我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
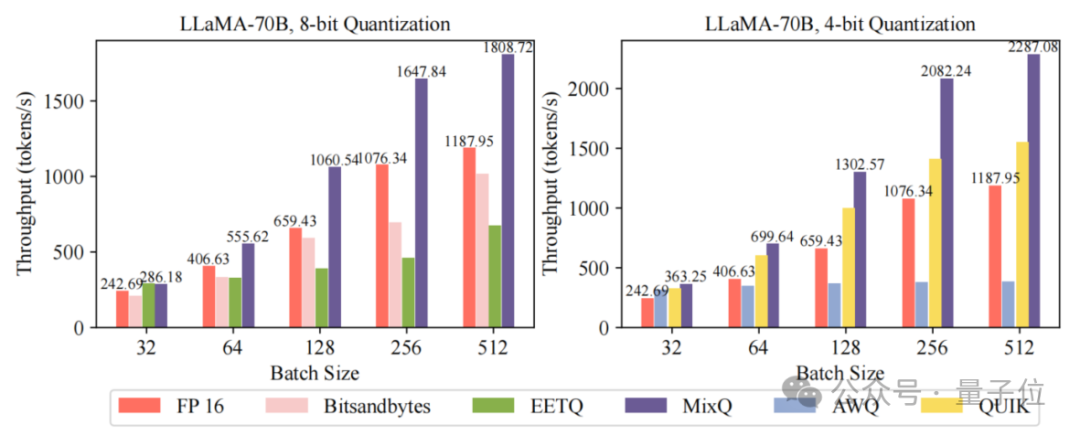
资讯 清华开源混合精度推理系统MixQ
量化权重与激活:MixQ同时量化权重和激活,使用INT8/INT4张量核心进行推理加速,并通过FP16张量核心处理少量激活中的离群值,既保持精度又提升吞吐量。其混合精度量化策略使推理精度几乎无损,精度下降不到0.1%。
等价变换优化计算图:MixQ基于离群点的局部性,优化了混合精度推理的计算图,避免了重复检查离群点的开销。通过量化系数中的amax值判断矩阵中的离群点,从而降低计算开销。
高效数据结构与CUTLASS优化:MixQ设计了新型数据结构,通过将离群点“拼接”成矩阵,减少访存开销。同时,使用CUTLASS 3.x编写高性能算子,将低精度计算结果反量化并与高精度结果相加,进一步提升性能。
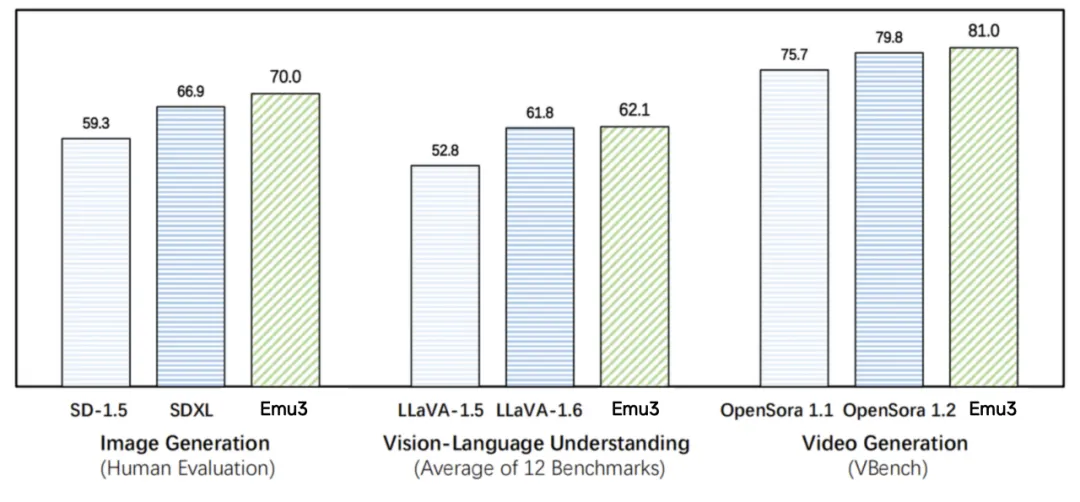
智源发布原生多模态世界模型Emu3 实现图像、文本、视频大一统 视觉tokenizer:Emu3通过一个强大的视觉tokenizer将图像和视频转化为离散的token,能够与文本token统一处理。这个视觉tokenizer基于MoVQGAN架构,在时间和空间维度上实现了显著的压缩,同时通过三维卷积层增强了视频的处理能力。 网络架构:Emu3保留了Llama-2的大语言模型架构,但扩展了嵌入层以容纳视觉token,并采用了如RMSNorm、GQA注意力机制、SwiGLU激活函数等技术。同时,模型通过改进的嵌入层处理多模态输入,使用QwenTokenizer进行多语言文本编码,消除了部分传统偏置设计。 多模态数据处理:Emu3对图像和视频进行了密集的标注和过滤处理,创建了一个大规模的多模态数据集。其预训练分为两个阶段,分别处理图像和视频数据,通过极长的上下文长度(最高达131,072个token)实现了复杂视频数据的建模。 直接偏好优化(DPO):在视觉生成任务中,Emu3使用DPO技术,使模型生成的内容更符合人类偏好,这种方法无缝应用于自回归的视觉生成,确保生成结果更自然和贴近人类需求。 Bengio团队新论文!强化学习新策略:不要做我可能不会做的事情 在强化学习中,当智能体的奖励机制与设计者的意图不一致时,可能会导致不理想的行为。为防止这种情况,通常采用KL正则化技术,通过限制智能体的行为来减少不符合设计者意图的行为。然而,这种方法并不能完全避免意料之外的行为,特别是在基于贝叶斯预测模型进行模仿学习的情形下。 KL正则化通过衡量提议策略与基础策略的相似性来限制智能体的行为,但它有局限性。研究表明,当基础策略是可信策略的贝叶斯模仿时,KL约束的效果会随着训练数据的增加而逐渐减弱,这意味着智能体在新环境下仍然可能表现出异常行为。核心问题在于,贝叶斯模仿在处理不确定性时,无法有效区分一些看似合理但实际上不应采取的行动。 为解决此问题,研究者提出了新的理论方案,建议将指导原则从“不要做我不会做的事”改为“不要做我可能不会做的事”,以增强智能体在新环境中的谨慎性。此外,研究人员提出了一种基于贝叶斯预测和模仿的替代方案,允许智能体在不确定时寻求帮助,并通过实验证明这种方法可以提高智能体的可靠性。 实验结果表明,即使奖励机制不完美,智能体仍能找到简单有效的策略来最大化奖励,这表明我们需要更慎重地设计奖励系统。KL正则化在限制智能体行为方面的作用有限,尤其是在复杂的对话任务中,较小的KL预算虽然能使智能体的行为更复杂,但仍无法完全避免简单化和不理想的行为。这提醒我们在微调语言模型时,应关注整体的KL散度控制。 美国AI博士为何高产?欧洲博士的质疑与反思 在机器学习社区中,一位欧洲博士的质疑引发了广泛讨论。他正在攻读AI/机器学习方向的博士学位,学业进展看似顺利,但当他看到美国博士生们人均10篇AI顶会论文、5篇一作时感到震惊,提出了疑问:这些博士生是如何如此高效地产出如此多的高质量研究成果?
高强度工作文化:美国顶尖学术机构的博士生通常一周工作超过60小时,全年无休,形成了高强度的“内卷”文化。激烈的竞争环境推动博士生不断加大工作强度,以保持领先。
资源优势:美国顶尖实验室拥有大量的GPU等计算资源,极大地加速了研究进度。资源的巨大差异使得顶尖博士生能够快速完成高质量的研究。
顶尖人才聚集:美国的顶尖项目吸引了来自全球的优秀学生,他们在高压环境中协同工作,进一步推动了学术产出。
机构与名人效应:知名大学和实验室的资源与声望让这些博士生的论文更容易受到学术界的关注,即便质量未必最优,顶尖机构的标识也为其提供了隐形优势。
幸存者偏差:讨论中也有人指出,这类现象可能是一种幸存者偏差。美国顶尖博士的高产表现并不代表整体情况,许多博士生面临同样的科研压力却未能取得如此亮眼的成绩。
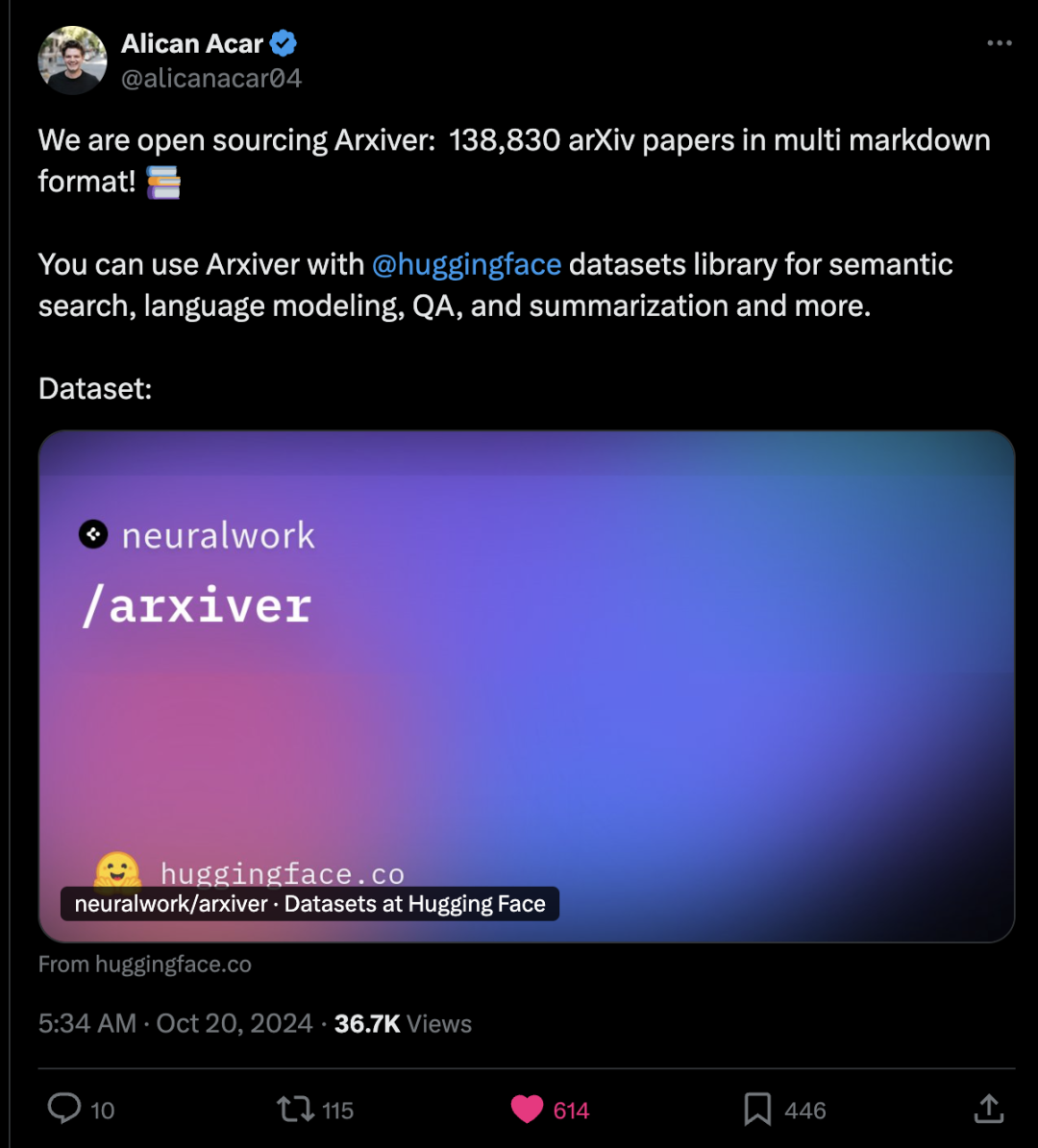
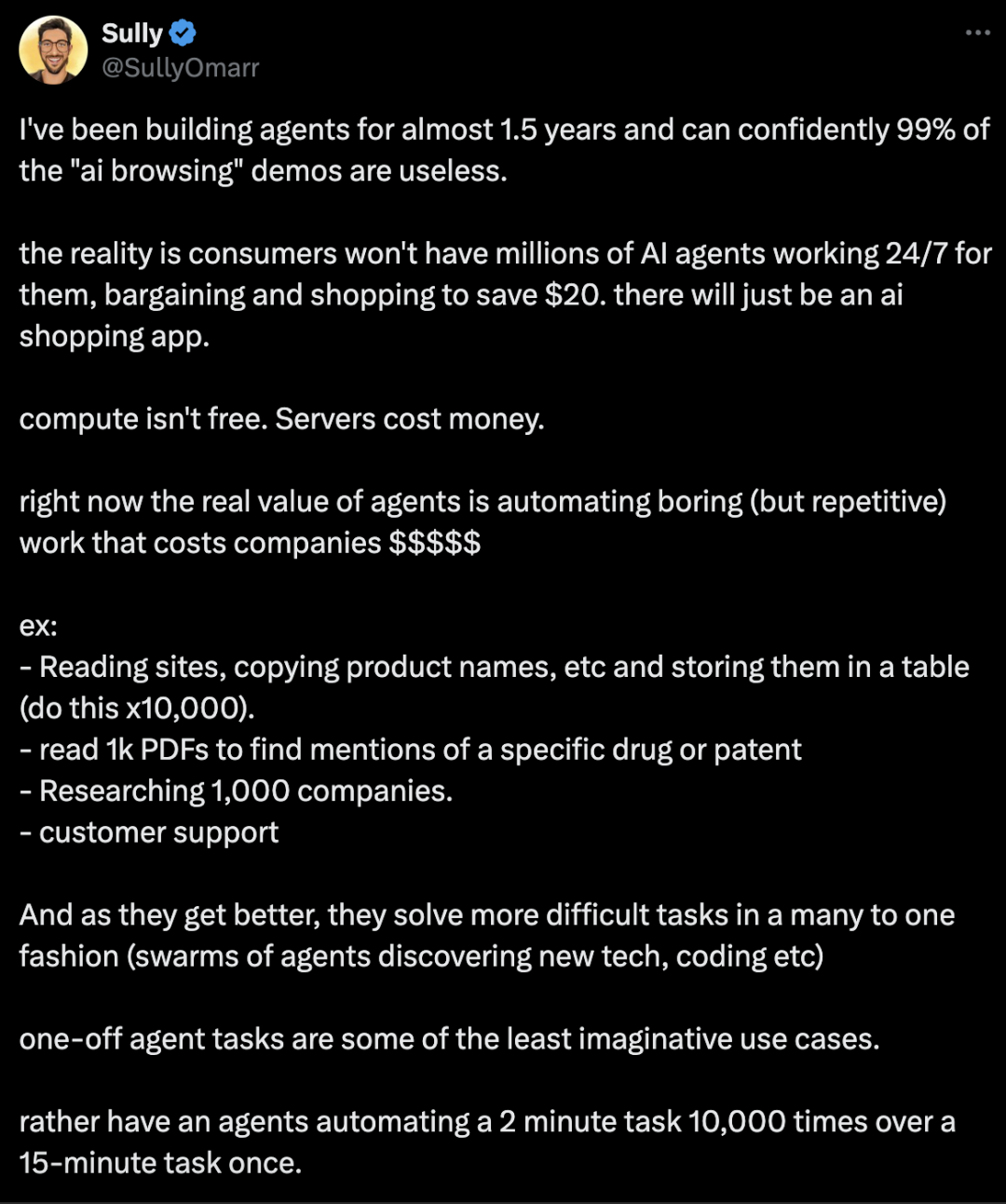
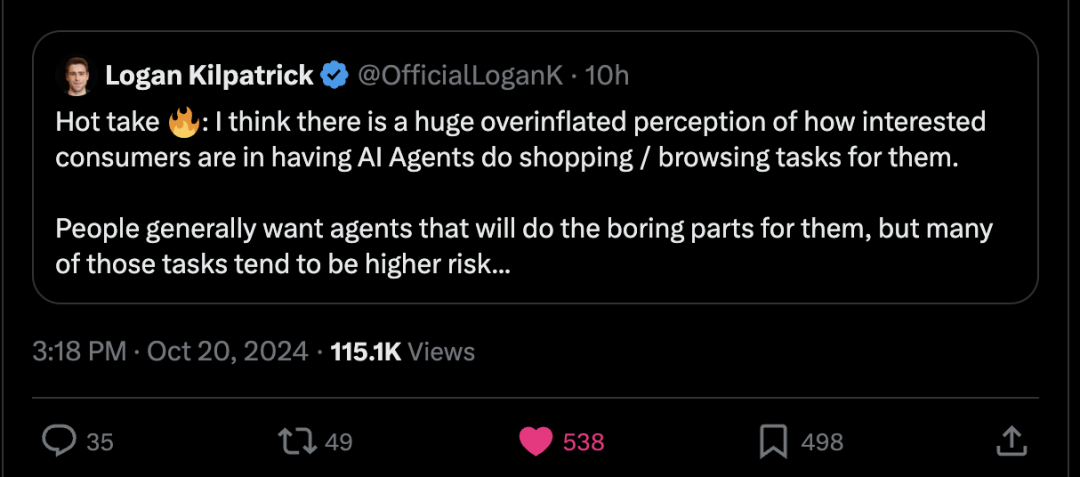
推特 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格式 我们正在开源 Arxiver:包含 138,830 篇 arXiv 论文的多Markdown格式!📚 你可以通过 @huggingface 的数据集库使用 Arxiver 进行语义搜索、语言建模、问答、摘要等任务。 https://x.com/alicanacar04/status/1847979788801052719 Sully谈自动代理:一次性代理任务是最没有想象力的用例之一 Sully:我已经构建智能代理将近1.5年了,可以自信地说99%的“AI浏览”演示是无用的。 现实是,消费者不会有数百万个AI代理24/7为他们工作,讨价还价、购物来省下20美元。最终只会有一个AI购物应用。 目前,代理的真正价值在于自动化那些无聊但重复的工作,这些工作对公司来说花费巨大。 • 阅读网站、复制产品名称等并将它们存储在表格中(这样做1万次)。 • 阅读1000份PDF文件以查找特定药物或专利的提及。 随着它们的进步,代理将以“一对多”的方式解决更多复杂的任务(如代理群体发现新技术、编程等)。 我更愿意让代理自动化一个2分钟的任务1万次,而不是自动化一次15分钟的任务。 Logan Kilpatrick:火热观点🔥:我认为消费者对让AI代理为他们完成购物/浏览任务的兴趣被大大夸大了。 人们通常希望代理能够处理那些无聊的部分,但很多此类任务往往风险较高… https://x.com/SullyOmarr/status/1848126562169999517 Tom Yeh分享手写Transfermer之Karpathy llm.c与矩阵乘法相连接 我制作了这个动画来手动✍️将 @karpathy 的 llm.c 与矩阵乘法相连接。
https://x.com/ProfTomYeh/status/1847673742106775668 IBM 和 Ollama 宣布合作推出 Granite 3.0 模型 今天,IBM 和 Ollama 宣布合作推出 Granite 3.0 模型!😍 • 2B:ollama run granite3-dense • 8B:ollama run granite3-dense:8b • 1B:ollama run granite3-moe • 3B:ollama run granite3-moe:3b https://ollama.com/blog/ibm-granite https://x.com/ollama/status/1848223852465213703 产品 AI Desk AI Desk 是一款由人工智能驱动的客户服务助手,可以在自动化支持流程并提升销售效率。它可以提供全天候的客户服务,通过训练 AI 使用业务数据,将会使成本降低多达 90%。AI Desk 能够识别潜在客户,自动回复消息,并支持多语言聊天,确保没有查询被遗漏。 BrowserCopilot AI BrowserCopilot AI 是一款 AI 浏览器助手,可以在任何网页上提供帮助,包括阅读、写作、解释、总结等功能。它能够理解用户在浏览器中的工作环境并提供相应的支持。据介绍,使用这款软件可以让用户每天工作提高 2-3 小时的效率。 https://www.browsercopilot.ai/ 投融资 2024年第三季度生成式AI初创公司投资超过39亿美元 尽管生成式AI的投资回报率存在争议,但许多投资者仍在积极下注。根据PitchBook的数据显示,2024年第三季度,风险投资公司(VC)在206笔交易中向生成式AI初创公司投资了39亿美元(不包括OpenAI的66亿美元融资)。其中,美国公司获得了29亿美元,涉及127笔交易。大额融资的公司包括:Magic(3.2亿美元),Glean(2.6亿美元),Hebbia(1.3亿美元),中国的Moonshot AI(3亿美元),以及日本的Sakana AI(2.14亿美元)。 生成式AI涵盖了从文本和图像生成器到编码助手和网络安全自动化工具的广泛技术领域。然而,技术可靠性和基于未授权数据训练模型的合法性引发了一些专家的质疑。但风险投资家认为,生成式AI将深入大规模、盈利丰厚的行业,并将在长尾市场获得稳固增长。 尽管生成式AI的计算需求巨大,可能带来能源消耗问题,但市场热情依旧高涨。包括微软、亚马逊、谷歌和甲骨文在内的大型数据中心运营商,正在投资核能来应对其非可再生能源消耗的增加,尽管这些投资的成效可能需要数年才能显现。 未来,生成式AI初创公司的投资热潮仍未显示出减缓迹象。 https://techcrunch.com/2024/10/19/former-openai-cto-mira-murati-is-reportedly-fundraising-for-a-new-ai-startup/ Perplexity计划以80亿美元估值筹集5亿美元资金 据《华尔街日报》报道,AI搜索引擎公司Perplexity正在进行融资谈判,计划以80亿美元的估值筹集约5亿美元。如果此轮融资顺利完成,Perplexity的估值将比今年夏天从软银获得融资时的30亿美元翻倍。目前,Perplexity每天处理约1500万次搜索请求,年收入约为5000万美元。 Perplexity通过AI技术为用户提供类似聊天机器人的搜索体验。然而,该公司因未经授权抓取网页内容而受到部分新闻出版商的指控,《纽约时报》甚至向其发出停止侵权函。对此,CEO Aravind Srinivas表示,他希望与出版商合作,无意与任何人对立。 此次融资谈判紧随OpenAI宣布完成66亿美元融资、估值达到1570亿美元之后。随着OpenAI推出更接近搜索引擎功能的产品SearchGPT,AI搜索领域竞争加剧。 目前,Perplexity的发言人拒绝对该报道发表评论。 https://techcrunch.com/2024/10/20/perplexity-is-reportedly-looking-to-fundraise-at-an-8b-valuation/ — END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21631.html