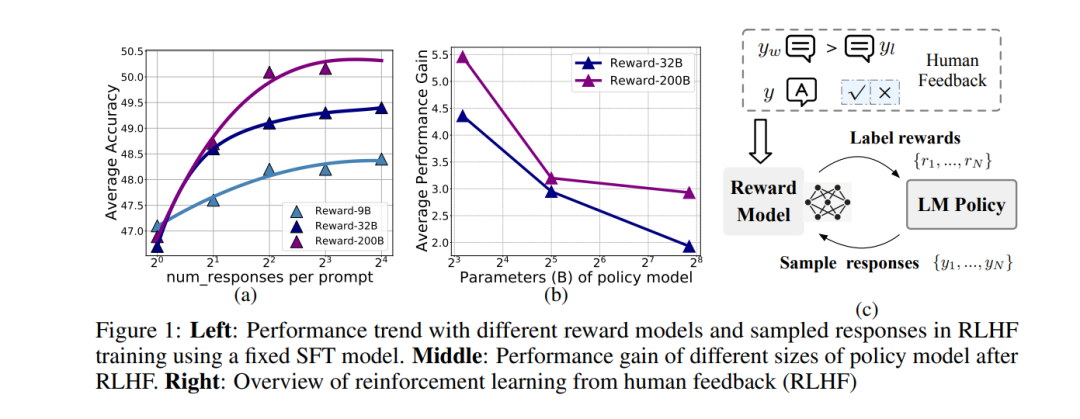
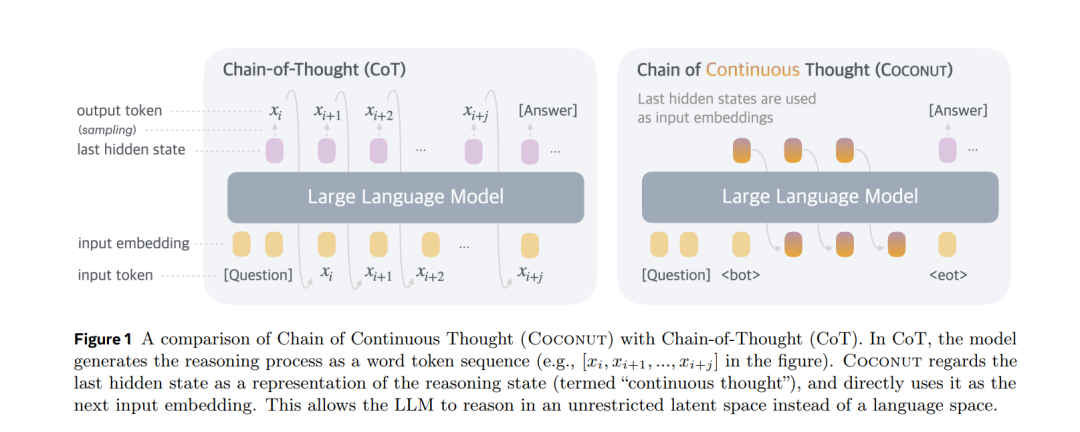
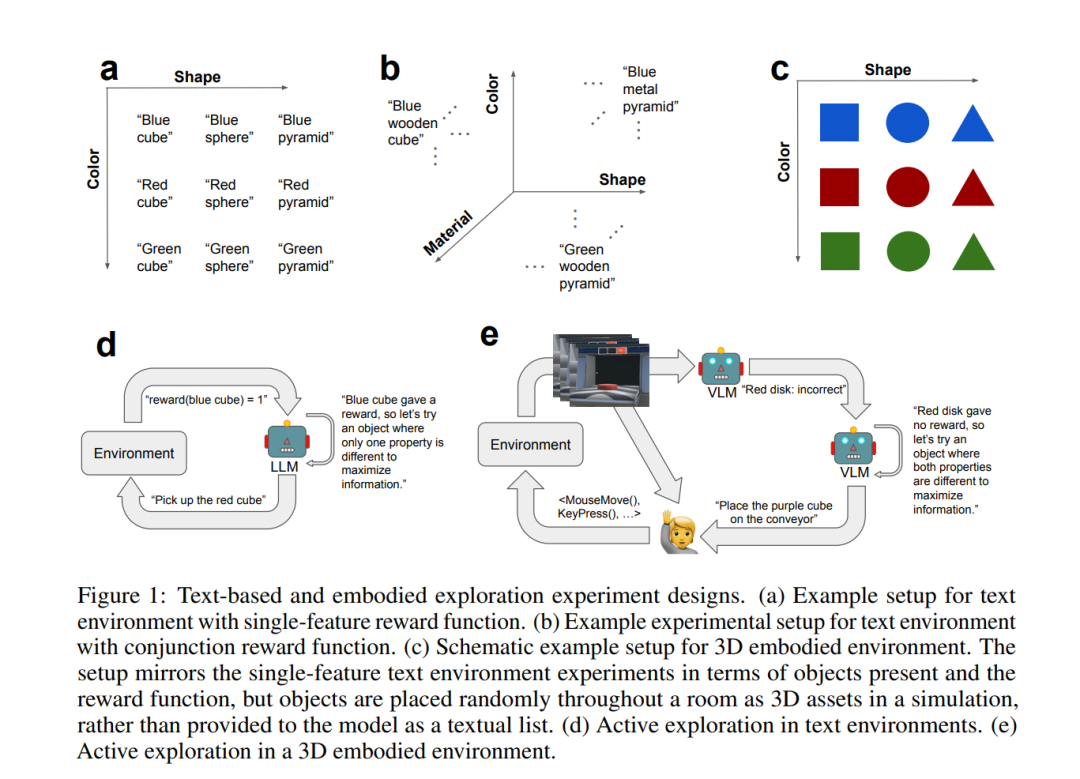
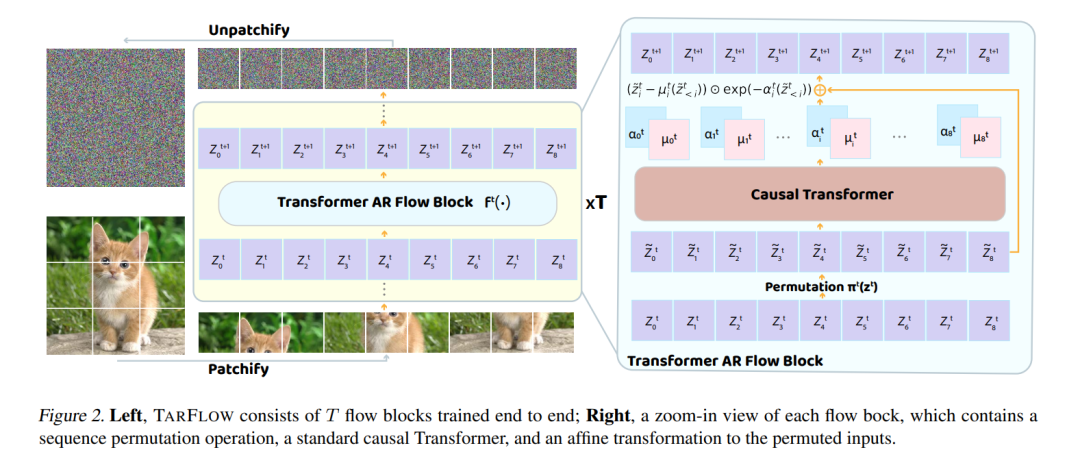
信号 From Slow Bidirectional to Fast Causal Video Generators 当前的视频扩散模型在生成质量上取得了令人印象深刻的成果,但由于双向注意力依赖,它们在交互式应用中存在困难。生成单帧图像需要模型处理整个序列,包括未来的帧。我们通过将预训练的双向扩散变换器(diffusion transformer)调整为因果变换器(causal transformer)来解决这一限制,使得模型可以即时生成每一帧。 为了进一步降低延迟,我们将分布匹配蒸馏(DMD)扩展到视频上,将50步的扩散模型蒸馏成一个仅需4步的生成器。为了实现稳定且高质量的蒸馏,我们引入了一种基于教师模型的常微分方程(ODE)轨迹的学生初始化方案,并提出了一种不对称蒸馏策略,使用双向教师模型监督因果学生模型。这种方法有效减缓了自回归生成中的误差积累,使得尽管训练时使用的是短片段,模型仍能够进行长时段视频合成。 我们的模型支持在单个GPU上以9.4帧每秒的速度进行高质量视频的快速流媒体生成,得益于KV缓存。我们的方法还支持零-shot的流媒体视频到视频翻译、图像到视频生成和动态提示。未来我们将基于开源模型发布代码。 https://arxiv.org/abs/2412.07772 Does RLHF Scale? Exploring the Impacts From Data, Model, and Method 本研究探讨了基于人类反馈的强化学习(RLHF)在大语言模型(LLMs)中的扩展性。尽管RLHF被认为是LLM后期训练中的一个重要步骤,但其扩展潜力仍然在很大程度上未知。我们系统地分析了RLHF框架中的关键组成部分——模型大小、数据组成和推理预算——以及它们对性能的影响。我们的研究结果表明,增加数据的多样性和量化有助于奖励模型的性能提升,帮助处理监督模型更好地扩展。 对于策略训练,增加每个提示的响应样本数最初能提高性能,但很快会达到平台期。而较大的奖励模型对策略训练的提升作用较为有限。此外,对于固定奖励模型的较大策略模型,RLHF带来的收益较小。总体而言,RLHF的扩展效率低于预训练,并且额外的计算资源带来的回报递减。 基于这些观察结果,我们提出了一些策略,用于在计算资源限制下优化RLHF的性能。这些策略旨在提高RLHF在不同模型规模和数据条件下的效率,最大化其潜力,同时避免资源浪费。 https://arxiv.org/abs/2412.06000 Training Large Language Models to Reason in a Continuous Latent Space 大语言模型(LLMs)的推理能力通常局限于“语言空间”,即通过“链式思维”(Chain-of-Thought, CoT)表达推理过程,以解决复杂的推理问题。然而,我们认为语言空间并非总是推理的最优选择。例如,大多数单词标记主要用于文本连贯性,而非推理所必需;而一些关键标记则需要复杂的规划,对LLMs构成巨大的挑战。 为探索LLMs在不受限制的潜在空间中进行推理的潜力,我们引入了一种新的范式Coconut(Chain of Continuous Thought)。在这一框架中,我们利用LLM的最后隐藏状态作为推理状态的表示(称为“连续思维”)。与其将其解码为单词标记,不如直接将其作为连续空间中的后续输入嵌入反馈给LLM。 实验表明,Coconut可以有效增强LLM在多个推理任务上的表现。这种新颖的潜在推理范式引发了高级推理模式的涌现:连续思维能够编码多个可能的下一步推理步骤,使模型能够通过广度优先搜索(BFS)解决问题,而不是像CoT那样过早地固定在单一的确定性路径上。 在需要大量回溯的逻辑推理任务中,Coconut相较于CoT表现更优,同时在推理过程中使用了更少的“思维标记”。这些研究结果展示了潜在推理的潜力,并为未来的研究提供了宝贵的见解。 https://arxiv.org/abs/2412.06769 Flow Matching Guide and Code FM是一种生成建模框架,通过学习速度场(向量场)来实现样本的转换。每个速度场通过常微分方程(ODE)定义一个流,将源分布p中的样本X₀变换为符合目标分布q的样本X₁。最初,流模型通过最大化训练样本的似然来进行训练,但由于计算负担较重,后续研究提出了无仿真训练的流匹配算法,成为现代流匹配方法的基础。 流匹配的基本步骤包括:选择一个在源分布p和目标分布q之间插值的概率路径pₜ,随后训练一个速度场(神经网络)来定义流变换ψₜ,实现该路径。流匹配不仅适用于欧几里得空间,还可以扩展到其他状态空间,甚至是非流的演化过程。近期,离散流匹配和黎曼流匹配分别扩展了流匹配算法,适用于离散时间马尔可夫链(CTMC)和黎曼流形上的流,广泛应用于语言建模和蛋白质折叠等领域。 生成器匹配(GM)进一步推广了流匹配框架,允许在任意模态和连续时间马尔可夫过程(CTMP)中使用,统一了各种生成模型的设计。流匹配框架还与扩散模型(Diffusion Models)有着紧密的关系,后者通过前向噪声过程构建概率路径,并利用得分函数实现生成器的参数化。 本文接下来的结构包括:第二部分提供了流匹配的快速实现指南;第三部分深入探讨了流模型;第四部分详细介绍了流匹配框架及其设计;第五部分讨论了流匹配在黎曼几何中的扩展;第六至第八部分介绍了流匹配在离散和连续时间马尔可夫链上的应用;第九部分介绍了生成器匹配,最后,第十部分探讨了扩散模型与流匹配的关系。 https://arxiv.org/abs/2412.06264 Can foundation models actively gather information in interactive environments to test hypotheses? 尽管问题解决是基础模型的标准评估任务,但问题解决中的一个关键组成部分——主动且策略性地收集信息以验证假设——尚未被充分研究。为了评估基础模型在互动环境中的信息收集能力,我们提出了一个框架,其中模型必须通过迭代推理其先前收集的信息,并提出下一步的探索性行动,以最大化每一步的信息增益,从而确定影响隐藏奖励函数的因素。我们在两种环境中实现了该框架:一种是文本环境,提供了一个严格控制的设置,便于高通量的参数扫描;另一种是具身3D环境,要求解决多模态交互的复杂性,更贴近实际应用。 我们进一步探讨了自我纠正和增加推理时间等方法是否能够提高信息收集的效率。在一个相对简单的任务中,要求识别单一奖励特征,我们发现Gemini的收集信息能力接近最优。然而,当模型需要识别多个奖励特征的联合时,表现则不尽如人意。性能下降的部分原因在于模型将任务描述转化为策略的过程以及模型在使用上下文记忆中的有效性。无论是在文本环境还是3D具身环境中,性能表现相当,尽管在3D具身环境中,由于视觉物体识别的不完美,模型在从收集的信息中得出结论时的准确性有所下降。对于基于单一特征的奖励,我们发现较小的模型表现出奇地更好;对于基于特征联合的奖励,将自我纠正机制融入模型中有助于提升性能。 https://arxiv.org/abs/2412.06438 Normalizing Flows are Capable Generative Models 归一化流(NFs)是基于似然性的模型,适用于连续输入。它们在密度估计和生成建模任务中展现了有前景的结果,但近年来相对较少受到关注。在本研究中,我们展示了NFs的能力超出了此前的认知。我们提出了TARFLOW:一种简单且可扩展的架构,能够实现高性能的归一化流模型。 TARFLOW可以被视为基于Transformer的掩蔽自回归流(MAFs)的变体:它由一系列自回归Transformer块组成,作用于图像补丁,并在层之间交替改变自回归方向。TARFLOW的训练过程简单,支持端到端的训练,并能够直接建模和生成像素。
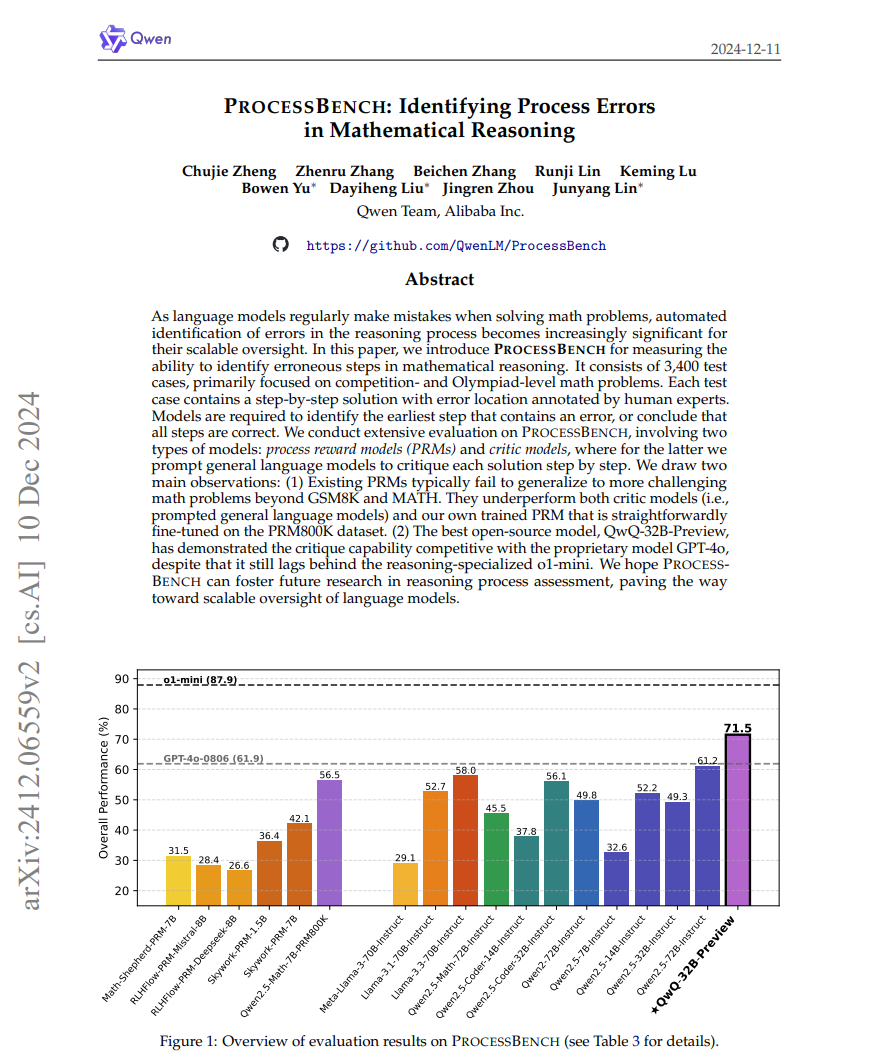
将这些技术结合起来,TARFLOW在图像的似然估计任务中创造了新的最先进结果,显著超过了之前的最佳方法,并生成了质量和多样性与扩散模型相当的样本,这是第一次通过独立的归一化流模型实现的。 https://arxiv.org/abs/2412.06329 ProcessBench: Identifying Process Errors in Mathematical Reasoning 由于语言模型在解决数学问题时经常出现错误,因此自动识别推理过程中的错误变得愈加重要,以实现对其可扩展的监督。在本文中,我们介绍了ProcessBench,这是一个用于衡量识别数学推理中错误步骤能力的工具。它包含3,400个测试案例,主要聚焦于竞赛级和奥林匹克级数学问题。每个测试案例包含逐步解决方案,错误位置由人工专家标注。模型需要识别出包含错误的最早步骤,或判断所有步骤都正确。 我们在ProcessBench上进行了广泛评估,涉及两种类型的模型:过程奖励模型(PRM)和批评模型。对于后者,我们通过提示通用语言模型逐步批评每个解决步骤。我们得出两条主要结论:(1) 现有的PRM通常无法很好地推广到更具挑战性的数学问题,尤其是超出GSM8K和MATH范围的问题。它们的表现不如批评模型(即提示的通用语言模型)和我们基于PRM800K数据集微调的训练PRM。(2) 最佳的开源模型QwQ-32B-Preview展现出了与专有模型GPT-4o相当的批评能力,尽管它仍落后于专注推理的o1-mini。 我们希望ProcessBench能够促进未来在推理过程评估方面的研究,为语言模型的可扩展监督铺平道路。 https://arxiv.org/abs/2412.06559 S2FT: Efficient, Scalable and Generalizable LLM Fine-tuning by Structured Sparsity 目前,针对大规模语言模型(LLMs)的PEFT方法通常只能在高质量、高效训练或可扩展推理之间做出选择,而无法同时实现三者的优势。为了解决这一限制,我们研究了稀疏微调,并观察到其在泛化能力上的显著提升。基于这一关键发现,我们提出了一种面向LLMs的结构化稀疏微调(S2FT)方法系列,能够同时实现最先进的微调性能、训练效率和推理可扩展性。S2FT的核心思想是“稀疏选择,密集计算”。具体而言,它在每个Transformer块中分别选择MHA(多头自注意力机制)和FFN(前馈神经网络)模块中的少数头和通道。然后,它通过联合排列LLM中耦合结构两侧的权重矩阵,将每层中选定的组件连接成一个密集子矩阵。最后,S2FT对所有子矩阵执行就地梯度更新。 通过理论分析和实证结果,我们的方法能够有效防止过拟合和遗忘,在常识推理和算术推理任务上分别相比LoRA提升了4.6%和1.3%的平均性能,并且在指令调优后的跨领域泛化能力上超越了完全微调(FT)11.5%。使用我们的部分反向传播算法,S2FT在训练过程中节省了最多3倍的内存,并且比完全微调提高了1.5至2.7倍的延迟,同时在这两项指标上都能比LoRA实现平均10%的性能提升。 我们进一步证明,S2FT中的权重更新可以解耦成适配器(adapters),从而为服务多个微调模型提供有效的融合、快速切换和高效并行处理能力。 https://arxiv.org/abs/2412.06289 HuggingFace&Github Django API 模板设计 https://github.com/MaksimZayats/aiogram-django-template
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/25529.html