我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!
学习
-
性能提升非常明显;BF16 在 GroupGemm 能够实现 600到 750 左右的 TFLOPS,FP8 可以实现 1000到 1280 TFLOPS,这个提升对于降低训练和推理成本来说太明显了;
-
相比 H800 显卡,H20 这种小算力的 MFU 更高一些,毕竟 TFLOPS 与 GB/s 比值更友好;
-
相比官方在 H800 上的测试成绩,我的测试结果略差一些,区别在于 CUDA 版本,官方测试是 12.8,我用的是12.4;
-
看了代码的初步体会是,这个作者是个扫地僧,没有任何奇技淫巧,全凭高深的内功,在深入理解Hopper 体系结构的特点后,参照 cutlass 代码流程后手撸出来;
-
源码中的JIT Tuner,这个组件非常轻量且高效;
-
等时间允许的情况下,会测试一下VLLM和 SGLang 里的 FP8 Gemm Kernel,到时候再做一个对比。
https://zhuanlan.zhihu.com/p/26793053604
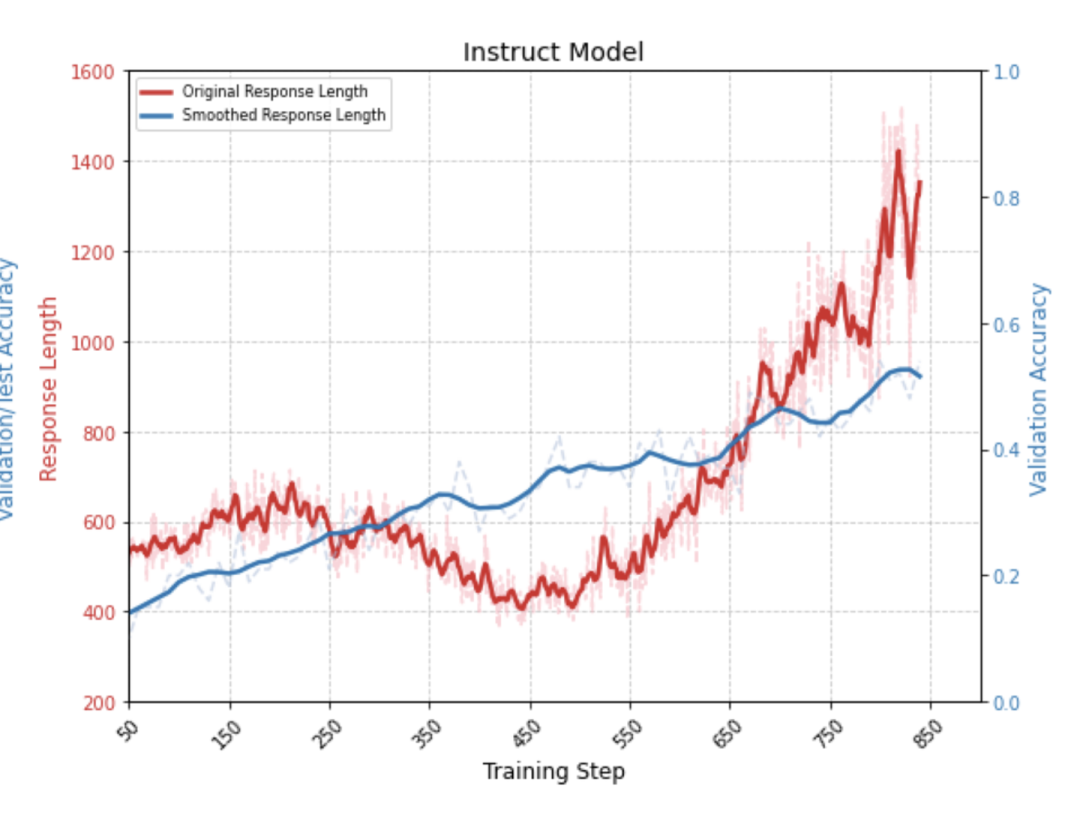
作者进行的实验是基于Logic-RL和Huggingface的Open-R1模型,目的是探索强化学习(RL)在小规模模型上的应用,尤其是在推理任务中。由于硬件限制(仅有四张3090显卡),作者选择了一个较小的0.5B模型进行实验,具体使用了qwen-0.5B的instruct模型进行训练。实验过程中遇到了不少技术细节,以下是一些主要问题和解决方案。
首先,在使用Logic-RL的奖励机制时,我发现模型会在得到奖励后迅速变得懒散,输出会极度简短,几乎不再进行推理。这是因为在原版的reward规则中,只要模型遵循了格式,就能获得奖励,导致模型不再关心推理的正确性。为了修正这一点,我修改了奖励规则,只有当模型的推理格式和答案都正确时,才会给予奖励。这样修改后,模型在训练过程中逐渐保留了思考过程。
其次,针对3人以上的推理问题,0.5B模型的能力显得捉襟见肘。直接在3至7人数据集上训练时,模型的输出质量一直处于最低分,且经常输出胡言乱语。为了解决这一问题,我采用了逐步训练策略,即先在2ppl数据集上训练10步,再逐步过渡到3ppl、4ppl、5ppl和6ppl的数据集。这样模型逐步积累经验,并通过在更复杂问题上的训练,逐渐提高了推理的准确性。
然而,尽管如此,模型的推理过程依然存在问题,尤其是在长链推理的场景中。随着训练的进行,模型的推理链逐渐变得过于简单,最终收敛到一种固定且简单的推理模式,无法进行有效的探索。这表明模型没有真正学会如何通过复杂推理解决问题,而是倾向于通过简单的映射(例如从prompt直接推导答案)来完成任务。
这个问题可能源于奖励机制设计不完善。具体来说,训练过程中的奖励是基于”抽签+筛选”的方式进行的。如果模型在某次尝试中仅通过猜测得到了正确答案,虽然这样做是错误的,但也能获得奖励;而那些尝试使用复杂推理解决问题但未能得到正确答案的行为则被淘汰。随着训练的推进,模型最终会倾向于选择简单的答案方式,从而忽视了推理过程本身。
最后,针对小模型无法有效学习长链推理的现象,我猜测较大模型可能会表现得更好。较大的模型本身就具有处理复杂推理的潜力,可能能有效地保留并强化长思维链的推理过程。而小模型由于容量的限制,可能更容易依赖简单的答案映射,而非真实的推理过程。
https://zhuanlan.zhihu.com/p/27699656438
随着LLM在代码生成任务上的应用逐渐增多,学术界和工业界对于代码任务中的模型微调(SFT)过程有了越来越多的讨论。然而,随着模型能力的增强,关于SFT的误解和局限性也逐渐显现,尤其是如何准备数据以实现用户满意的效果,仍是一个挑战。本文总结了笔者在过去两年内对SFT过程的经验和一些思考,并就如何选择模型、数据来源及其组织、SFT技术细节等方面提出了见解。
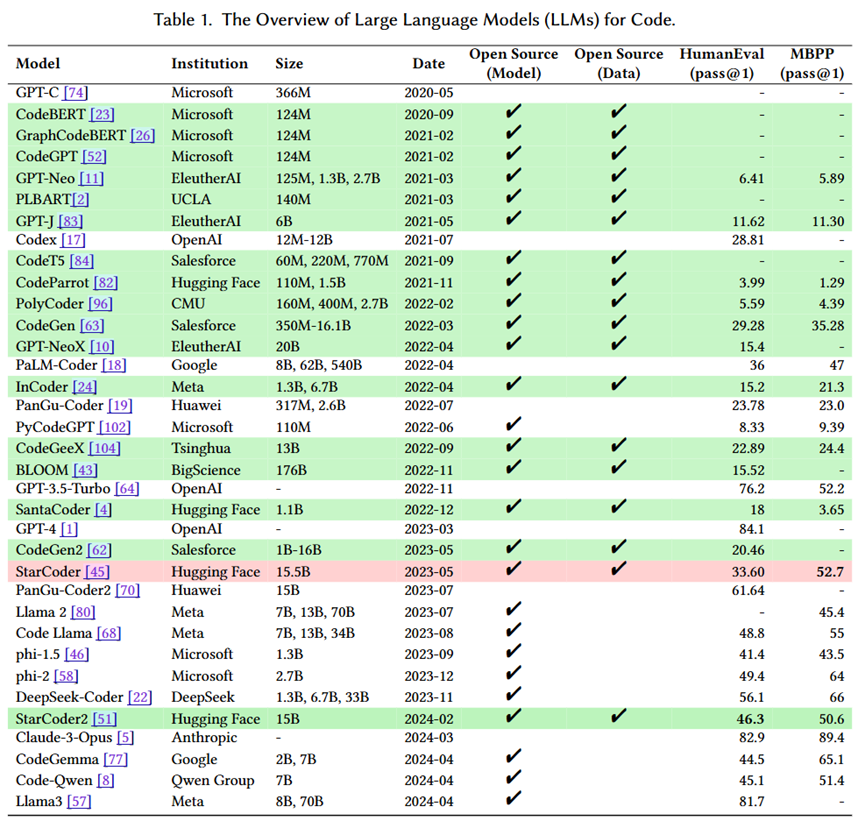
首先,关于模型选择,学术界和工业界的需求差异非常大。学术界通常侧重于验证方法的有效性,常使用一些热门的LLM进行实验,忽视模型本身的预训练缺陷。然而,工业界往往需要在已有的基础模型上进行SFT,尽管这些基础模型可能存在一些问题。在过去几年中,常用于代码任务的模型包括CodeBERT、CodeT5、GPT-3.5、Llama系列、CodeLlama等,然而,除了一些新型的开源模型(如StarCoder和Opencoder),大多数模型在预训练过程中存在较大缺陷,做SFT时可能需要额外的“hack”。
在如何判断一个模型的能力时,笔者提出了几种常用的方法,如通过基准测试(如Humaneval、mbpp)来判断模型的基础能力,或者使用SFT过程中的训练结果来验证模型的适应性。对于某些基础模型表现不佳的情况,笔者建议避免进行进一步的SFT实验。
在进行SFT时,模型版本和大小的选择也是一个需要关注的问题。资源有限的情况下,7B左右的模型较为适合,同时,使用instructed版本的模型在某些情况下比基础版本更具性价比。对于大多数任务,使用全参数微调(Full SFT)通常更有效,尤其是在资源允许的情况下,LoRA等参数高效微调方法适用于一些计算资源有限的情况,但对于代码任务,Full SFT往往能更好地体现数据集的价值。
数据选择与组织方面,笔者强调了SFT数据的质量远比数量更为重要,且数据的筛选和合成方法在模型训练中起着至关重要的作用。相比于广泛收集数据,使用程序自动生成合成数据已成为更为高效的选择。笔者也提到,通过选择少量高质量的SFT数据,而非大量低质量数据,能够显著提高模型在代码任务上的表现。数据合成的方法在确保覆盖更多主题和提供多样性的同时,减少了数据重复的问题。
最后,关于如何定义“用户满意”,笔者认为,当前代码生成任务的关键需求是生成语法正确、语义正确、功能完整的可执行代码。随着模型能力的提升,重点将逐步转向如何兼容不同的人类用户需求,而不仅仅是提高代码生成的准确性。
https://zhuanlan.zhihu.com/p/29211684588
HuggingFace&Github
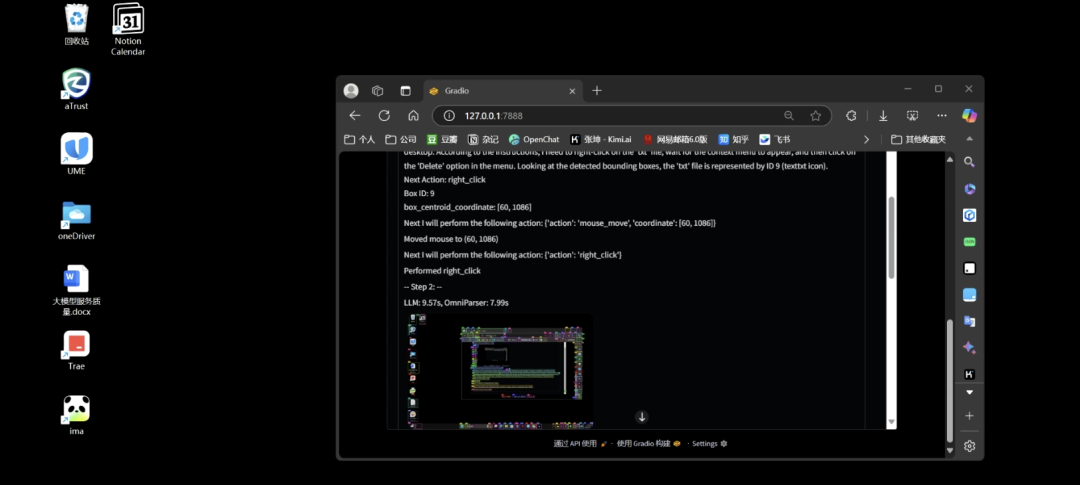
autoMate是一个基于 AI 和 RPA(机器人流程自动化)的本地自动化工具,旨在通过自然语言任务描述,帮助用户完成计算机上的重复性工作。它依赖OmniParser作为核心技术,使 AI 能够智能地理解屏幕内容,并执行复杂的自动化任务。
-
无代码自动化
-
支持任意可视化界面
-
支持中文环境,一键部署
-
兼容主流大型语言模型
https://github.com/yuruotong1/autoMate
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43856.html