


MOLAR FRESH 2022年42期
人工智能新鲜趣闻 每周一更新
01
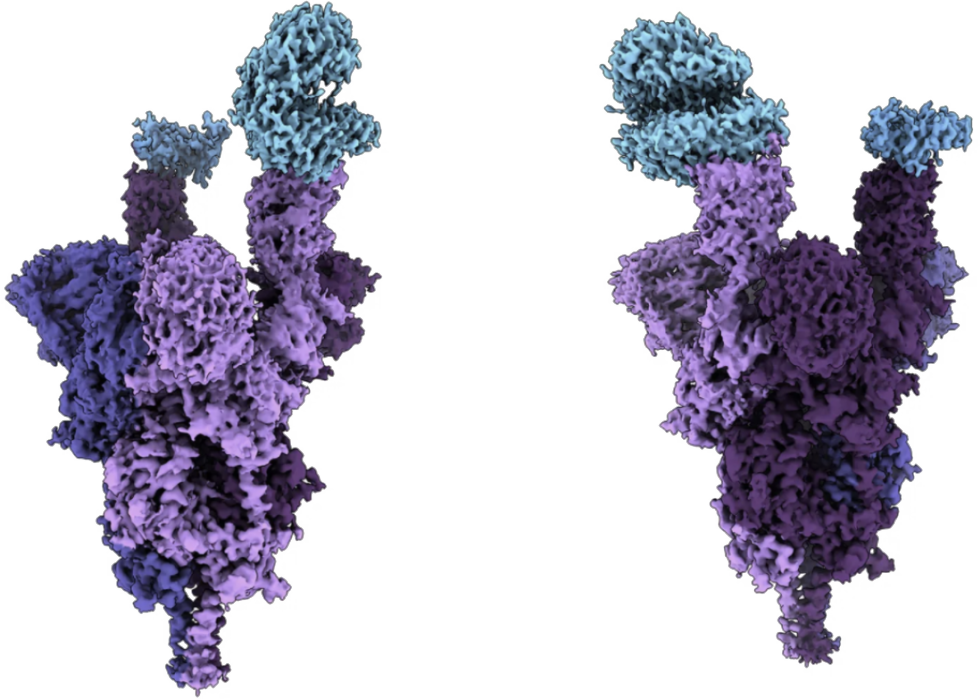
AI一小时预测出奥密克戎变体结构,误差仅半个原子直径
来自北卡罗来纳大学夏洛特分校的Colby Ford研究团队的最新研究成果:
依靠AI技术,几乎准确地预测了奥米克戎的复杂结构。
其工作可谓是“站在巨人的肩膀上”——利用AlphaFold2和RoseTTAFold预测出了3D蛋白质结构。
Ford所采用的AI方法,包含三个步骤:
第一步,是监测变种 (VBM)和关切变种 (VOC)的序列比较。
Ford团队下载了新冠病毒的参考基因组,以及各种VOC和VBM的前100个全基因组序列。
对这些基因组再进行一个“对齐”和“修剪”的工作,最终留下了1026条序列。
接着,Ford对这1026条序列进行“注释”,再根据序列相似性确定了该序列上的受体结合基序。
然后,他们用MEGA11.0.10版计算每对序列之间的成对p-距离,再使用标准翻译表将尖峰蛋白的这个变体核苷酸序列翻译成氨基酸。
最终对该序列进行修剪,使其只包含穗状蛋白的RBD。
第二步,是RBD的结构预测。
基于第一步得到奥密克戎衍生RBD氨基酸序列,Ford团队使用AlphaFold2和RoseTTAFold创建了预测的3D蛋白质结构。两个系统都产生了奥密克戎的预测RBD结构,以及围绕多序列比对覆盖率、预测比对误差(PAE)和预测置信度(pLDDT)等指标。
第三步,是中和抗体相互作用模拟。
基于第二步得到的奥密克戎RBD预测结构,模拟了与四个现有中和抗体结构的相互作用。只使用抗体结构的一个单片段抗原结合(Fab)区域作为对接的位置,并用到了生物分子建模软件HADDOCK,来预测RBD表位与中和抗体结构的副体之间的结合亲和力。
最后将实际复合物(即真正的RBD结构和Fab)与奥密克戎的预测RBD结构(有相同的Fab)的指标进行了比较。
Ford是这样总结的:
奥密克戎受体结合域(RBD)的一些结构变化,可能会减少抗体相互作用,但不会完全避开现有的中和性抗体。
换句话说,现有疫苗对奥密克戎是有作用的,但由于该病毒结构的差异,降低了抗体的识别能力。这解释了为何已经打过疫苗的患者依然会感染奥密克戎。
来源:量子位
参考链接:
[1]https://www.wired.com/story/ai-software-nearly-predicted-omicrons-tricky-structure/
[2]https://www.biorxiv.org/content/10.1101/2021.12.03.471024v4.full
[3]https://baijiahao.baidu.com/s?id=1721544674645640819&wfr=spider&for=pc
02
嘈杂场景语音识别准确率怎么提?脸书:看嘴唇
借助读唇语,人类能够更容易听懂他人的讲话内容,那么AI也能如此吗?
最近,Meta提出了一种视听版BERT,不仅能读唇语,还能将识别错误率降低75%。
效果大概就像如下这样,给一段视频,该模型就能根据人物的口型及语音输出他所说的内容。

而且与此前同类方法相比,它只用十分之一的标记数据,性能就能超过过去最好的视听语音识别系统。
这种结合了读唇的语音识别方法,对于识别嘈杂环境下的语音有重大帮助。
Meta的研究专家Abdelrahman Mohamed表示,该技术未来可用在手机智能助手、AR眼镜等智能设备上。
目前,Meta已将相关代码开源至GitHub。
Meta将该方法命名为AV-HuBERT,这是一个多模态的自监督学习框架。
多模态不难理解,该框架需要输入语音音频和唇语视频两种不同形式内容,然后输出对应文本。
在该模型中,通过一个ResNet-transformer框架可将掩码音频、图像序列编码为视听特征,从而来预测离散的集群任务序列。
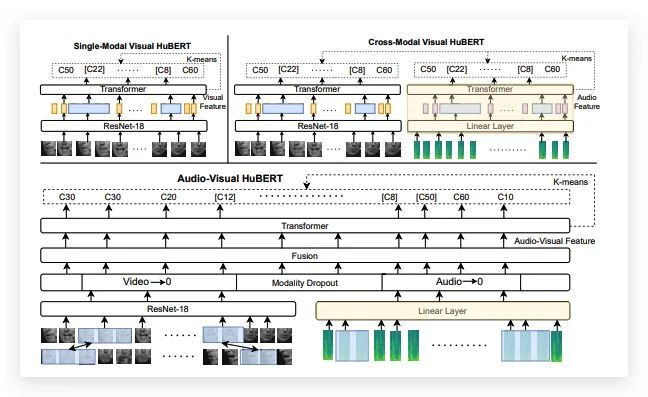
图像序列和音频特征能够通过轻量级的模态特定编码器来产生中间特征,然后将这个中间特征融合并反馈到共享的主干transformer编码器中,以此来预测掩蔽聚类任务(masked cluster assignments)。
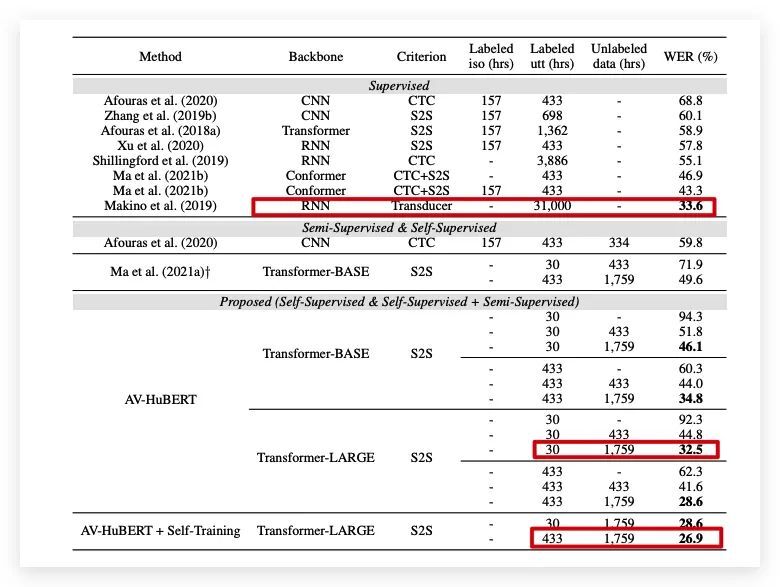
结果表明,AV-HuBERT经过30个小时带有标签的TED演讲视频训练后,单词错误率(WER)为32.5%,而此前方法能达到的最低错误率为33.6%,并且此方法训练时间高达31000个小时。
经过433个小时TED演讲训练后,错误率可进一步降低至26.9%。
另一方面,AV-HuBERT与前人方法最大不同之处在于,它采用了自监督学习方法。
在预训练中使用特征聚类和掩蔽预测两个步骤不断迭代训练,从而实现自己学习对标记的数据进行分类。
来源:量子位
论文地址:
[1]https://arxiv.org/abs/2201.02184
[2]https://arxiv.org/abs/2201.01763
GitHub地址:https://github.com/facebookresearch/av_hubert
参考链接:https://venturebeat.com/2022/01/07/meta-claims-its-ai-improves-speech-recognition-quality-by-reading-lips/
03
这只日本AI爆火:草图实时变身二次元老婆,还有512种参数可调
画画手残,但还是想拥有属于自己的二次元wife怎么办?
没问题。
真·有手就行:

是的,只要你能给出草图,AI都能把它变成二次元美少女,并表示:多草都行。

这个由日本插画网站Pixiv官方技术人员“业余”开发的AI,曾一度登顶日推趋势榜,现在的点赞数已经接近16万:
在此之后,作者还加入了512个参数滑块,可以对绘画风格、脸部投影、形状等多个方向进行修改,详细设置甚至到了8192种:

当然,作者目前只放出了演示视频,评论区出现了大批网友组团刷屏求开源,求Demo的。
我们往期介绍过很多草图生成图画和人脸的技术,这一AI应该也是基于StyleGAN所做的进一步开发。
StyleGAN重新设计了GAN的生成器网络结构:
生成器从学习到的常量输入开始,基于潜码调整每个卷积层的图像“风格”,从而直接控制图像特征,进而控制整个图像生成的过程。
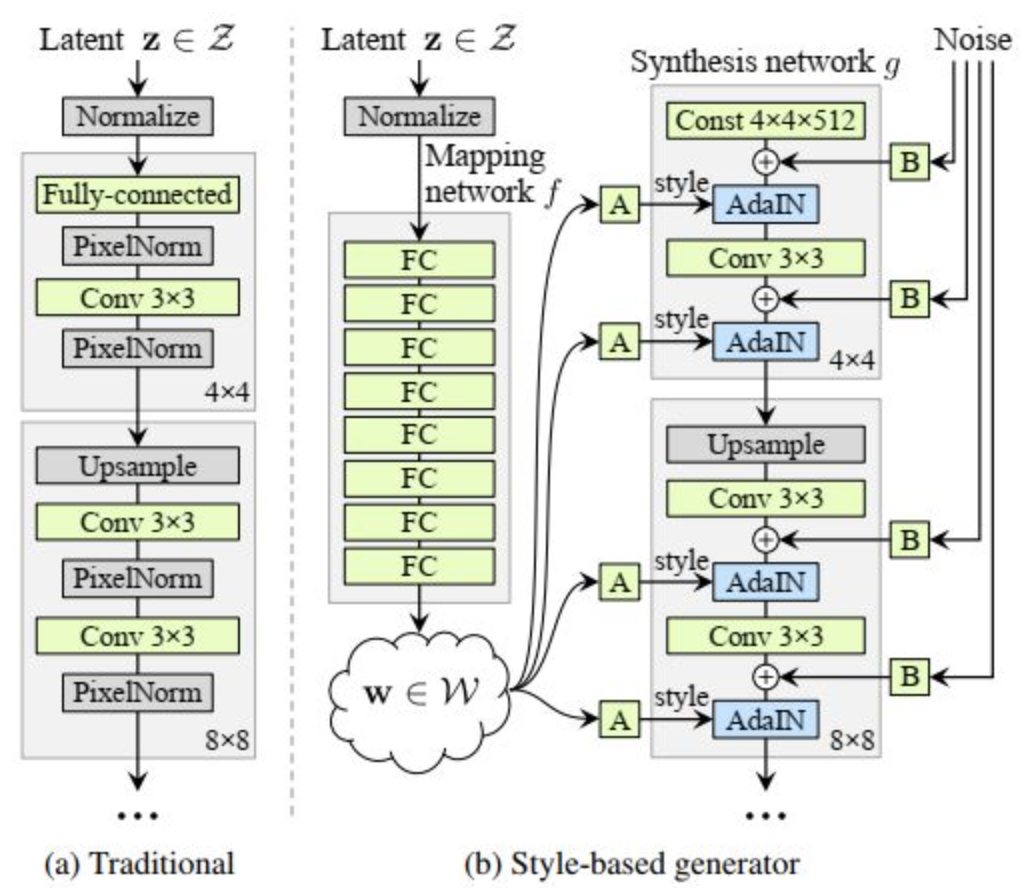
同时,由于这一过程中可以结合直接注入网络的噪声,直接更改所生成图像中的随机属性,所以大家也能看到,基于StyleGAN的整活儿可以说是层出不穷。
来源:量子位
参考链接:
[1]https://twitter.com/t_takasaka/status/1477633104928178176
[2]https://twitter.com/t_takasaka/status/1478346974042923012
04
从科幻走进现实:在人脑中植入芯片,脑机结合的生活
近日,布朗大学神经科学实验室展示了这样一幅画面:一位瘫痪的、不能说话的患者,安装上一个名为BrainGate的系统。系统包括一个植入运动皮层的微小电极阵列,一个在头顶悠然自得的插头,一个鞋盒大小的信号放大器,以及一台装有患者神经信号解码软件的计算机。
患者试图用机械臂拿起一瓶咖啡,她手握住瓶身,送至嘴边,并从吸管里喝了一口。


脑机结合的原理——解码算法
研究人员通过芯片收集人脑信号,并对其进行实时的数学计算,就像手机和电脑的工作原理一样,我们称这个过程为:解码算法。
解码算法可以在定制的硅芯片上运行,因为它能耗极低,这不仅有助于延长植入装置的电池寿命,同时意味着不用担心电池过热的问题,芯片可以读取并使用这些信号,继续传递信号。
脑机接口的原理就是,在某种程度上让脑信号与计算机信号互动,当一个神经元想和另一个神经元沟通时,会发出一种叫做动作电位的微弱电子脉冲。
研究人员必须搞懂的一个神经科学问题就是,不同的信号是在人脑的什么部位被编码的,以及如何被编码的。
以人工视网膜为例,它能帮助失明的人重建光明,可能是目前最成功的神经假体。人工视网膜植入患者眼中,就像镜头一样采光,将光信息转化成电刺激信号,重建视力。
同理,脑机接口的作用,是读取一个人的神经活动,并用它来驱动机器。
让大脑神经活动转化为实际动作,这项技术能切实改善身体障碍者的生活。

然而,设备植入大脑,就像在果冻上安装一幅画,肉体的”脆弱“有些不堪:“脑洞大开”留下的伤口使患者容易受到感染;电极阵列不可避免地造成脑组织损伤,它像一百根头发丝组成,从大脑伸出来;每一次晃动电极都有可能撕裂连接,与原来的神经元失去联系。随着时间的推移,电极周围形成疤痕组织,将它们与邻近的神经元隔离开来,使它们失去作用。
另外,研究人员可能会花几个月时间训练特定的细胞,但这些细胞最终会死亡。最终,患者身体的防御系统会自动关闭该实验。
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2022/01/8396.html