
大模型周报是由奇绩创坛大模型日报内容精选而成,如需进入大模型日报群和空间站请文末扫码。
1
资讯
从 Altman 对 GPT-5 的剧透中,我们应该如何迎接 AGI 的下一阶段?(必看)
前几天的 2024 达沃斯世界经济论坛上,Sam Altman 谈到了 GPT 发展的一些新的方向及可能性,对于当下大模型的一些现状的分析。


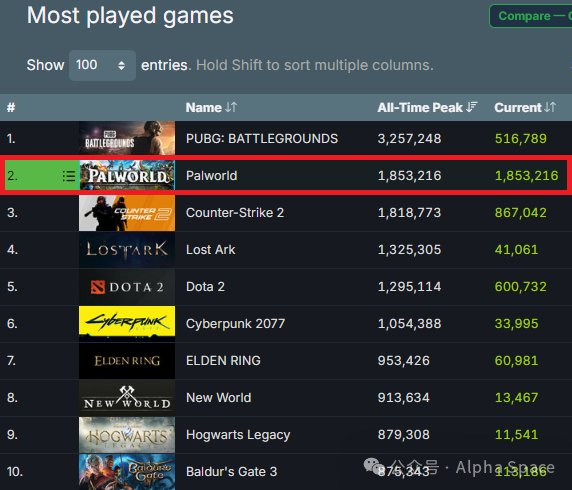
《幻兽帕鲁》爆火,大厂坐不住了:这游戏是AI设计的?
最近,很多社交网络平台都被一款开放世界生存游戏刷了屏。《幻兽帕鲁》(Palworld)是当下最热门的话题之一,它在 1 月 19 日于 Steam 上线抢先体验版本,24 小时之内销量就超过了 200 万份,几天之内就突破了 600 万。在 1 月 23 日,幻兽帕鲁的 Steam 历史在线峰值就达到了 185 万人,超越了《CS 2》,成为了 Steam 历史在线玩家峰值第二的游戏。除了出乎预料的火爆,另一个让人难以想象的就是,幻兽帕鲁出自一个「小作坊」,项目开工的时候全公司只有 10 个人。在幻兽帕鲁游戏中,作者设计出了一个内容丰富、生机勃勃(也充满既视感)的世界。
https://mp.weixin.qq.com/s/xubT7_wIMBSOkyvl51LrMQ
大模型推理速度飙升3.6倍,「美杜莎」论文来了,贾扬清:最优雅加速推理方案之一
在本文中,来自普林斯顿大学、Together.AI、伊利诺伊大学厄巴纳 – 香槟分校等机构的研究者没有使用单独的草稿模型来顺序生成候选输出,而是重新审视并完善了在主干模型之上使用多个解码头加速推理的概念。他们发现,如果该技术得到有效应用,可以克服推测解码的挑战,从而无缝地集成到现有 LLM 系统中。具体来讲, 研究者提出了 MEDUSA,一种通过集成额外解码头(能够同时预测多个 tokens)来增强 LLM 推理的方法。这些头以参数高效的方式进行微调,并可以添加到任何现有模型中。至此,不需要任何新模型,MEDUSA 就可以轻松地集成地当前的 LLM 系统中(包括分布式环境),以确保友好用户体验。值得关注的是,该论文作者之一 Tri Dao 是近来非常火爆的 Transformer 替代架构 Mamba 的两位作者之一。他是 Together.AI 首席科学家,并即将成为普林斯顿大学计算机科学助理教授。

http://arxiv.org/abs/2401.10774v1
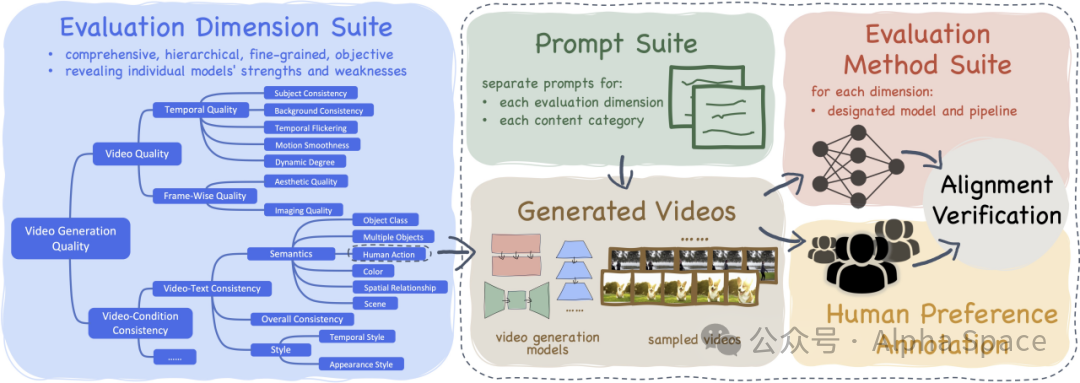
Pika、Gen-2、ModelScope、SEINE……AI视频生成哪家强?这个框架一测便知
AI 视频生成,是最近最热门的领域之一。各个高校实验室、互联网巨头 AI Lab、创业公司纷纷加入了 AI 视频生成的赛道。Pika、Gen-2、Show-1、VideoCrafter、ModelScope、SEINE、LaVie、VideoLDM 等视频生成模型的发布,更是让人眼前一亮。为此NTU联合上海AI Lab,CUHK以及南京大学推出了 VBench,一个全面的“视频生成模型的评测框架”,来告诉你:视频模型哪家强,各家模型强在哪。
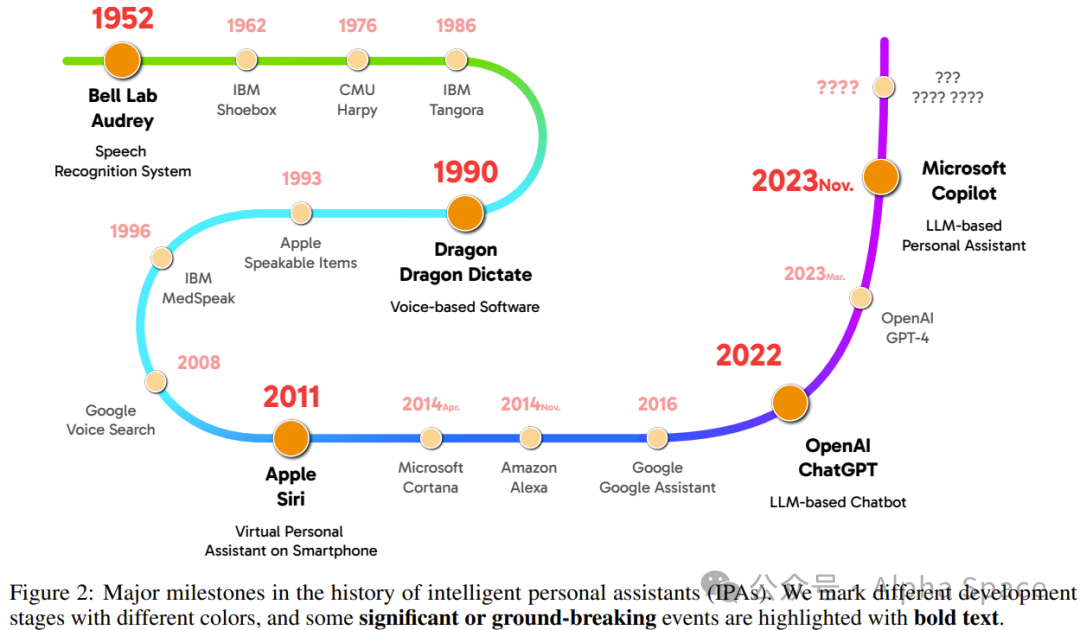
清华、小米、华为、 vivo、理想等多机构联合综述,首提个人LLM智能体、划分5级智能水平
想必这些唤醒词中至少有一个曾被你的嘴发出并成功呼唤出了一个能给你导航、讲笑话、添加日程、设置闹钟、拨打电话的智能个人助理(IPA)。可以说 IPA 已经成了现代智能手机不可或缺的标配,近期的一篇综述论文更是认为「个人 LLM 智能体会成为 AI 时代个人计算的主要软件范式」。这篇个人 LLM 智能体综述论文来自国内多所高校和企业研究所,包括清华大学、小米、华为、欢太、vivo、云米、理想汽车、北京邮电大学、苏州大学。文中不仅梳理了个人 LLM 智能体所需的能力、效率和安全问题,还收集并整理了领域专家的见解,另外还开创性地提出了个人 LLM 智能体的 5 级智能水平分级法。该团队也在 GitHub 上创建了一个文献库,发布了相关文献,同时也可供 IPA 社区共同维护,更新最新研发进展。
2
论文
Unitxt:用于生成AI的灵活、可共享和可重用的数据准备和评估
在生成式自然语言处理(NLP)的不断变化的领域中,传统的文本处理流程限制了研究的灵活性和可复现性,因为它们是为特定的数据集、任务和模型组合量身定制的。随着日益复杂化的环境,涉及系统提示、特定模型格式、指示等等,我们需要转向一种结构化、模块化和可定制的解决方案。为了满足这一需求,我们提出了Unitxt,一种创新的库,用于定制化的文本数据准备和评估,特别适用于生成式语言模型。Unitxt与HuggingFace和LM-eval-harness等常用库进行本地集成,并将处理流程分解为模块化组件,实现了易于定制和实践者之间的共享。这些组件包括特定模型的格式、任务提示以及许多全面的数据集处理定义。Unitxt-Catalog集中了这些组件,促进了现代文本数据处理流程的协作和探索。除了作为一个工具外,Unitxt还是一个社区驱动的平台,赋予用户协作建立、分享和推进他们的流程的能力。
http://arxiv.org/abs/2401.14019v1
AutoRT:用于大规模机器人智能体编排的具体化基础模型
基于语言、视觉和最近引入的动作的基础模型彻底改变了利用互联网规模数据进行有用任务推理的能力。然而,训练具有具体实物背景的基础模型的关键挑战之一是缺乏基于物理世界的数据。在本文中,我们提出了AutoRT,这是一个利用现有基础模型来扩大操作机器人在完全未知场景中部署的系统,减少人工监督。AutoRT利用视觉语言模型(VLMs)进行场景理解和赋予意义,并进一步使用大语言模型(LLMs)为机器人群体提供多样化和新颖的指令。通过利用基础模型的知识来指导数据收集,AutoRT能够有效地推理出自主权衡和安全性,并显着扩大机器人学习的数据收集规模。我们通过AutoRT向多个建筑物中的20多个机器人提出指令,并通过遥操作和自主机器人策略收集了77k个真实机器人剧集。实验证明,AutoRT收集的“野外”数据更加多样化,并且AutoRT使用LLMs允许机器人按照人类偏好执行指令的数据收集。
http://arxiv.org/abs/2401.12963v1
Lumiere: 一个用于视频生成的时空扩散模型
我们介绍了Lumiere——一种用于合成逼真、多样和连贯运动的视频的文本到视频扩散模型。为此,我们引入了一种空时U-Net架构,通过模型中的单次传递一次性生成整个视频的时间持续。这与现有的视频模型不同,后者合成远程的关键帧,然后进行时间超分辨率处理,这种方法本质上使得全局时间一致性难以实现。通过同时部署空间和(重要的)时间下采样和上采样,并利用预训练的文本到图像扩散模型,我们的模型通过在多个时空尺度上处理来直接生成全帧率、低分辨率的视频。我们展示了最先进的文本到视频生成结果,并表明我们的设计轻松支持各种内容创建任务和视频编辑应用,包括图像到视频、视频修复和风格化生成。
http://arxiv.org/abs/2401.12945v1
CMMMU:一个中国的大规模多学科多模态理解基准测试
随着大型多模态模型(LMMs)的能力不断提升,评估LMMs的性能变得越来越重要。此外,评估LMMs在中文等非英语环境中的高级知识和推理能力的差距更大。我们介绍了CMMMU,这是一个新的中国大型多学科多模态理解基准,旨在评估LMMs在对中国语境中需要大学水平学科知识和深思熟虑推理的任务上的表现。CMMMU受到并严格遵循MMMU的注释和分析模式的启发。
CMMMU包括从大学考试、测验和教科书中手动收集的1.2万个多模态问题,涵盖了艺术与设计、商业、科学、健康与医学、人文社会科学和技术工程等六个核心学科,与其伙伴MMMU一样。这些问题涵盖30个学科,并包括39种高度异构的图像类型,如图表、图示、地图、表格、乐谱和化学结构等。
CMMMU侧重于中国语境中具有领域特定知识的复杂感知和推理。我们评估了11个开源LMMs和一个专有的GPT-4V(ision)。即使是GPT-4V也只能达到42%的准确率,表明还有很大的改进空间。CMMMU将推动社群构建下一代的LMMs,朝着专家级人工智能的方向发展,并通过提供多样化的语言背景促进LMMs的民主化。
http://arxiv.org/abs/2401.11944v1
Medusa: 多解码头的简单LLM推理加速框架
大语言模型(LLMs)中的推理过程通常受限于自回归解码过程中的并行性缺失,导致大多数操作受限于加速器的内存带宽。尽管已经提出了一些解决这个问题的方法,例如推测性解码,但其实施受到获取和维护单独的草稿模型的挑战的阻碍。在本文中,我们提出了一种高效的方法Medusa,通过添加额外的解码头在并行预测多个连续的标记的同时来增强LLM推理。使用基于树的注意机制,Medusa构造多个候选延续并在每个解码步骤中同时验证它们。通过利用并行处理,Medusa在单步延迟方面仅引入了最小的开销,同时大大减少了所需的解码步骤数。
我们提出了两个级别的Medusa微调过程,以满足不同用例的需求:Medusa-1:Medusa直接在冻结的基础LLM之上进行微调,实现无损推理加速。Medusa-2:Medusa与基础LLM一起进行微调,提高Medusa头部的预测准确性和更高的加速比,但需要特殊的训练配方来保持基础模型的功能。
此外,我们提出了几个扩展,改进或扩展了Medusa的实用性,包括自蒸馏来处理没有训练数据可用的情况以及典型的接受方案来提高接受率同时保持生成质量。我们评估了多个大小和训练过程的Medusa模型。我们的实验证明,Medusa-1可以在不损害生成质量的情况下实现超过2.2倍的加速,而Medusa-2进一步提高了速度,达到2.3-3.6倍。
http://arxiv.org/abs/2401.10774v1
3
学习
详解专家混合:MoE模型
该文章深入探讨了混合专家模型(MoE),特别是新推出的Mixtral 8x7B。MoE是一种将多个专家神经网络整合在一起的Transformer技术,通过门控网络进行token路由,优化了预训练速度和推理效率。由于只在推理时使用部分专家参数,MoE可以在保有大量参数的同时提高推理速度。文章还讨论了MoE在自然语言处理(NLP)领域的应用和面临的挑战,如通信成本高和训练不稳定等,以及研究者为提升模型稳定性和效率所做的最新进展。
https://zhuanlan.zhihu.com/p/672002822
顶会最新速递@ ICLR2024,强化学习领域约301篇Accept论文汇总整理
ICLR2024会议上,强化学习领域的论文接受情况被整理汇总,共有约301篇论文被接受,包括11篇口头报告(Oral)、59篇亮点论文(Spotlight)和231篇海报论文(Poster)。这些论文涵盖了多个子领域,如深度强化学习、多智能体系统、语言模型与强化学习的结合、世界模型、规划、长期记忆任务、逆强化学习、因果世界模型学习等。文章还提供了论文的原始PDF链接和交流群信息,以便读者进一步了解和讨论这些研究成果。
Stable Diffusion 采样器工作指南
本文详细介绍了Stable Diffusion技术中的不同采样器及其工作原理。Stable Diffusion是一种生成图像的技术,通过逐步去除噪声来构建图像。采样器算法负责从模型中获取样本并应用噪声预测,而噪声调度器则控制去噪程度。文章对比了概率模型(如DDPM、DDIM、PLMS)和数值方法(如Euler、Heun、LMS)等采样器,以及它们的效率、收敛性和图像质量。特别提到了DPM模型家族及其变体,如DPM2、DPM++,以及它们如何通过改进求解器来提高采样效率。文章还探讨了祖先采样器和随机微分方程(SDE)变体,强调了它们在创造性和灵活性方面的优势。最后,文章提供了根据图像质量、生成速度和创造力需求选择合适采样器的建议。
利用LangChain、OpenAI、ChromaDB和Streamlit构建RAG
文章探讨了如何利用ChromaDB构建基于检索增强生成(RAG)的LLM(大型语言模型)应用,并实现RAG驱动的聊天应用。ChromaDB的优势在于处理大型数据集的高效性,RAG结合信息检索与LLM,通过查询外部文档产生知情的智能响应。实现过程涵盖环境设置、文档处理、创建嵌入、以及通过Streamlit创建用户界面,该界面允许用户上传文件并提问,系统依然由LLM提供答案。通过这种方式,构建的聊天应用利用Generative AI解答与输入文件相关的问题。
机器学习科研的十年
文章回顾了作者十年的机器学习研究历程,突出了深度学习、推荐系统、XGBoost、MXNet框架、知识迁移、GAN、内存优化算法以及TVM项目等关键技术的发展。作者通过不断探索和跨领域合作,实现了从研究新手到领域专家的转变,体现了科研中的不确定性、挑战与成长。
https://zhuanlan.zhihu.com/p/74249758?wechatShare=2&s_r=0
奇绩大模型空间站集合了社群、闭门活动以及陆奇博士每天都在看的大模型日报;欢迎扫码加入我们的空间站微信社群,我们将每天更新最新的日报和活动。

MIRACLEPLUS
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/01/17104.html