
引言
我有很多次被问到:要落地一个 AI 解决方案,需要花多少钱。
在阅读将近百篇文章后,试着尽我所能和大家讲清楚,并初步总结了一个带公式的飞书表格来计算(公众号回复“成本”),但其中仍然有值得进一步探究的地方,留待以后探讨。文章较长,建议收藏。
首先申明这里仅仅讨论算力成本,AI 应用落地的成本很大部分还包括人力资源、数据准备,但这二者不在今天的讨论范围内。
如果把这个问题用一个函数来解的话,我们从客户那里得到入参仅仅是:
入参 1:AI 产品的目标。即客户想做什么事情,这决定了通过什么方式来解决问题,不同的方式有不同成本计算定律。
入参 2:客户对安全、隐私方面的诉求。这决定了模型部署方式:私有化本地部署,或是云上部署。前者是一次性投入,后者是持续投入,也决定了不同的成本计算方法。
这两个入参相互独立,呈正交关系。我会在不同 AI 产品目标中,再分别针对私有化部署和云上部署进行计算。
2
基于 AI 产品的目标来做的算力需求评估
计算成本的前提是计算出算力需求,即需要多少次运算,就可以依据以下公式算出需要使用GPU、多长时间做完训练,我们用GPUhours来表示(参考做大模型AI应用一定要了解的成本计算公式)。
GPUhours=所需计算次数/(GPU 芯片每秒计算次数 * 3600 秒* GPU 利用率)
我用一个图表达 AI 产品目标对算力需求的影响,本文基本是围绕这张图来展开的,推荐大家仔细看。
这张图第二列是实现方法,其实就是各种方法对神经网络的参数的改变程度,我用不同颜色的直线来表示这种变化(灰色代表未训练的模型参数,红色代表基座模型的参数,绿色代表经过微调后的参数)。
在第三列的所需算力,是对应方法需要的计算次数,这大体上与被训练的模型参数量和训练参数量成正比,我用图形大小来直观的代表规模大小。
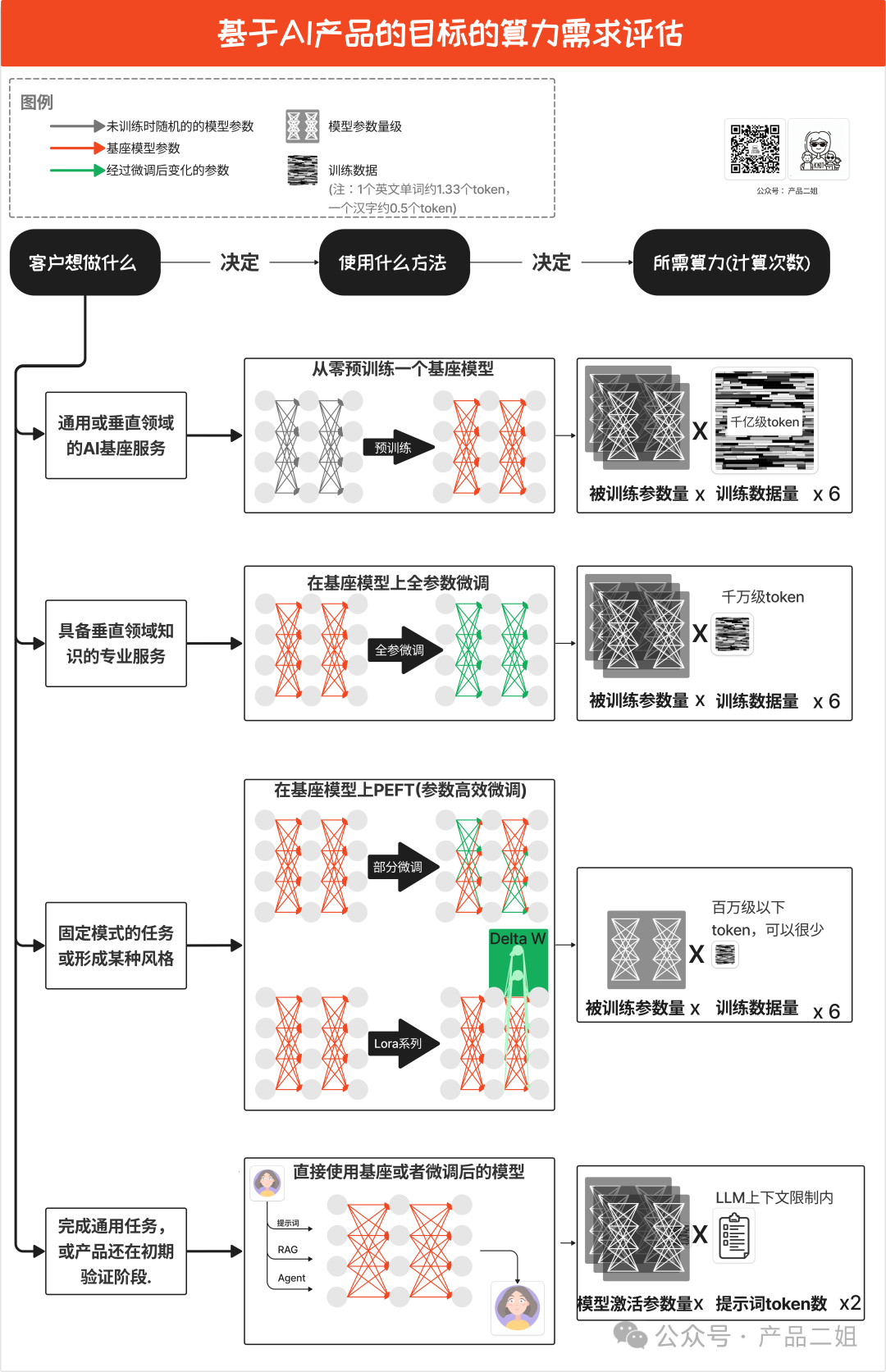

在展开细节之前,我们先将上图概述出以下四个要点:
1. 从算力上讲:在模型训练(对模型参数产生改变)中,不管是预训练还是微调,所需的算力都是:
被训练的模型参数量 * 训练数据量 * 6
这里乘以 6 是因为:在一次训练迭代中,包含前向传递和后向传递,前向传递对于每个 token 需要进行 2 次计算(一次加法,一次乘法),后向传递的计算量是前向传递的 2 倍,所以一次迭代总共是 6 次运算(参考《分析 transformer 模型的参数量、计算量、中间激活、KV cache》,《浅谈后向传递的计算量大约是前向传递的两倍》)。
这再次告诉我们算力(计算次数),算法(模型大小)和数据(训练数据量)之间的密切关系。
2. 从算法(参数量)上来说:预训练和全参微调,被训练的模型参数量和模型架构固有的参数量一致(图中的前两种情况),PEFT-参数高效微调(图中第三种情况)的参数量和训练方法有关,后面会有详细讲解。
3. 从训练数据上来说:预训练、全参微调和 PEFT 依次有数量级上的下降。
4. 最后一种情况,大多数情况下我们会直接使用模型厂商的服务,但如果用户希望私有化部署模型,则客户还需要承担日常的推理成本。所以这里并没有直接给出价格,而是仍然通过所需算力来表示,以方便私有化部署的读者参考。
最后,上图仅仅展示的是如何得出所需计算次数,是计算最终花多少钱的前提。在后文中,我们会按照两种情况给出具体金额的计算方法:
如果是租用资源,可以根据计算次数推算出所需时长,乘以租用价格;
如果是自己购买资源,首先需要计算模型的显存下限要求,在满足下限要求的情况下,计算出时间成本。或首先指定时间成本,再推算出所需硬件数量,然后根据市场价推算出购买硬件的成本。
接下来我们对每种情况做细致解读,其中也穿插了部分与大模型原理相关的知识,相信会对你有新的启发。
3
客户说:“我想提供通用或垂直领域 AI 基座服务”
你可能会略过这一部分,因为目前来说由于成本高昂这不是大多数的人选择,但最近看到越来越多的训练成本较低的小模型在垂直领域表现越来越好。比如专注于 Code Completion 的小模型 replit-code-v1-3b,使用了 525B 代码数据训练,已经在自己产品中被较好地使用。按照现有的 A100 租用价格计算,replit-code-v1-3b 大约五万美元可完成一次训练(马上会有推导)。这就让我不由地畅想未来会有各种垂直小模型,未来有可能你们也会拥有自己的小模型。因为算力成本还会下降,训练能力还会增强,数据会被进一步优质化、精简化。
3.1
快速估算:相对计算法
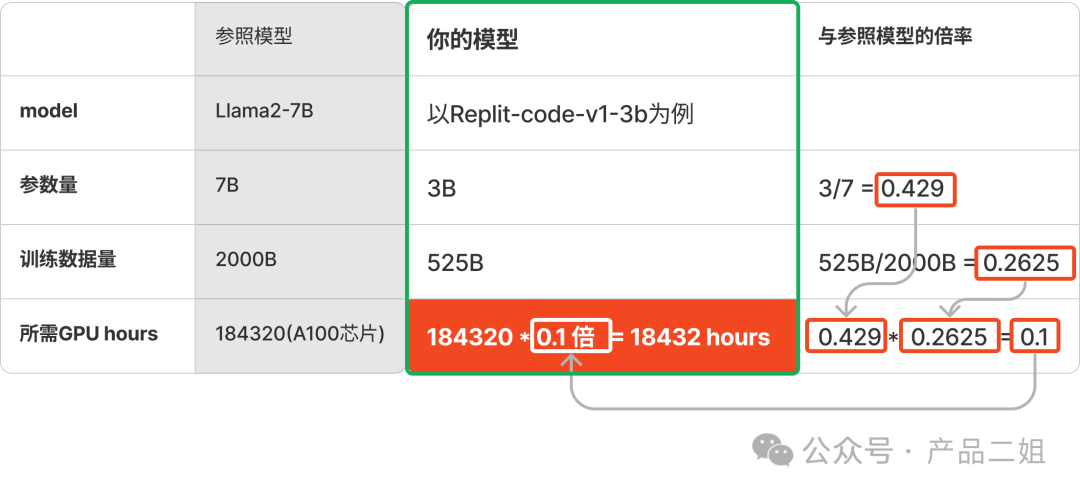
我们有个超级简单的方法来估算预训练成本:既然预训练所需计算次数与参数和数据量成正比,我们可以这两个数值与一个基准模型 llama2,或者 llama3 来对比,进行等比例推导就可以轻松获得。
比如下图中,参考 llama2-7B 的参数量,训练数据量,等比例倍率乘以 llama2-8B 消耗的 GPU hours,就可以得出训练 replit-code-v1-3b 所需 GPU hours。
在这里我列出重要的参照模型 llama 家族,并且也只有 llama 家族同时公布了参数量级、训练数据量级和所需 GPU hours,在做成本评估时,选取与你模型参数最接近 llama 版本作为基线标准。
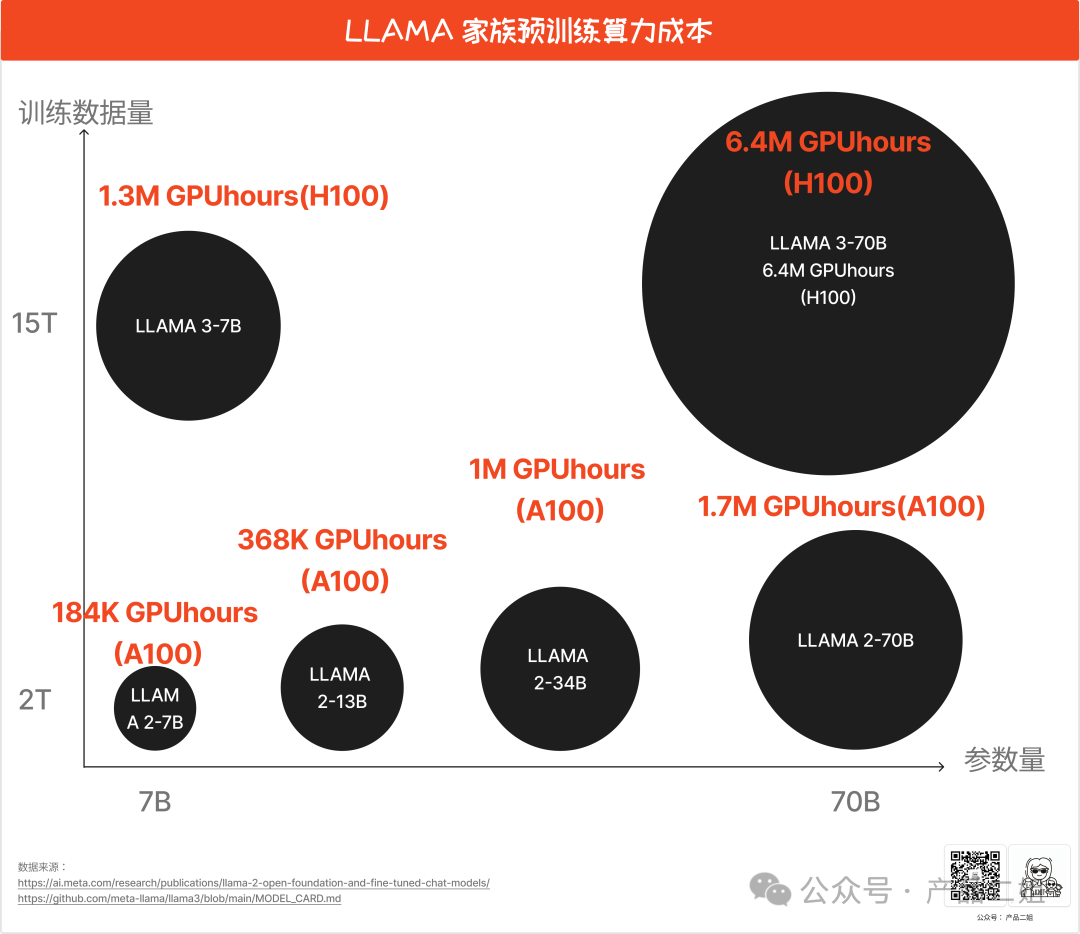
但在后续的计算中发现使用llama3 作为基准模型计算的偏差较大,虽然llama3 使用了H100训练,但从GPUhours上看,H100超高速的计算能力和使用A100训练llama2的优势并无体现。
以上是基于某个基准模型的计算方法,我称为相对计算法。接下来我们再基于原理来算一下,一方面可以加深对 LLM 原理的理解,另一方面和上述的相对计算法对比,二者相互验证。
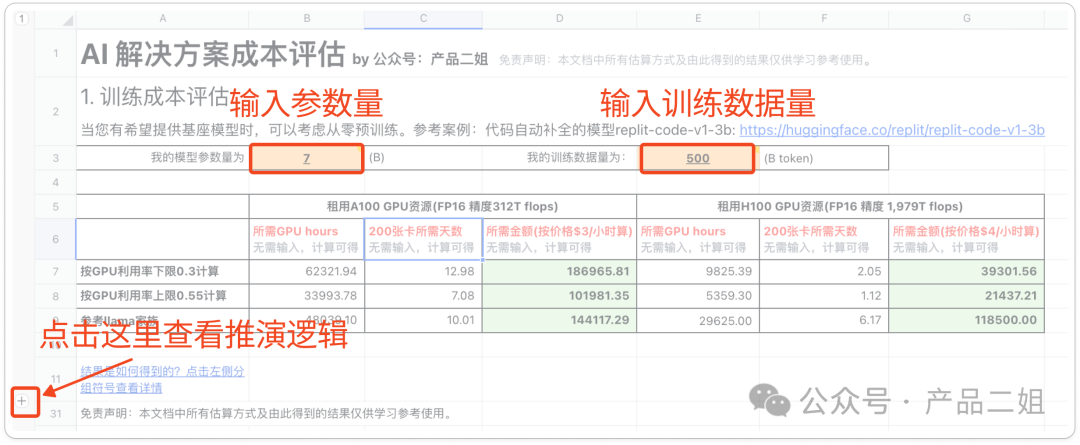
这两种方法我已经总结为飞书表格公式,公众号回复“成本” 即可获得飞书链接,需要您复制副本后在红框里输入参数量和训练数据量即可获得参考成本,点击左侧小+号展开即可获得详细推理公式,表格还会持续完善。
3.2
基于原理计算成本:绝对计算法
前面提到:
GPUhours=所需计算次数/(GPU 芯片每秒计算次数 * 3600 秒* GPU 利用率)
=被训练参数量*训练数据量*6/(GPU 芯片每秒计算次数*3600 秒*GPU利用率)
我就就来看看这两个变量:被训练参数量、训练数据量。
1)被训练的参数量
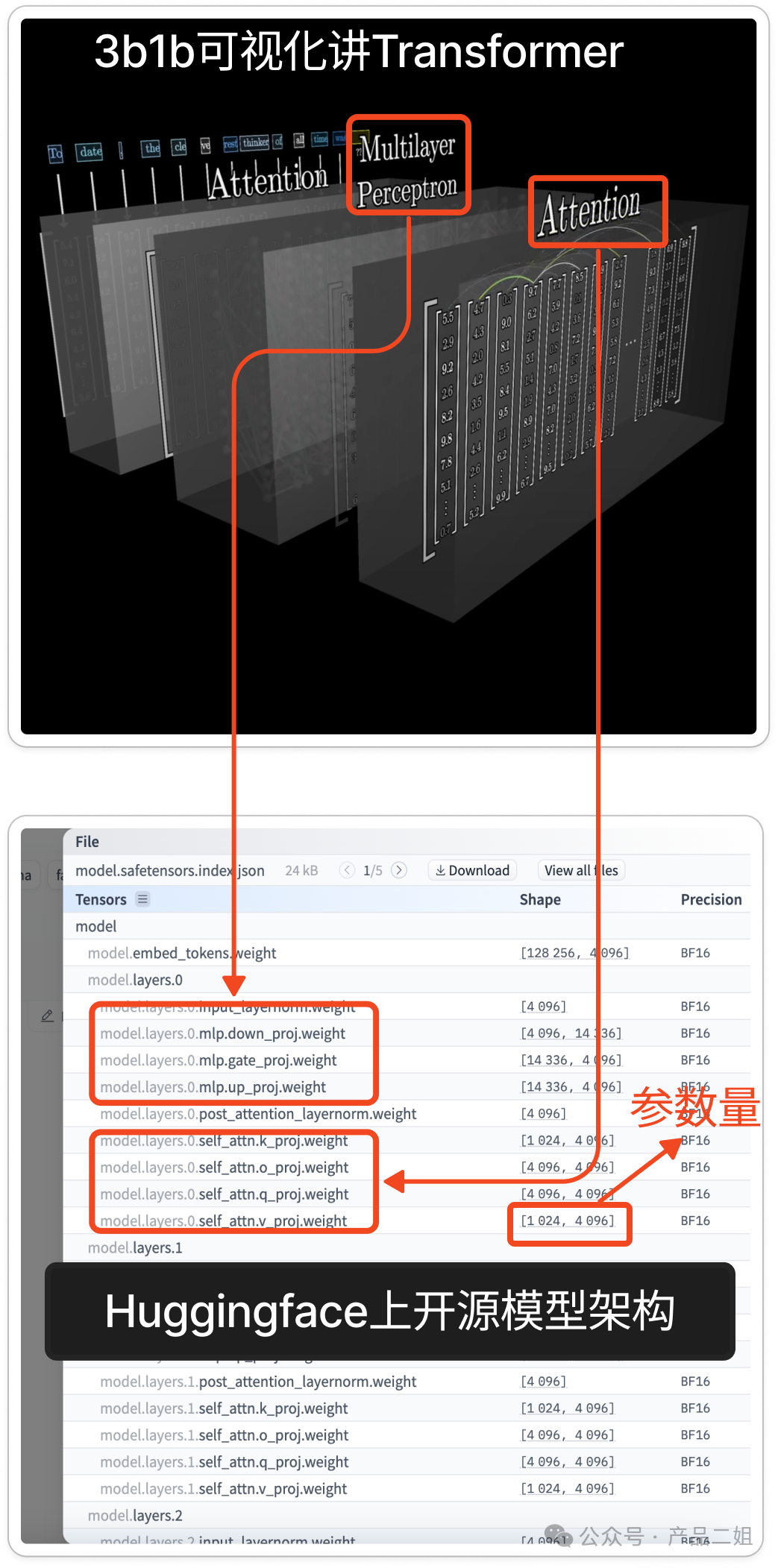
预训练需要训练模型的全部参数,由模型架构本身决定的。我们一般从模型的名称中就可以得到,比如 llama3-8B 就是 80 亿参数。更直观一点,下图上部分是3B1B 的 transformer架构可视化 ,下面部分是 huggingface 上对 Llama 3-8B 模型参数的拆解,右侧数字对应这一层神经网络的参数矩阵的规模。比如[1024,4096]代表这一层有1024*4096个参数。
2)关于预训练数据量的讨论
从零开始预训练模型的数据量最好有 200B 以上 Token(约 4000 亿汉字或 1500 亿英文单词)。但一般来说要比这个还要高,并且会越来越高,这源于一段大家对数据 scaling law 的认知变化:
> 在 2022 年初有一篇论文提出 Chinchilla 缩放定律,观点是当训练数据量是模型参数量的 15-25 倍,会取得比较好的收益。
> 在 2023 年 7 月初,有博客发表文章说 Chinchilla 缩放定律已死,认为只要数据量足够大,小模型也能被训练得很好。
> 紧接着在 2023 年 7 月中旬,llama2 发布,其中 7B 版本的小模型训练数据有 2T,是参数量的 285 倍。
> 后来在 2024 年 4 月 15 日,就有文章去复现 Chinchila 缩放定律时,发现原作者有一个地方算错了,按照新的理论:小模型经过大数据量的训练,也可以达到比较好的效果。
> 三天后,llama3 发布,其中 8B 版本的小模型训练数据为 15T,是参数量的 1875 倍。Chinchilla 缩放定律已经被打破。
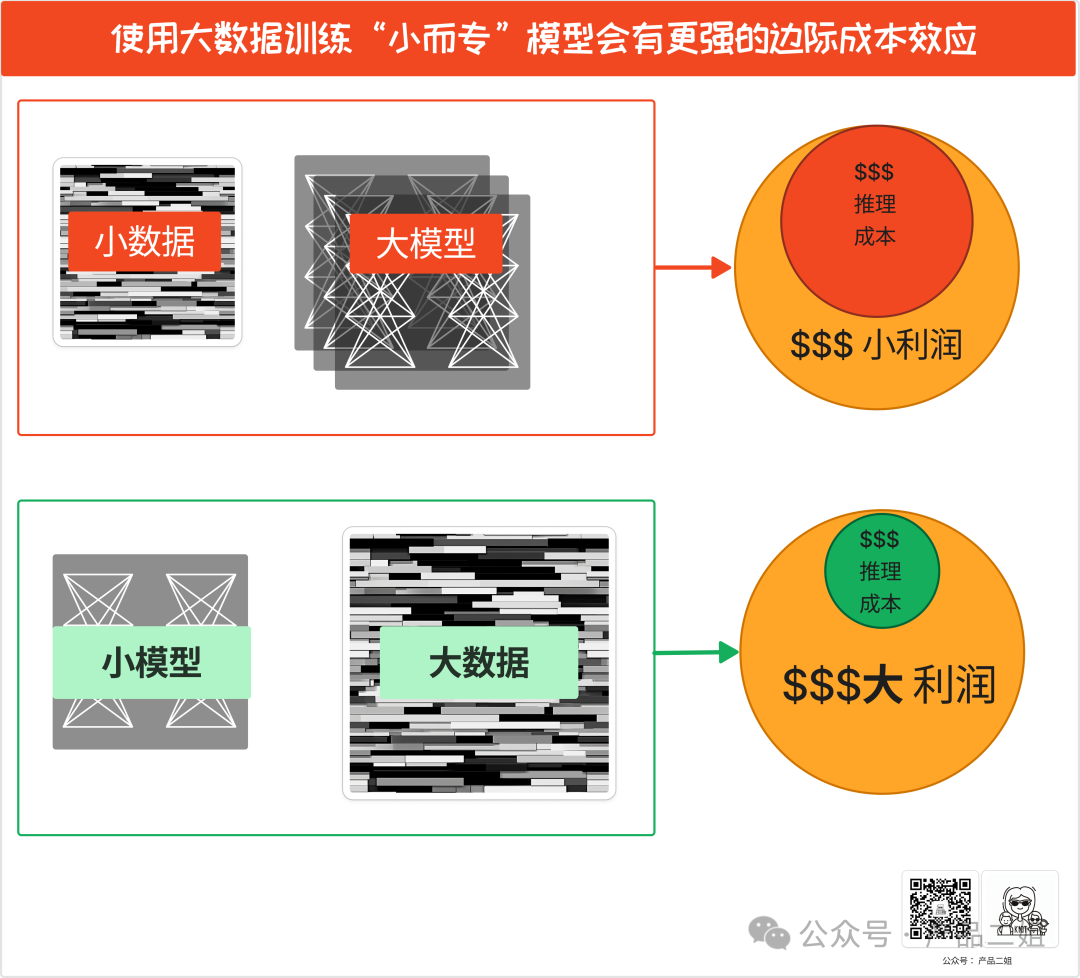
可见将来数据仍然会越来越成为稀缺资源:掌握了优质数据,训练出来的小模型质量会越好。如果模型训练成本降低,模型的价值将更多地转嫁给数据,而非 token 数。比如未来我们可能会出现某个专业领域极强极强的模型,用户并不是通过使用 token 来计费,而是为模型能力去付费,而这种能力正是优质的专业数据赋予的。
定义好计算算力的两个关键因素,接下来据此计算成本。
3)用绝对计算法计算成本
仍然以 Replit-code-v1-3b 为例,假设使用 A100 训练,A100-80G 的计算能力是 312T FLOS(每秒可进行 312T 次FP16浮点计算),那么:
GPU hours = (模型参数量*训练数据量 *6)/(312T * 3600 (0.3~0.55))
= 26706~14567 GPU hours
其中
模型参数量 = 3B
原创文章,作者:产品二姐,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/8524.html