特别活动!
欢迎观看大模型日报 , 如 需 进 入 大 模 型 日 报 群 和 空 间 站 请 直 接 扫 码 。 社 群 内 除 日 报 外 还 会 第 一 时 间 分 享 大 模 型 活 动 。
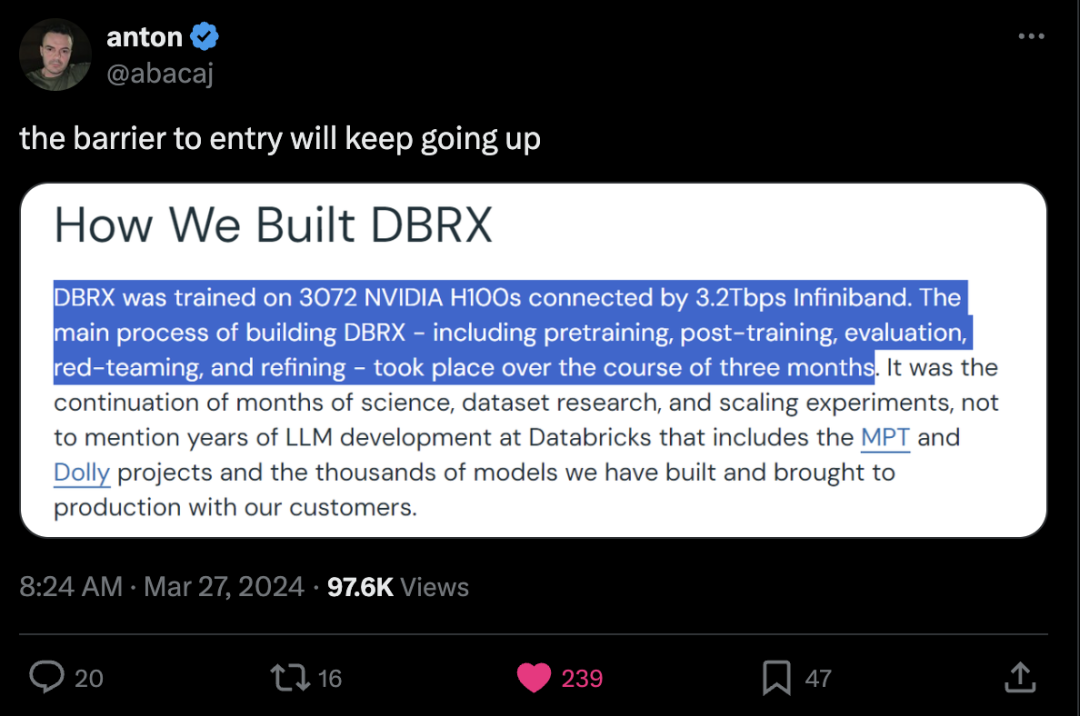
推特 Databricks上线DBRX:专家混合模型,标准基准测试中击败所有开源模型 今天我们发布了一个开源模型 DBRX,在标准基准测试中击败了之前所有的开源模型。该模型本身是一个专家混合模型(Mixture of Experts,MoE),其”大脑”大约是 Llama2-70B 的两倍(132B),但成本却只有一半(36B)。这使得它既聪明又便宜。由于实际使用的专家参数只有36B,其速度(tokens/seconds)接近 Llama2-70B 的两倍。我们很高兴能为拥有专有数据的组织定制此模型的特殊版本! 使用为您的独特数据定制的 DBRX,构建高质量的生成式AI应用:Databricks 的使命是通过让组织理解和使用其独特的数据来构建自己的 AI 系统,从而为每个企业提供数据智能。今天,我们很高兴通过开源 DBRX 来推进我们的使命。DBRX 是由我们的 Mosaic Research 团队构建的通用大语言模型(LLM),在标准基准测试中优于所有已建立的开源模型。我们相信,突破开源模型的界限可以为所有企业实现可定制且透明的生成式AI。 h ttps://x.com/alighodsi/status/1772973004613656879?s=20
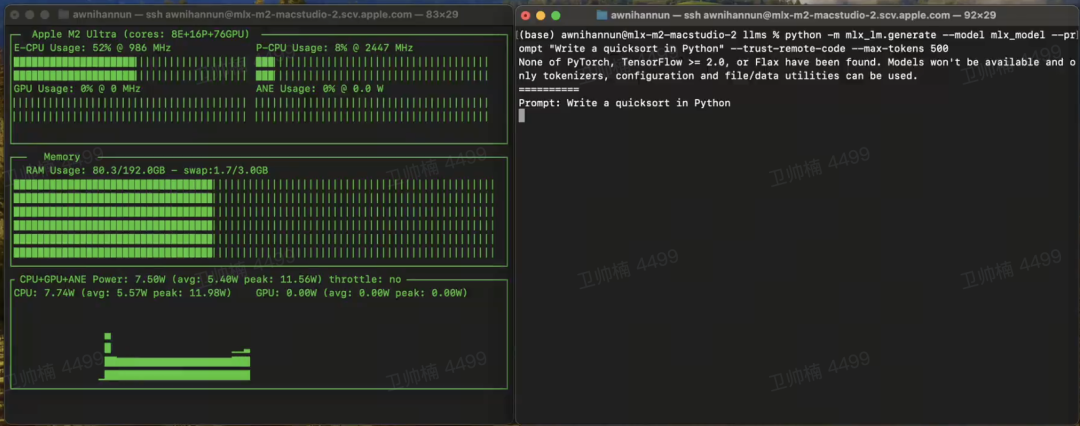
相关评论 – DBRX 链接:https://x.com/awnihannun/status/1773024954667184196?s=20 4位量化的 DBRX 在 M2 Ultra 的 MLX 上运行良好。拉取请求: https://github.com/ml-explore/mlx-examples/pull/628
HuggingFace Tech Lead Phillipp:关于 Databricks (DBRX)模型,有两点我真心觉得最令人印象深刻:
它展示了开源和开放科学如何加速 AI 进步,并让我们能够在彼此的工作基础上继续构建,就像从 @Tgale96 的 MegaBlocks 到 Mixtral 再到 DBRX 的演变过程。
他们仅用了2-3个月的时间就创建并训练出了这个模型!大约一年前这还是不可能的。
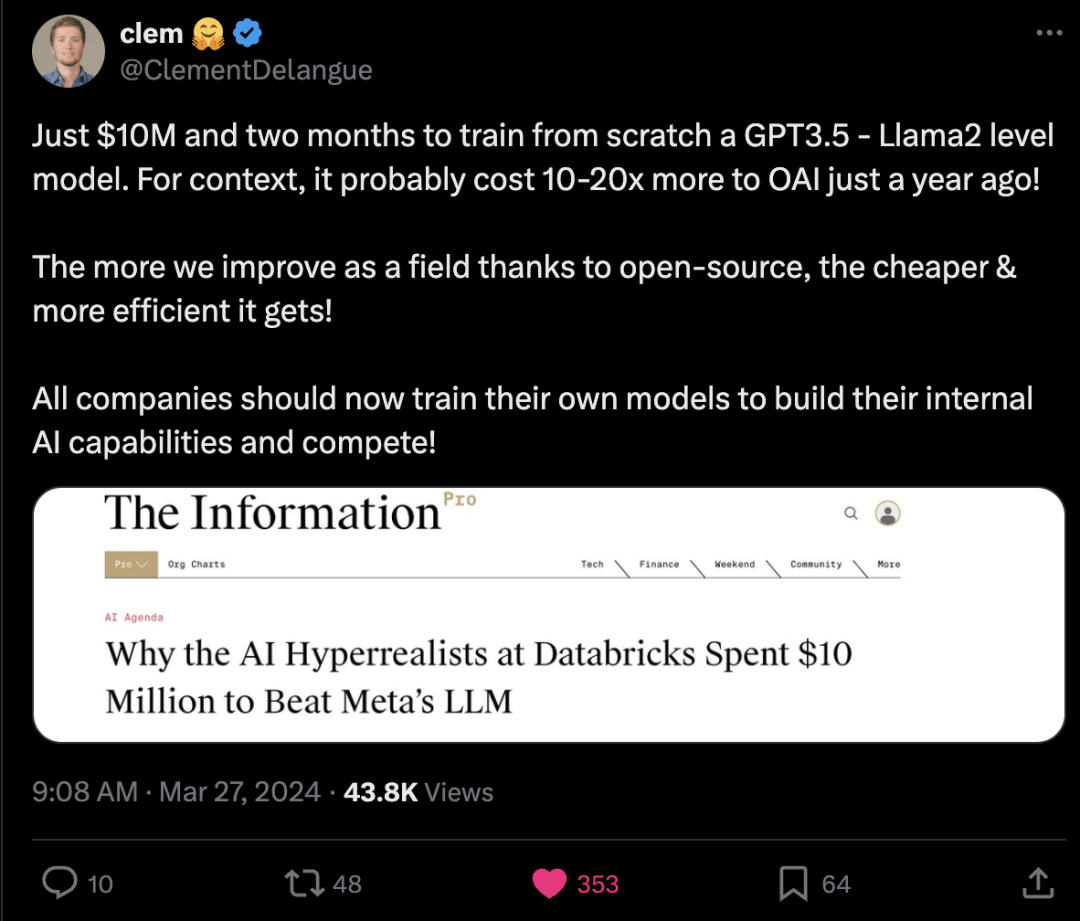
https://x.com/_philschmid/status/1773239161945792763?s=20 HuggingFace Clement:从零开始训练出一个 GPT3.5 – Llama2 级别的模型,只需1000万美元和两个月的时间。作为对比,仅在一年前,OpenAI可能还需要花费10-20倍的成本! 随着开源的帮助,我们在这个领域的进步越大,训练模型就变得越便宜、越高效! 现在所有公司都应该训练自己的模型,以构建内部AI能力并参与竞争! https://x.com/ClementDelangue/status/1773019321511313467?s=20 https://x.com/abacaj/status/1773008096597598658?s=20 Daniel Han:看了一下 @databricks 的新开源1320亿参数模型 DBRX!
合并的注意力 QKV,在 (-8, 8) 之间进行了钳位
不是 RMS LayerNorm – 现在与 Llama 不同,去除了均值
16个专家中有4个活跃。Mixtral 是8个专家中有2个。
使用了 @OpenAI 的 TikToken 分词器,词表大小为10万。Llama 会切分数字。TikToken 允许1、2和3位数字。原生支持 ChatML 格式。
损失平衡系数为0.05,而 Mixtral 为0.02。
使用了 @UnslothAI 在我们修复 Gemma 错误时发现的正确的 RoPE 向上转换!
训练了12万亿个 tokens!博客中说高质量数据最重要。
https://github.com/databricks/dbrx/blob/main/model/modeling_dbrx.py
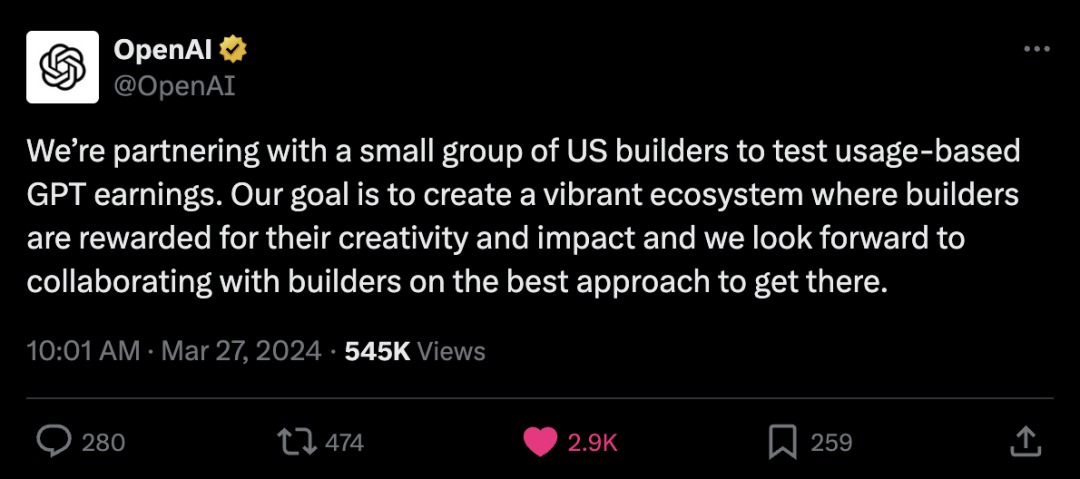
https://x.com/danielhanchen/status/1772981050530316467?s=20 GPT Store开启收益:OpenAI与美国开发者合作,测试基于使用量的GPT收益 我们正与一小群美国开发者合作,测试基于使用量的GPT收益。我们的目标是创建一个充满活力的生态系统,在这个系统中,开发者可以因其创造力和影响力而获得回报。我们期待与开发者合作,找到实现这一目标的最佳方法。 https://x.com/OpenAI/status/1773032605002203559?s=20 Hume上线“同情心语音接口”(EVI):第一个具有情感智能的对话式AI,Schiffmann:我们被情感而非内容所说服 这是 Hume 的同情心语音接口(EVI),第一个具有情感智能的对话式AI。 EVI 能理解用户的语气,这为每一个词都增添了意义,并用它来指导自己的语言和语音。开发者可以使用我们的 API 作为任何应用程序的语音接口。在这里试试看:
对你的表达做出反应,使用能满足你需求并最大化满意度的语言
EVI 知道什么时候说话,因为它使用你的语气进行最先进的语句结束检测
当然,它还包括快速、可靠的转录和文本到语音转换,并且可以连接到任何大语言模型。现已上线,网址为 我们被情感而非内容所说服。这项技术将变得如此强大,我不会惊讶欧盟会对它的应用进行监管。快去试试吧。 h ttps://x.com/hume_ai/status/1773017055974789176?s=20
OpenAI联创Karpathy红杉AI Ascent对话:对生态系统的未来预测,规模是唯一重要的吗,如何与OpenAI竞争 主持 @Sequoia AI Ascent 的一大亮点是与我的朋友 @Karpathy 聊天。我们聊到了他对生态系统的未来预测(一个 LLM 操作系统!),房间里的大象问题(规模是唯一重要的吗?作为一家年轻的初创公司,如何与 OpenAI 等竞争?),与🐐(Elon!)共事时学到的领导力经验,以及在他的下一章中对他个人而言最重要的东西(提示:🪸)。 https://x.com/karpathy/status/1773117863231914337?s=20
Llama Index & DeepLearningAI课程: 在使用LlamaIndex的JavaScript RAG Web应用中构建一个使用RAG的全栈Web应用 新的JavaScript短期课程:在使用LlamaIndex的JavaScript RAG Web应用中构建一个使用RAG的全栈Web应用,由Llama Index 的开发者关系副总裁兼npm联合创始人Laurie Voss 讲授。
构建一个RAG应用来查询你自己的数据
开发工具,使用一个智能选择正确工具来回答你查询的代理来与多个数据源进行交互
创建一个可以与你的数据聊天的全栈Web应用
深入探讨生产就绪的技术,比如如何持久化你的数据,这样你就不需要不断重建索引,并尝试使用LlamaIndex的create-llama命令行工具
Jerry Liu:在notebook中构建RAG很容易,但这如何转化为一个可用的全栈应用(后端/API设置、前端)?我们全新的@DeepLearningAI 课程是同类课程中的第一个——不仅仅学习RAG技术,而是学习如何围绕这些技术构建一个完整的Web应用
构建一个后端API,一个交互式的React组件,并了解在服务器而不仅仅是笔记本中构建RAG时的独特挑战。
https://x.com/jerryjliu0/status/1773021956050464776?s=20
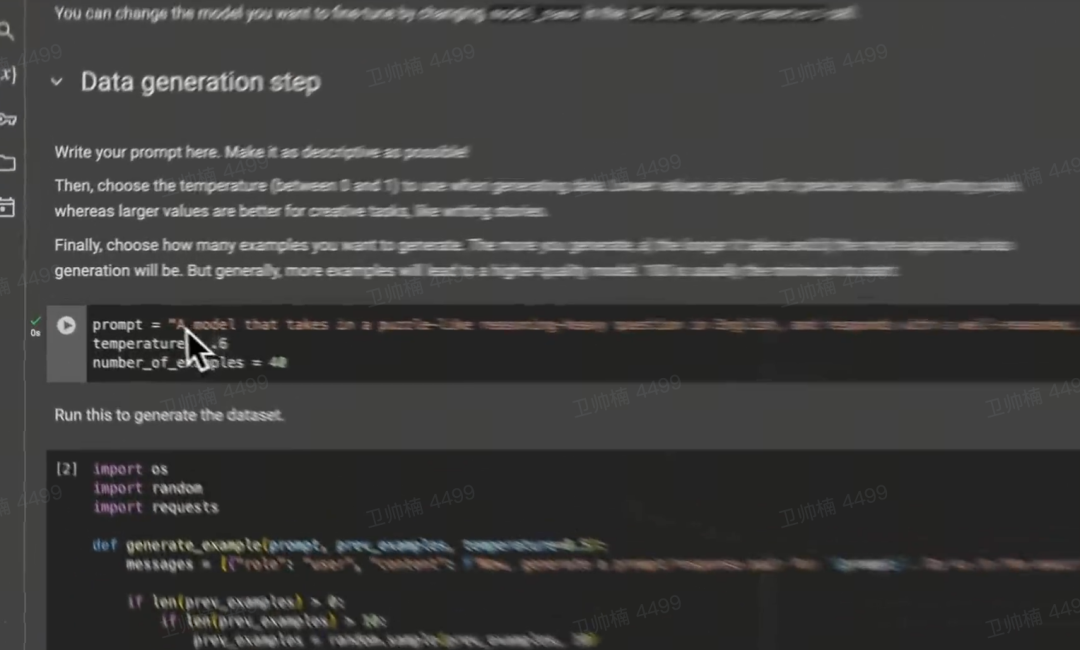
Claude-llm-trainer:只需写一个句子描述想要的模型,AI 系统链将生成数据集并训练模型 https://x.com/mattshumer_/status/1773017544888082933?s=20
MLCommons 正在为 MLPerf Inference 基准测试采用 Meta Lla ma 2 70B @MLCommons 正在为 MLPerf Inference v4.0 采用 Meta Llama 2 70B ➡️ https://bit.ly/3xgaXa3 该基准测试是衡量跨领域的机器学习和人工智能性能的标准,我们很高兴能支持社区将 Llama 2 作为基准测试套件的一部分。 https://x.com/AIatMeta/status/1773024662689124451?s=20 又一开源AI可穿戴设备上线:Tilt,支持Cornell 笔记、待办事项列表等 介绍 Tilt,一款售价199美元的AI可穿戴设备,可作为你的笔记应用,将你的生活经历转化为个人AI,让你拥有完美的记忆力 https://x.com/Karmedge/status/1772917605520572774?s=20
论文 大语言模型中的长篇事实性 大语言模型(LLMs)在回答有关开放主题的事实搜索提示时,经常会生成包含事实错误的内容。为了在开放领域对模型的长篇事实性进行基准测试,我们首先使用GPT-4生成了LongFact,这是一个包含数千个问题跨越38个主题的提示集。然后我们提出,智能体LLM可以通过一种名为Search-Augmented Factuality Evaluator(SAFE)的方法作为长篇事实性的自动评估器。SAFE利用LLM将长篇回答分解为一组个别事实,并通过发送搜索查询到Google搜索并确定事实是否受到搜索结果支持的多步推理过程来评估每个事实的准确性。此外,我们提出扩展F1分数作为长篇事实性的聚合指标。为此,我们在回应中平衡受支持事实的百分比(精度)与提供的事实百分比相对于代表用户偏好的回应长度的超参数(召回率)。实证上,我们证明LLM智能体可以实现超人类评级表现-在约16k个独立事实集上,SAFE有72%的时间与众包人工标注者达成一致,在100个不一致情况的随机子集上,SAFE有76%的胜率。同时,SAFE比人工标注者便宜20多倍。我们还在LongFact上对十三种语言模型进行基准测试,包括Gemini,GPT,Claude和PaLM-2等四个模型系列,发现较大的语言模型通常实现更好的长篇事实性。LongFact,SAFE以及所有实验代码都可以在https://github.com/google-deepmind/long-form-factuality 找到。 http://arxiv.org/abs/2403.18802v1 更快的收敛速度:利用线性搜索方法进行Transformer微调 最近的研究表明,线搜索方法极大地提高了传统随机梯度下降方法在各种数据集和架构上的性能。本研究成功地将线搜索方法扩展到了新颖且广受欢迎的Transformer架构和自然语言处理领域的数据集。具体来说,我们将Armijo线搜索与Adam优化器结合,并通过将网络架构细分为合理单元,在这些本地单元上分别执行线搜索。我们的优化方法优于传统的Adam优化器,在小数据集或小训练预算上取得了显著的性能改进,同时在其他测试案例中表现相等或更好。我们的工作作为一个Python软件包公开可用,提供了一个无超参数的PyTorch优化器,与任意网络架构兼容。 http://arxiv.org/abs/2403.18506v1 学习自我完善的代码生成:CYCLE 预训练代码语言模型在代码生成方面取得了令人满意的表现,提高了人类开发者的编程效率。然而,现有对代码LM的评估通常忽略了它们的自我完善能力,而只专注于一次性预测的准确性。在代码LM无法实现正确程序的情况下,开发者实际上很难调试和修复错误的预测,因为它不是由开发者自己编写的。不幸的是,我们的研究表明,代码LM也无法有效地自我完善它们的错误生成。 本文提出了CYCLE框架,根据可用反馈(如测试套件报告的执行结果)学习自我完善故障生成。我们在三个流行的代码生成基准HumanEval、MBPP和APPS上评估CYCLE。结果显示,CYCLE成功地维持了一次性代码生成的质量,有时还有所提高,同时显著提高了代码LM的自我完善能力。我们实现了四个变体的CYCLE,参数数量分别为350M、1B、2B和3B,实验表明CYCLE在各种基准和不同模型尺寸下能够一贯提升代码生成性能,最高可达63.5%。我们还注意到,CYCLE在自我完善方面胜过了参数是其3倍的代码LM。 http://arxiv.org/abs/2403.18746v1 COIG-CQIA:质量是中文指令微调所需的全部 最近,在大语言模型(LLMs)方面取得了重大进展,特别是针对英语。这些进展使得这些LLMs能够以前所未有的准确性和流畅度理解和执行复杂指令。然而,尽管取得了这些进展,中文指令微调的发展仍存在明显差距。中文语言的独特语言特征和文化深度给指令微调任务带来挑战。为了弥合这一差距,我们推出了COIG-CQIA,一个高质量的中文指令微调数据集。我们的目标是构建一个多样化、广泛的指令微调数据集,以更好地与人类互动行为相吻合。我们从各种中国互联网来源中收集高质量的人类书面语料库,经过严格过滤和精心处理形成了COIG-CQIA数据集。此外,我们在CQIA的不同子集上训练各种规模的模型,并进行深入评估和分析。我们的实验发现为选择和开发中文指令微调数据集提供了宝贵的见解。我们还发现在CQIA-Subset上训练的模型在人类评估以及知识和安全基准测试方面取得了竞争力的成绩。数据可在https://huggingface.co/datasets/m-a-p/COIG-CQIA获取。 http://arxiv.org/abs/2403.18058v1 稠密检索的扩展定律 摘要:将神经模型进行规模化可以在许多任务中取得显著进展,特别是在语言生成领域。先前的研究发现,神经模型的性能经常遵循可预测的规模定律,与训练集大小和模型大小等因素相关。然而,在密集检索领域,由于检索指标的离散性质和训练数据与模型大小在检索任务中的复杂关系,这种规模定律尚未得到充分探讨。在本研究中,我们调查了密集检索模型的性能是否遵循其他神经模型的规模定律。我们建议使用对比对数似然作为评估指标,并对具有不同参数数量和使用不同数量已标注数据训练的密集检索模型进行广泛实验。结果表明,在我们的设置下,密集检索模型的性能符合与模型大小和注释数量相关的精确幂律规模定律。此外,我们还研究了流行的数据增强方法对规模化的影响,并应用规模定律找到在预算约束下的最佳资源分配策略。我们相信这些见解将有助于深入了解密集检索模型的规模效应,并为未来的研究提供有意义的指导。 http://arxiv.org/abs/2403.18684v1
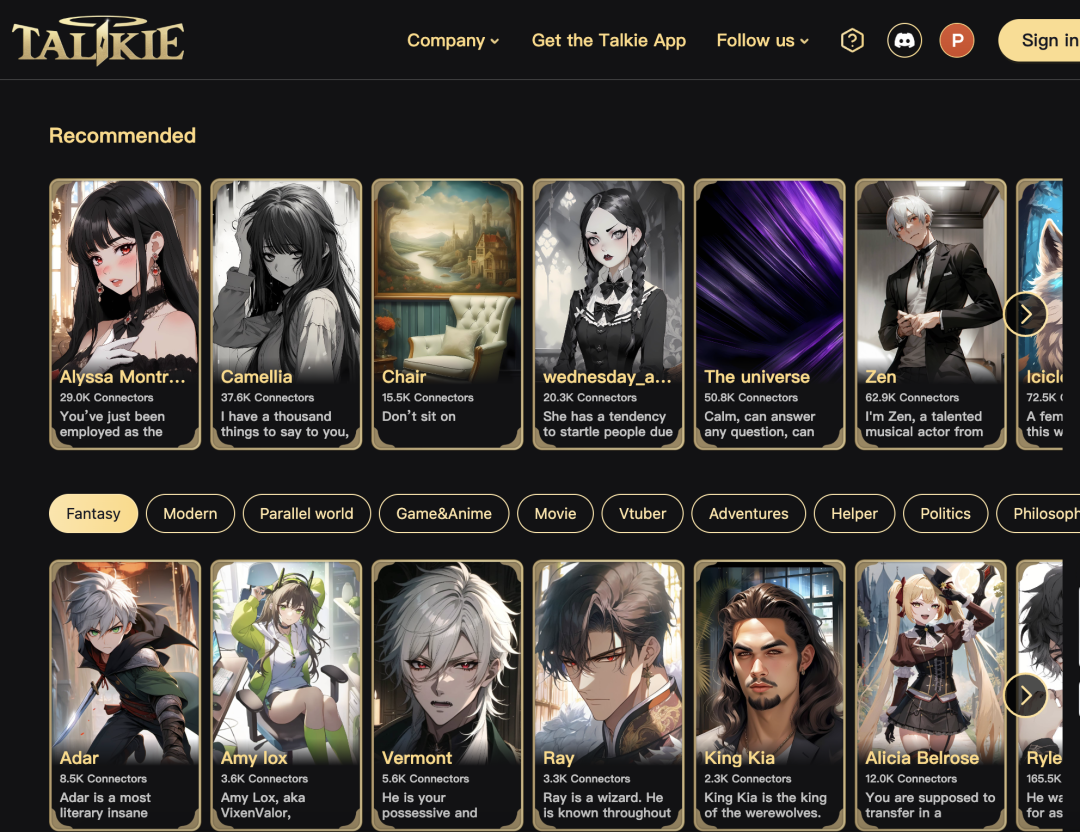
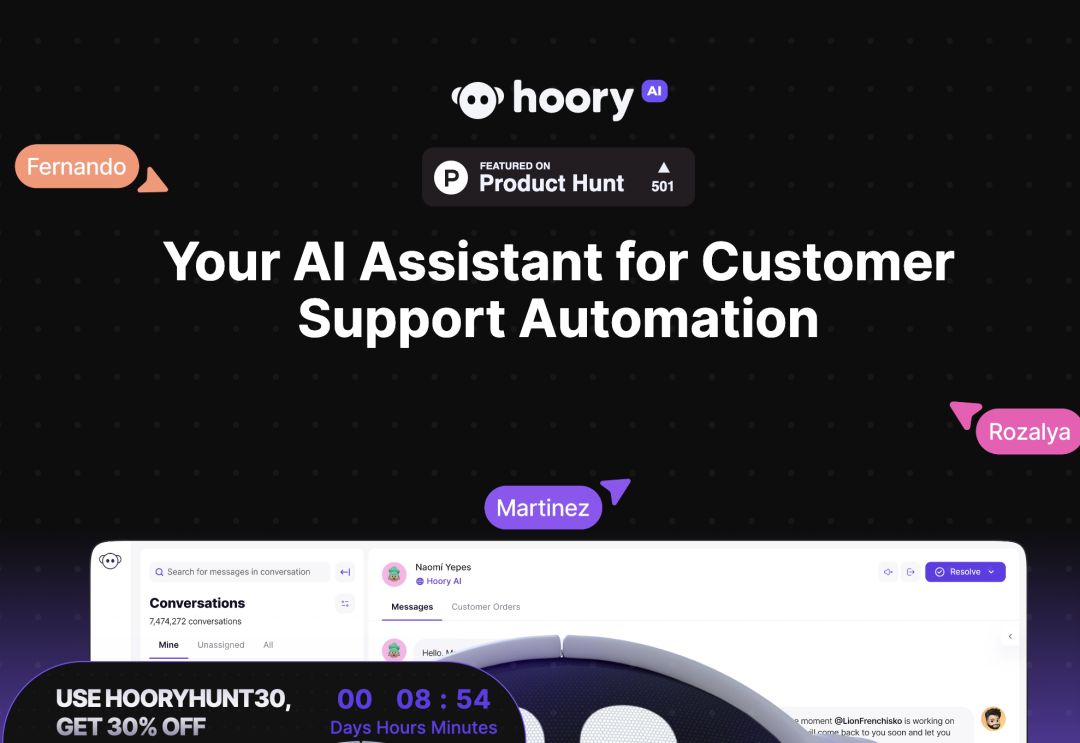
SDSAT:通过语义自适应 token 的推测解码加速 LLM 推理 我们提出了一种加速大语言模型(LLMs)的方案,通过具有语义自适应token的猜测解码(SDSAT)。该设计的主要目标是增强LLM模型生成草案token的准确性,同时不影响模型的准确性。核心策略包括:1)通过添加具有灵活解码能力的语义自适应token对模型进行微调,而不改变模型结构,使其能够生成高质量草案token。2)通过采用一种不影响标准token的训练方法,模型可以在其原始框架上获得并行解码能力,训练开销最小化。3)我们设计了“两步走-生成然后验证”生成策略,使用贪婪搜索和核采样。在CodeLlama-13B和7B模型上进行的实验表明,速度分别提高了3.5倍和3.0倍。请参阅 https://github.com/hasuoshenyun/SDSAT http://arxiv.org/abs/2403.18647v1 产品 Talkie AI Talkie 是一个 AI 角色互动创作平台,用户可以在其中使用先进的视觉和音频工具创建个性化角色。从打造理想伴侣到身临其境的角色扮演,享受与角色的音频和视觉互动带来的全新体验。该平台提供多模态功能,让用户可以设计外表、声音和思维,打造独特的人工智能伴侣。除了与 AI 进行冒险和互动,您还可以捕捉珍贵时刻并分享独特视觉天赋的图片,新增了电话语音功能,可以给喜欢的角色打电话实时沟通。 https://www.talkie-ai.com/ Hoory AI Hoory是一款基于 AI 的客服助手,可以实现根据业务特性自动化完成跟客户的沟通,并提供全天候零延迟支持,将每次互动转化为更好的客户体验。它利用对话式人工智能、机器学习和自然语言处理技术,不仅实现自动化,还能理解客户意图,提供相关答案,增强客户忠诚度,节省时间并降低业务成本。 https://producthunt.hoory.com/ H uggingFace&Github TC4D—文生 4D TC4D 是最近关于文本到 4D 生成的技术,通过使用预训练的文本到视频模型进行监督,这些技术合成了动态的3D场景。现有的运动表示形式(如变形模型或时间相关的神经表示)在能够生成的运动量上存在局限性,无法合成远超过用于体积渲染的边界框的运动。缺乏更灵活的运动模型导致了 4D 生成方法与最近的、近乎照片般逼真的视频生成模型之间现实感差距的存在。团队提出了 TC4D:轨迹条件文本到 4D 生成,将运动分解为全局和局部组件。他们使用样条线来表示场景边界框的全局运动,并学习符合全局轨迹的局部变形,通过文本到视频模型进行监督。这种方法使得能够合成沿任意轨迹动画的场景、进行组合式场景生成,并显著改善了生成的运动的逼真程度和数量,作者通过定性评估和用户研究来评估这一点。 https://sherwinbahmani.github.io/tc4d/ DBRX DBRX 是一个基于 Transformer 的仅解码器大型语言模型 (LLM),它使用 next-token 预测进行训练。它使用细粒度的专家混合 (MoE) 架构,总参数为 132B,其中 36B 参数在任何输入上都处于活动状态。它是在 12T 文本和代码数据标记上预先训练的。与 Mixtral-8x7B 和 Grok-1 等其他开放式 MoE 模型相比,DBRX 是细粒度的,这意味着它使用更多的小型专家。 https://huggingface.co/databricks/dbrx-instruct 投融资 Hume AI宣布筹集了5000万美元的资金用于新产品EVI 我们很高兴地宣布,我们筹集了5000万美元的资金,用于推出我们的新旗舰产品——一个可以集成到任何应用程序中的同理心语音界面(EVI)。 https://x.com/hume_ai/status/1773024409986466205?s=20 智谱 AI 参投“清程极智”首轮融资,其入股企业已超 10 家 清程极智科技有限公司,成立于2023年12月,由清华大学计算机系博士团队创立,专注于AI基础设施(AI Infra)技术的研发与创新。该公司旨在构建高效AI系统软件,支撑大模型行业发展,赋能国产算力。拥有全栈研发团队,技术涵盖并行系统、AI编译器等关键领域,特别强调国产智能算力芯片的性能优化和代码可移植性,以降低AI技术落地门槛,推动行业进步。 https://www.myzaker.com/article/6603d9f38e9f09659d6f7ff8
为机器人提供“通用大脑”,「X Square」连续完成数千万元天使轮与天使+轮融资 X Square,一家专注于“通用具身大模型”研发的初创企业,近期完成了数千万元人民币的天使轮与天使+轮融资,由联想之星和九合创投领投。成立于2023年12月的X Square旨在为机器人提供一个通用的“大脑-小脑”系统,以实现从感知到动作的端到端能力。公司的研发重点是解决机器人在感知环境、操作物体等本能能力上的AI挑战,旨在推动具身智能领域的发展。X Square的研究重点在于软硬一体化以及大模型在机器人操作中的应用,期望通过自研的通用模型平台,让机器人能完成复杂而精细的物理操作。此外,公司的目标不仅是技术领域的创新,也致力于将具身智能应用于商业化,预计在3-5年内实现初步商业化落地。 晶音智能宣布获秭方资本战略投资 福州晶音智能科技有限公司宣布成功获得秭方资本900万元的战略投资。这一合作标志着双方在智能科技领域的共同探索和无限可能。晶音智能凭借其在AI智能科技领域的创新力量和技术优势,受到了秭方资本的高度认可。此次战略投资不仅为晶音智能提供了发展的坚实保障,也为其带来了更多市场的发展机会,助力公司成为行业的标杆,推动智能科技更好地服务于人类生活。 Celestial AI 完成1.75亿美元C轮融资 Celestial AI成功获得1.75亿美元的C轮融资,该轮融资由美国创新技术基金(USIT)领投,同时吸引了包括AMD Ventures、Koch Disruptive Technologies在内的多家新老投资者参与。此次融资将加速Celestial AI的光子织布技术平台商业化进程,这是一种创新的光学互联技术,用于解决当前高级AI模型由于I/O带宽和内存容量限制而面临的挑战。光子织布技术以其前所未有的性能和效率,正在成为加速计算领域光互联的标准,为下一代数据中心和生成式AI应用的需求提供解决方案。通过这项技术,Celestial AI不仅推动了AI技术的发展,也为实现可扩展、可持续且盈利的新商业模式奠定了基础。 公司官网:https://www.celestial.ai/ https://www.celestial.ai/blog/celestial-ai-closes-175-million-series-c-funding-round-led-by-us-innovative-technology-fund
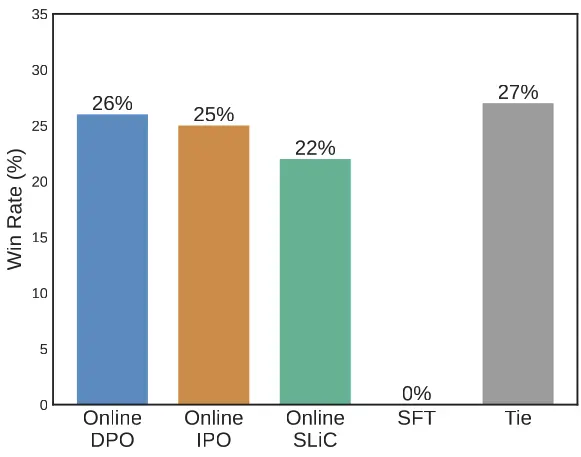
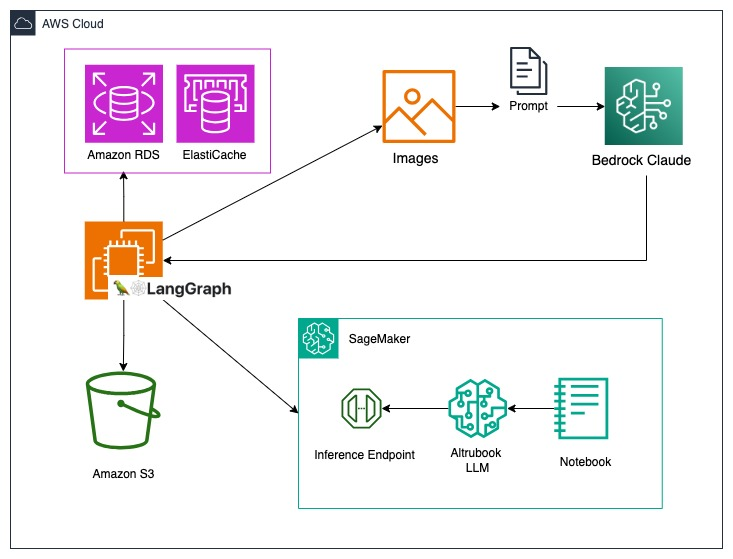
MyShell完成1100万美元Pre-Series A融资 MyShell,一家去中心化AI消费层公司,宣布在由Dragonfly领投的Pre-Series A轮融资中筹集到1100万美元。本轮融资还得到了Delphi Ventures、Bankless Ventures、Maven11 Capital等高调投资者的参与。MyShell致力于通过开源模型和代理平台,赋能AI创作者社区,目前已拥有超过100万注册用户和50000名创作者。公司计划利用这笔新资金进一步开发其开源基础模型,加强对AI创作者的支持,以及促进开源社区的发展。 https://cryptoslate.com/press-releases/myshell-raises-11-million-for-its-decentralized-ai-consumer-layer/ 学习 为什么我们应该做online RLHF/DPO? 文章探讨了在线偏好学习(online RLHF/DPO)的重要性与技术细节,强调在线数据加入RLHF中的好处。通过定义偏好学习、数据收集方式及其与标准训练任务的差异,文章展示了Bradley-Terry模型下奖励函数优化的框架,并详细讨论了线上与线下、策略内与策略外学习的区别。重点在于,通过线上学习,可以在训练过程中让人为标注偏好信号,与仅依赖给定数据集的线下学习相比,线上学习有助于提高模型性能。文章还提出了“批量混合训练”方法,结合线上线下数据,以及探讨了在线探索策略设计的重要性,指出有效的探索策略对于优化模型性能至关重要。 https://zhuanlan.zhihu.com/p/688806682 LLM推理入门指南②:深入解析KV缓存 文章深入讨论了在LLM推理过程中应对计算成本问题的一种常用优化方式——KV缓存。作者指出,大型语言模型(LLM)推理面临的主要挑战之一是,注意力层计算成本随序列长度的增加而呈二次方扩展。幸运的是,通过缓存适当的结果(即键值对),可以在某种程度上将这种计算需求从二次方扩展优化为线性扩展。KV缓存机制通过在生成过程中计算出的键(K)和值(V)张量存储于GPU内存中,减少了对过去词元键和值张量的重新计算需求,实现了内存换取计算的折衷方案。文章还讨论了KV缓存可能带来的挑战以及应对这些挑战的常见策略。 聊聊 MoE 技术和算法总结 文章深入探讨了混合专家模型(Mixture-of-Experts, MoE)的最新技术进展和应用。其中,重点介绍了MegaBlocks技术,这是一种在单GPU上高效训练含有多个专家的MoE模型的方法,通过专家容量和优化场景的概念来提高训练效率和模型性能。此外,文章还提到了ScatterMoE实现,该实现通过减少内存占用和提升吞吐量来优化MoE模型的训练和推理速度。Branch-Train-MiX (BTX)方法也被提及,它通过分支、训练和混合专家的方式来实现从领域专家到MoE模型的有效转换,以此来平衡精度和效率。这些技术展示了MoE模型在处理大规模训练任务时的巨大潜力和挑战。 https://zhuanlan.zhihu.com/p/689096518 大模型训练之FP8-LLM别让你的H卡白买了:H800的正确打开方式 文章探讨了如何通过使用FP8数据类型和NVIDIA的TransformerEngine库最大化H100 GPU的性能。H100 GPU引入的FP8数据类型,在矩阵乘积累加(MMA)计算速率上相比A100 GPU的16位浮点运算速率快4倍,主要贡献于FP8的使用和Sparsity特性。文章强调了FP8数据类型的重要性,特别是对于大型语言模型(LLM)的训练,能够显著减少内存需求和通信成本,从而提高训练效率。此外,讨论了混合精度训练和动态Loss Scaling的概念,展示了FP8如何在减少计算资源消耗的同时保持或提高模型训练的效率和准确性。 https://zhuanlan.zhihu.com/p/664972481 Amazon Bedrock Claude3 结合多智能体 Multi-agent 助力 Altrubook.AI 定义消费者 AI 新范式 Altrubook AI 是一款创新的智能消费决策机器人,它利用 Amazon Bedrock Claude3 的多模态对话能力与领域决策模型无缝集成,为用户提供沉浸式的购物体验和个性化购物决策服务。通过高级人工智能算法,Altrubook AI 能在虚拟购物场景中智能捕捉消费需求,提供个性化商品推荐,并规划出性价比最优的购物方案。该技术整合了 Multi-agent 系统和大语言模型,实现了对信息的高效处理和决策建议的生成,为消费者带来全新的购物体验。 https://aws.amazon.com/cn/blogs/china/amazon-bedrock-claude3-combines-multi-agent-to-help-altrubook-ai-define-a-new-paradigm-of-consumer-ai/
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/03/16581.html