


MOLAR FRESH 2022年03期
人工智能新鲜趣闻 每两周更新
01
AI字幕在儿童频道里吐“脏话”,中招比例高达40%
被AAAI 2022收录的一篇新研究发现,在7013个儿童视频中,接近40%的节目出现了少儿不宜或脏话等词汇。
甚至在一个113集的儿童机器人学习栏目中,AI就“爆粗”了103次,平均接近一集一次!
来看看这篇论文的调查结果。
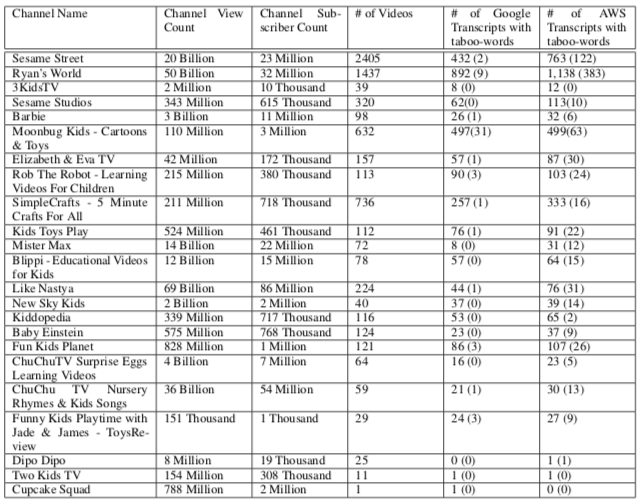
研究人员一共从油管上选出了24个儿童频道,分别记录了这些频道的播放量和订阅量。
可以看出,这些筛选出来的视频播放量基本都达到了百万级,订阅人数也同样不少。
然后,研究人员分别试了一下谷歌和AWS(亚马逊网页服务)的字幕生成效果。
结果显示,AI字幕的“少儿不宜”率可谓离谱:
在7013个视频中,谷歌AI出现错误字幕的次数达到2768次,接近40%。
亚马逊的AI字幕错误率还要更高,达到了3672次,超过52%。
具体来说,两个AI分别容易在这些“不太恰当”的字词上出错:
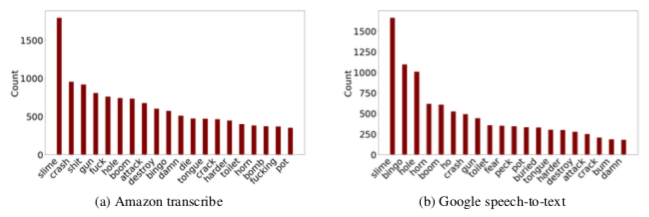
(图左亚马逊,图右谷歌)
在这些数据集中,有一些词语又尤为“少儿不宜”,例如一些骂人的脏词:
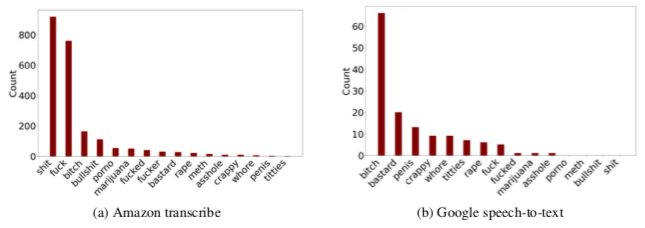
经过作者们人工检查(例如确认原视频是否真的说了脏话),发现AI主要容易在这几种情况中出错:背景音乐嘈杂、说话者为婴儿、说话者为儿童、说话者以英语为第二语言、说话者在唱歌。(包括但不限于这几种情况)
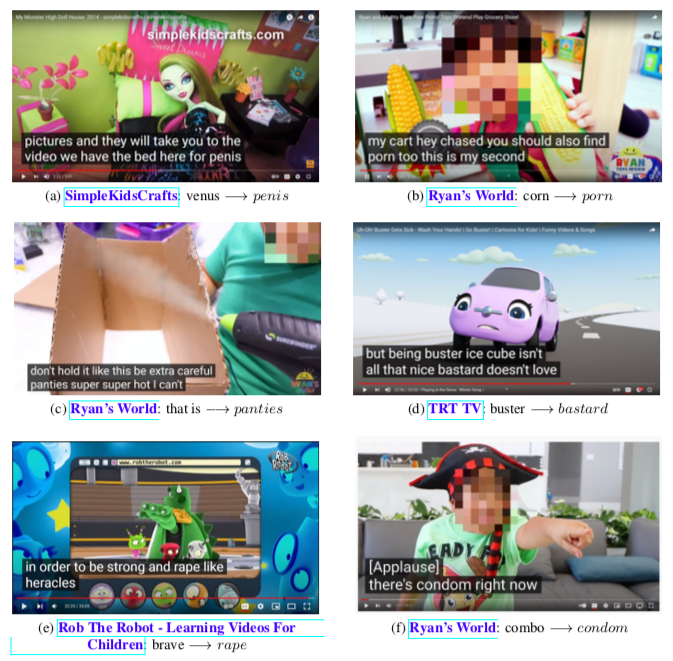
那么,有没有什么办法减少这种情况发生呢?
语序连贯的错误更容易修复
研究人员提出了一个新的数据集,利用近音字词来构建禁忌词的“替换”备选。
例如,对于crap这一可能出现的“粗口”,研究人员就给它设置了crab、craft等读音相似的字词,便于AI在搞错时进行替换。
具体来说,他们在BERT、XLM、XLNet等NLP模型上,针对“完形填空”任务进行了重新训练,也就是用[MASK]遮住部分单词,让AI来填写对应的内容。
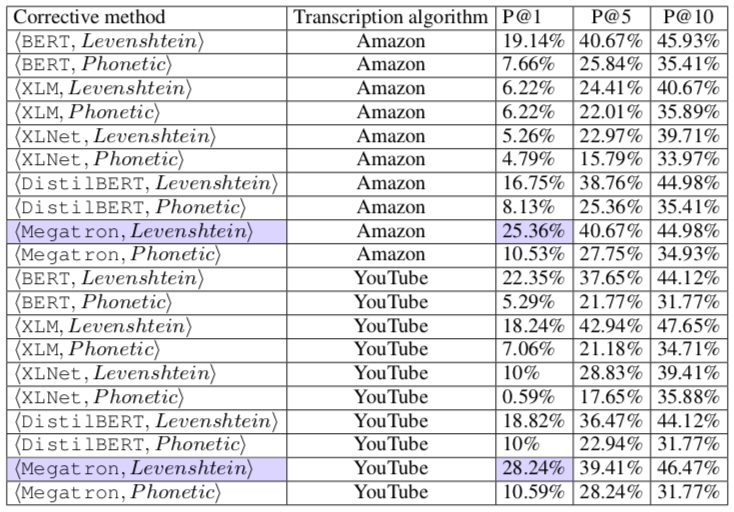
结果显示,在语序正常、前后文案有逻辑的视频中,AI替换的准确率更高(蓝色为正确替换词):

然而在一些逻辑不强的文案中,成功替换的效果就没有那么好了:

最终,Megatron和Levenshtein等模型展现出了最好的修复效果,分别给亚马逊AI带来了超过25%的正确修复率,给谷歌AI带来了超过28%的修复率。
看来AI在字幕生成能力上还是任重道远啊。
来源:量子位
论文地址:
https://github.com/sumeetkr/UnsafeTranscriptionofKidsContent/blob/main/YouTube_Transcription_Final.pdf
参考链接:
https://www.dailymail.co.uk/sciencetech/article-10553233/YouTube-AI-putting-explicit-language-captions-videos-aimed-children.html
02
买不起手办就用AI渲染一个!用网上随便搜的图就能合成
渲染一个精细到头发和皮肤褶皱的龙珠3D手办,有多复杂?
对于经典模型NeRF来说,至少需要同一个相机从特定距离拍摄的100张手办照片。
但现在,一个新AI模型只需要40张来源不限的网络图片,就能把整个手办渲染出来!

这些照片的拍摄角度、远近和亮暗都没有要求,还原出来的图片却能做到清晰无伪影:

甚至还能预估材质,并从任意角度重新打光:

这个AI模型名叫NeROIC,是南加州大学和Snap团队玩出来的新花样。
它如何仅凭任意2D输入,就获取到物体的3D形状和性质的呢?
基于NeRF改进,可预测材料光照
介绍这个模型之前,需要先简单回顾一下NeRF。
NeRF提出了一种名叫神经辐射场(neural radiance field)的方法,利用5D向量函数来表示连续场景,其中5个参数分别用来表示空间点的坐标位置(x,y,z)和视角方向(θ,φ)。
然而,NeRF却存在一些问题:
– 对输入图片的要求较高,必须是同一场景下拍摄的物体照片;
– 无法预测物体的材料属性,因此无法改变渲染的光照条件。
这次的NeROIC,就针对这两方面进行了优化:
– 输入图片的场景不限,可以是物体的任意背景照片,甚至是网络图片;
– 可以预测材料属性,在渲染时可以改变物体表面光照效果(可以打光)。
它主要由2个网络构成,包括深度提取网络和渲染网络。
首先是深度提取网络,用于提取物体的各种参数。
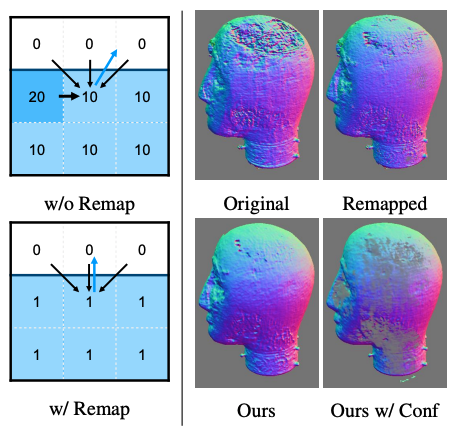
为了做到输入场景不限,需要先让AI学会从不同背景中抠图,但由于AI对相机的位置估计得不准确,抠出来的图片总是存在下面这样的伪影:

因此,深度提取网络引入了相机参数,让AI学习如何估计相机的位置,也就是估算图片中的网友是从哪个角度拍摄、距离有多远,抠出来的图片接近真实效果(GT):

同时,设计了一种估计物体表面法线的新算法,在保留关键细节的同时,也消除了几何噪声的影响(法线即模型表面的纹路,随光线条件变化发生变化,从而影响光照渲染效果):
最后是渲染网络,用提取的参数来渲染出3D物体的效果。
具体来说,论文提出了一种将颜色预测、神经网络与参数模型结合的方法,用于计算颜色、预测最终法线等。
其中,NeROIC的实现框架用PyTorch搭建,训练时用了4张英伟达的Tesla V100显卡。
训练时,深度提取网络需要跑6~13小时,渲染网络则跑2~4小时。
用网络图片就能渲染3D模型
至于训练NeROIC采用的数据集,则主要有三部分:
来源于互联网(部分商品来源于网购平台,即亚马逊和淘宝)、NeRD、以及作者自己拍摄的(牛奶、电视、模型)图像,平均每个物体收集40张照片。
那么,这样的模型效果究竟如何呢?
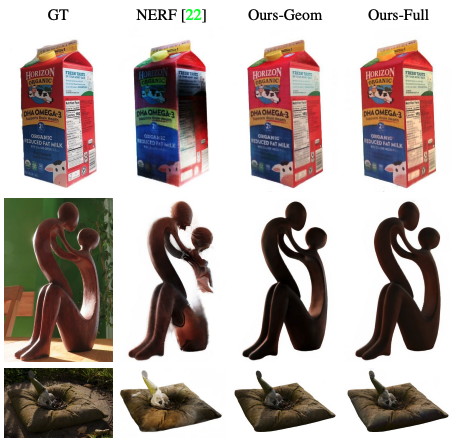
论文先是将NeROIC与NeRF进行了对比.
从直观效果来看,无论是物体渲染细节还是清晰度,NeROIC都要比NeRF更好。
具体到峰值信噪比(PSNR)和结构相似性(SSIM)来看,深度提取网络的“抠图”技术都挺不错,相较NeRF做得更好:

同时,论文也在更多场景中测试了渲染模型的效果,事实证明不会出现伪影等情况:

以后或许只需要几张网友“卖家秀”,就真能在家搞VR云试用了。
来源:量子位
论文地址:
https://arxiv.org/abs/2201.02533
项目地址:
https://formyfamily.github.io/NeROIC/
参考链接:
[1]https://twitter.com/ben_ferns/status/1486705623186112520
[2]https://twitter.com/ak92501/status/1480353151748386824
[3]https://zhengfeikuang.com/
[4]https://ningding97.github.io/fewnerd/
03
有AI学会控制核聚变反应堆了,来自DeepMind,登上今日Nature
DeepMind在蛋白质折叠问题上实现巨大突破后,目标又转向核聚变了。
最近,它开发出了世界上第一个深度强化学习AI——可以在模拟环境和真正的核聚变装置(托卡马克)中实现对等离子体的自主控制。
这比传统的计算机控制要更高效且精准,成果登上今天的Nature。

作为强化学习最具有挑战性的一个应用,这一成果也对加速可控核聚变有很大
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2022/02/8393.html