
01
SAM是什么
前言

 图:Segment Anything Demo
图:Segment Anything Demo 图:Segment Anything对用户提示作出响应
图:Segment Anything对用户提示作出响应SAM已经学会了关于物体的一般概念,并且它可以为任何图像或视频中的任何物体生成Mask,甚至包括在训练过程中没有遇到过的物体和图像类别。SAM足够通用,可以涵盖广泛的用例,并且可以在新的图像领域上开箱即用,无需额外的训练。
此外,SAM通过单一模型,既可以使用交互式方法进行图像分割,也可以全自动图像分割。

-
抛出一个Segment Anything(SA)的项目,在一个统一框架Prompt Encoder内,指定一个点、一个边界框、一句话,直接一键分割出对应物体 -
提出一个图像分割的基础模型:SAM(由图像编码器、提示编码器、解码器组成) -
提出一个大规模多样化的图像分割数据集:SA-1B(包含1100万张图片以及10亿个Mask图)
基础模型是指在广泛的数据上进行大规模训练,并且是适应广泛的下游任务。
提示工程是指任意表示图像中要分割的信息,如一组前景/背景点、一个粗略的框或者掩码、自由形式的文本等。
 图:Task,可提示分割
图:Task,可提示分割 图:模型对于模糊提示输出至少一个对象的合理掩码
图:模型对于模糊提示输出至少一个对象的合理掩码-
必须支持灵活的提示 -
需要在交互时实时计算掩码 -
必须具备歧义识别的能力
 图:SAM结构示意
图:SAM结构示意 图:图像数据对比
图:图像数据对比 图:掩码数量对比
图:掩码数量对比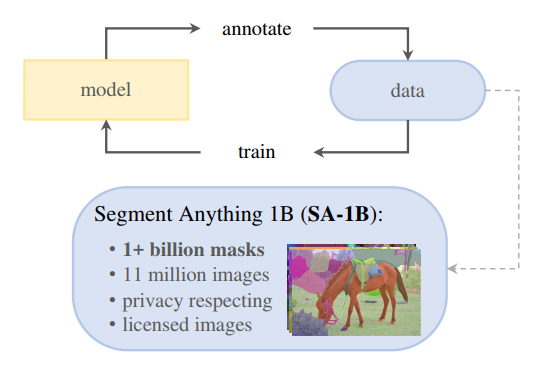 图:数据引擎(上),数据集(下)
图:数据引擎(上),数据集(下)原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2023/05/8367.html