我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
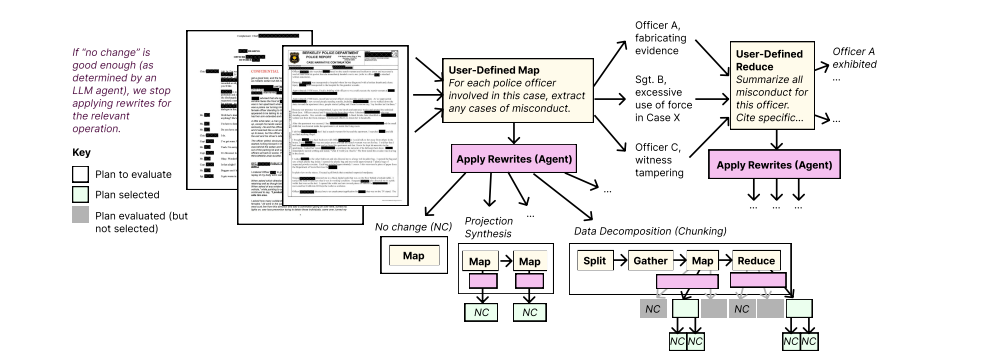
DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing
这篇文章介绍了DocETL系统,它是一个用于优化复杂文档处理流程的工具,旨在克服大型语言模型(LLMs)在处理非结构化数据时的局限性。DocETL提供了一个声明式接口供用户定义处理流程,并使用基于代理的框架自动优化这些流程,包括逻辑重写、任务验证提示的合成以及高效的计划查找算法。实验结果表明,DocETL相较于现有的基线方法,在处理不同类型的非结构化文档分析任务时,输出质量有显著提升。
https://x.com/IntuitMachine/status/1850675183012475035
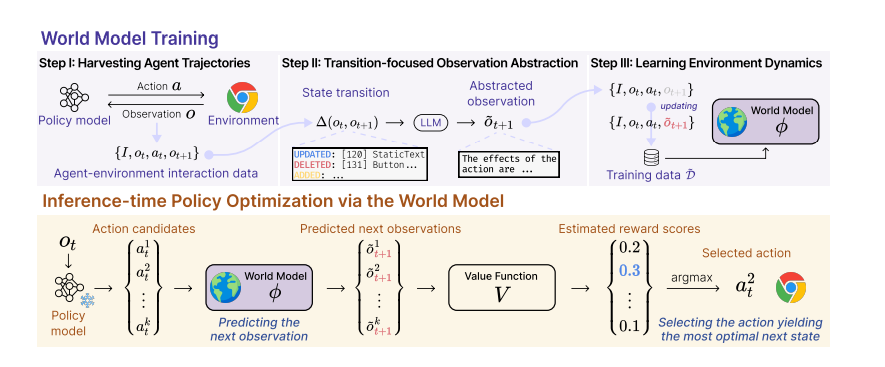
Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation
这篇文章指出当前大型语言模型(LLMs)驱动的网络代理在处理长期任务时存在缺陷,如重复购买不可退款的机票等错误行为。为了解决这一问题,研究提出了一个增强版的世界模型(World-model-augmented, WMA)网络代理,通过模拟行动后果来改进决策。为了克服训练过程中遇到的问题,如观察值中的重复元素和长HTML输入,研究团队设计了一种过渡聚焦的观察抽象方法,并证明了这种方法的有效性。
https://x.com/IntuitMachine/status/1850666524962382156
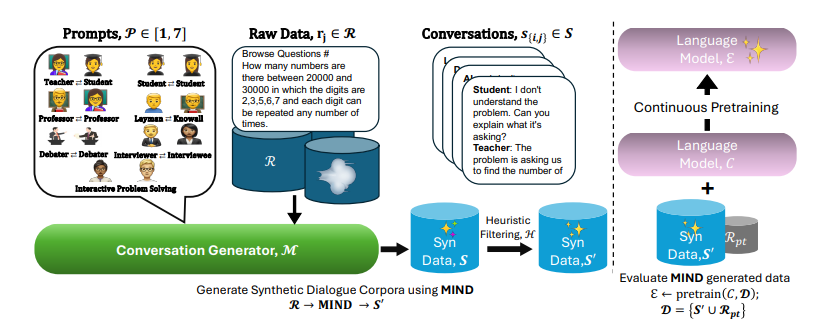
MIND: Math Informed syNthetic Dialogues for Pretraining LLMs
这篇文章介绍了一种新的大规模多样化的数学对话合成数据生成方法,称为Math Informed syNthetic Dialogue(MIND),用于提高大型语言模型(LLMs)的数学推理能力。通过基于OpenWebMath(OWM)生成合成对话,形成新的数学语料库MIND-OWM。研究发现,在预训练过程中整合知识差距和重新组织原始数据格式能够显著提高模型的数学推理能力。
https://x.com/IntuitMachine/status/1850611844148506741
Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
这篇文章介绍了一个大规模的多模态指令数据集Infinity-MM,包含4000万样本,并通过严格的质量过滤和去重来提高数据质量。基于这个数据集,研究人员提出了一种基于开源视觉语言模型(VLMs)的合成指令生成方法,并训练了一个拥有20亿参数的模型Aquila-VL-2B,该模型在类似规模的模型中达到了最新的最佳性能(SOTA)。研究表明,扩大指令数据规模和生成合成数据可以显著提升开源模型的性能。
https://arxiv.org/pdf/2410.18558
Framer
Framer是一种交互式帧插值工具,通过用户定制的关键点轨迹在两幅图像之间生成平滑过渡。它提供更精细的局部运动控制,并增强模型处理复杂情况的能力。此外,Framer还具有“autopilot”模式,可自动估计关键点,简化使用。实验表明其在多种应用中表现优异,相关资源将发布以支持进一步研究。

https://aim-uofa.github.io/Framer/
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21644.html