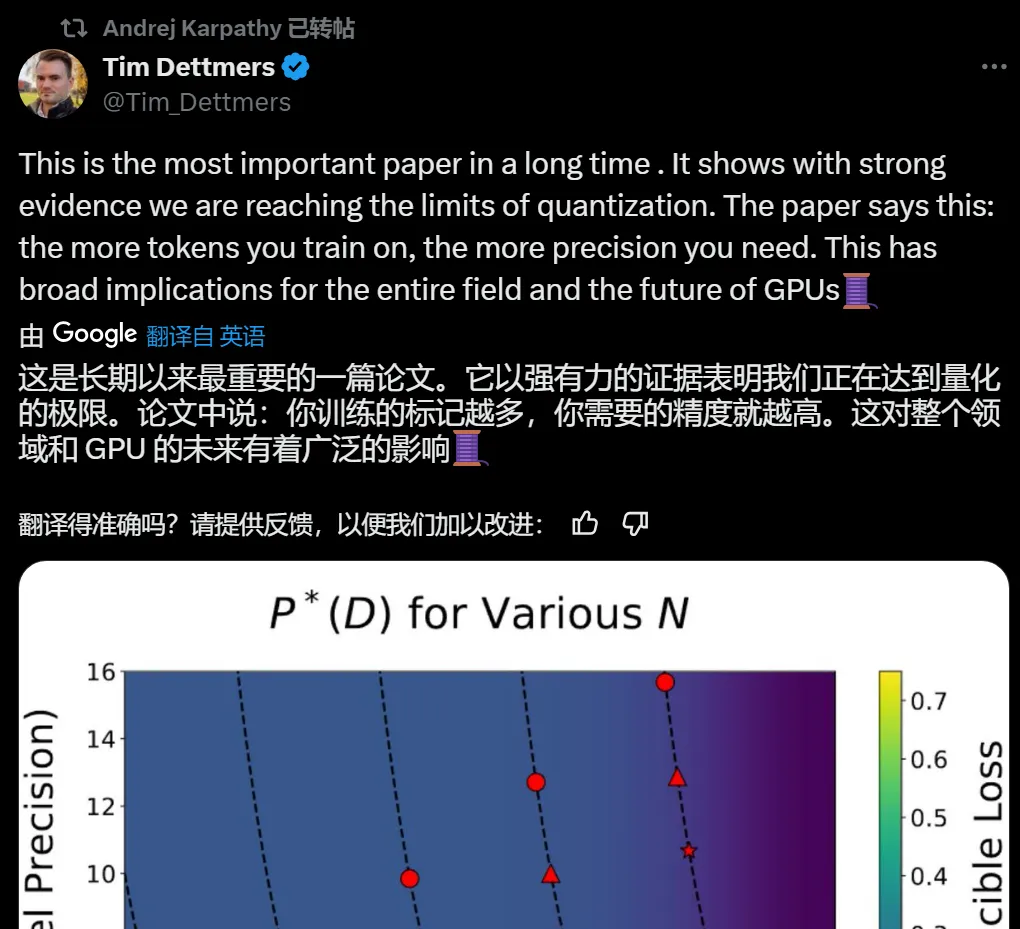
ToolJet 是一个开源低代码开发平台,可以帮助用户通过可视化界面快速构建和部署应用程序。它支持多种数据源和 API 集成,允许用户通过拖放组件轻松设计界面,适合希望快速开发原型或小型应用的团队和个人。https://tooljet.com
投融资
01
Red Hat收购AI优化初创公司Neural Magic
IBM旗下的开源软件公司Red Hat宣布收购了AI优化初创公司Neural Magic。该公司专注于优化AI模型,使其能够在普通处理器和GPU上更高效地运行,速度达到类似专用AI芯片(如TPU)的水平。Neural Magic的目标是通过其软件平台,利用常见处理器的内存优势,提升AI工作负载的处理效率。Neural Magic成立于2018年,由麻省理工学院的研究员Alex Matveev和Nir Shavit创立。该公司至今已获得来自Andreessen Horowitz、New Enterprise Associates、Amdocs、Comcast Ventures、Pillar VC及Ridgeline Ventures等投资者的5000万美元风险投资。此次收购对Red Hat而言意义重大。Red Hat CEO Matt Hicks表示,Neural Magic在开源项目vLLM(用于模型部署)方面的贡献,使其成为公司收购的关键因素。通过这项收购,Red Hat将能够向客户提供一个“企业级”的AI优化堆栈,进一步增强其混合云解决方案的能力,尤其是在跨云环境中优化和部署AI模型的能力。此举不仅强化了Red Hat在AI领域的布局,还使其在云计算和AI基础设施优化领域进一步巩固了市场地位。随着AI技术的需求激增,大型科技公司纷纷收购那些能够帮助优化AI算法的公司,类似的收购行动正在成为行业趋势。公司官网:https://neuralmagic.com/https://techcrunch.com/2024/11/12/red-hat-acquires-ai-optimization-startup-neural-magic/02
General Catalyst 和 Khosla Ventures 投资数据映射初创公司 Lume
数据集成是许多工作流程中的关键环节,但许多企业在处理数据时面临繁琐的手动操作。Lume 致力于利用 AI 自动化数据映射,解决这一问题。通过其系统,Lume 能够提取来自不同数据库的信息,将其“标准化”以便更轻松地进行集成或迁移,且在数据集成出现故障时,Lume 还能自动通知并尝试修复问题。Lume 专注于复杂的嵌套数据格式(如 JSON),并非仅仅局限于电子表格或 PDF 文件的提取,因此能够帮助公司更加高效地处理复杂的数据任务。Lume 成立于2023年,由斯坦福大学的三位计算机科学专业的创始人创建。公司于同年推出了首个产品,并通过了 Y Combinator 的 W23 批次。Lume 最近完成了一轮420万美元的种子融资,由 General Catalyst 领投,Khosla Ventures、Floodgate 和 Y Combinator 参与,此外还有一些天使投资者的支持。此次融资将用于扩展团队,Lume计划将员工人数从5人增加至10人,并继续推进技术研发。Lume的目标是成为数据系统之间的“胶水”,使数据流动变得更加顺畅。与Lume竞争的公司包括SnapLogic和Osmos等,但创始人对竞争并不担忧,认为Lume的算法和其API的整合能力使其能够脱颖而出。公司官网:https://lume.ai/https://techcrunch.com/2024/11/12/general-catalyst-and-khosla-ventures-back-data-mapping-startup-lume/03
生成式AI初创公司Writer完成2亿美元融资,估值达到19亿美元
生成式AI初创公司Writer宣布完成了一轮2亿美元的C轮融资,此轮融资将用于扩大其面向企业的生成式AI平台。融资由Premji Invest、Radical Ventures和ICONIQ Growth联合领投,Salesforce Ventures、Adobe Ventures、B Capital、Citi Ventures、IBM Ventures和Workday Ventures等也参与了此次投资。Writer创始人兼CEO May Habib表示,本轮融资将帮助公司加速产品开发,并进一步巩固其在企业级生成式AI领域的领导地位。Habib指出,Writer不仅仅是在创建能够执行任务的AI模型,而是在开发能够为企业提供关键任务支持的先进AI系统。Writer成立于2020年,由May Habib和Waseem AlShikh创办。两位创始人此前共同推出了Qordoba,帮助公司进行产品本地化。Writer目前已经发展成一个全面的生成式AI平台,产品可以根据不同的企业需求进行定制。2023年,Writer推出了自家开发的文本生成模型Palmyra,并且引入了能够将企业数据源与其模型连接的功能。2024年10月,Writer发布了基于合成数据训练的Palmyra X 004模型,开发成本仅为70万美元,相较于同等规模的OpenAI模型(成本约460万美元),成本大大降低。尽管生成式AI市场竞争激烈,Writer已经吸引了包括Mars、Ally Bank、Qualcomm、Salesforce、Uber、Accenture、L’Oréal和Intuit等在内的大量客户。Salesforce的产品营销高管Patrick Stokes表示,Writer提供的AI解决方案非常有效且易于部署,已经在加速Salesforce的工作流程。此外,Accenture、Balderton、Insight Partners和Vanguard等也参与了Writer的C轮融资。这一轮融资进一步展示了风险投资界对生成式AI的热情未减,随着生成式AI市场预计将在未来十年内突破1万亿美元的收入,尽管面临隐私、版权等挑战,该市场仍然具有巨大的增长潜力。公司官网:https://writer.com/https://techcrunch.com/2024/11/12/generative-ai-startup-writer-raises-200m-at-a-1-9b-valuation/04