
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!



HuggingFace&Github
SkyReels V1: 人像视频生成模型
SkyReels V1 是首个开源的人像视频生成基础模型,基于混元video模型,经过千万级高质量影视片段微调。SkyReels V1具备以下特点:
多阶段图像到视频预训练:文本转视频模型在开源领域表现出色,性能接近Kling和Hailuo等模型
自研数据清理与标注管线:捕捉33种面部表情,超过400种自然运动组合,精准反映人类的情感。
光影效果:基于好莱坞级影视数据训练,构图、演员定位和镜头角度出色。

https://huggingface.co/Skywork/SkyReels-V1-Hunyuan-I2V
学习
R1-复现之路之二
在本文中,作者通过在 Qwen2.5-7B-Instruct 模型上进行 GRPO 训练实验,探讨了模型在 MATH 数据集上的表现,并对实验结果及奖励机制设计进行了深入分析。
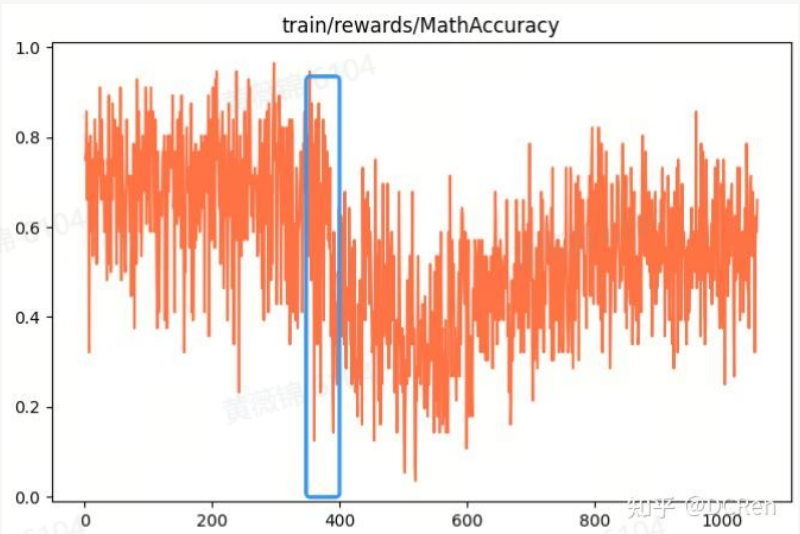
实验使用 Qwen2.5-7B-Instruct 作为基础模型,采用 Swift 训练框架,奖励机制包括结果奖励和格式奖励,权重各占 0.5,训练周期为 1 个 epoch。然而,实验结果显示,训练后的模型在结果奖励和格式奖励方面均未达到预期,甚至低于未训练时的表现。通过分析训练曲线,作者发现在 step350-step400 期间,模型出现了训练偏差,导致奖励值下降,且后续无法恢复。
进一步查看训练日志,作者发现 step385-step390 出现了奖励值突变,尤其是 step387 中,模型输出的采样结果虽然奖励值为 1,但中间过程已出现乱码。这种错误样本被强化后,导致模型学习方向偏离,最终训练失败。
作者认为,这种现象与奖励机制设计有关。在当前设计下,模型可能因片面追求某一种奖励(如格式或结果)而导致整体性能下降。例如,当奖励权重为 1:1 时,模型可能会增加仅符合一种奖励条件的输出概率,而忽视其他重要方面。作者提出,可以尝试调整奖励机制,如只有同时满足结果和格式要求的输出才给予高奖励,但这可能对小模型或能力较弱的模型不适用,因为它们可能难以生成符合高奖励标准的输出。
此外,作者还考虑了通过调整奖励权重,让模型先学会格式,再学会解题,但尚未进行实验验证。总体而言,实验表明,对于能力较弱的小模型,直接通过强化学习提升难题解题能力仍面临挑战。
https://zhuanlan.zhihu.com/p/25467209143pdf
verl小白解读
在学习Verl框架的过程中,作者对其代码和设计进行了详细分析,并整理成笔记。目前中文互联网上尚未有相关介绍,因此希望这些内容能为初学者提供帮助。Verl代码的可读性很高,经过2天的快速梳理,作者已大致了解了其200次提交的内容。Verl已升级至0.2版本,支持了许多新特性,值得体验。
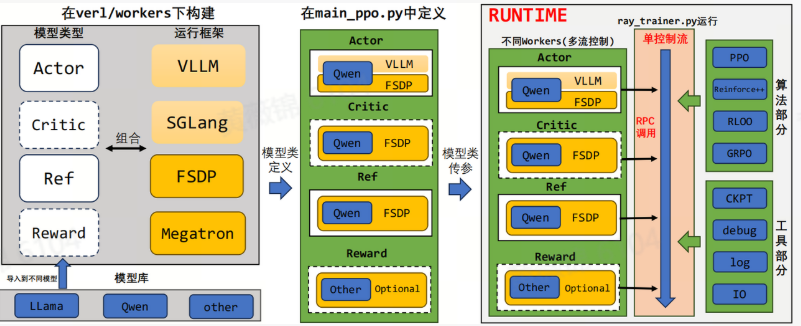
Verl框架的文件结构清晰,通过模块化设计方便用户进行修改和学习。其中,example部分是用户构建和运行训练脚本的直观入口,而verl/trainer是脚本调用的直接入口,通常会调用main_ppo。如果需要修改具体模块,则需进入verl/workers进行操作。Verl后端支持多种训练和推理框架,包括FSDP、Megatron(部分功能尚未支持)、VLLM和正在集成的SGLang。
框架的逻辑设计灵活高效,支持多种预训练模型和训练后端的组合。通过参数传递,可以将不同角色与main_ppo.py中的角色绑定,并在ray_trainer.py中调用。trainer文件中的fit()函数以单控制流的方式运行,从模型获取计算值后导入算法模块和工具模块,即可快速开展RL训练任务。框架的训练流程以PPO为例,通过Ray将模型映射到不同机器上,使用VLLM框架进行推理,然后将结果输入到其他框架进行训练,最后结合计算结果对Actor和Critic模型进行训练。
Verl的参数设置目前采用模板结合脚本参数覆盖的方式,相关参数可在verl/trainer/config中查看和修改。训练过程中产生的log日志记录了丰富的信息,包括训练参数、模型信息、训练指标及效率等。此外,Verl的设计解耦度高,新算法可以快速集成到框架中。例如,Reinforce++和RLOO算法仅需在core_algos.py中定义计算公式,并将其导入ray_trainer.py的流程中即可完成集成。
https://zhuanlan.zhihu.com/p/25556718002
VLM推理模型详细解读(1):LLaVA-CoT
本文旨在提升视觉语言模型(VLMs)在复杂视觉问答任务中的系统性结构化推理能力。现有VLMs在推理过程中缺乏系统性和结构性,导致在复杂任务中易出错且产生幻觉输出,同时推理时间扩展面临挑战。早期VLMs多采用直接预测方法,缺乏结构化推理,而链式思维提示(CoT)通过分解问题显著提升了问答能力,但现有推理时间扩展方法在开放式问题上效果有限。
为解决上述问题,本文提出了一种新型视觉语言模型LLaVA-CoT。该模型将答案生成过程分解为四个结构化推理阶段:总结、标题、推理和结论。总结阶段提供问题的高层次概述;标题阶段针对图像内容给出简洁描述;推理阶段基于总结进行逻辑推理生成初步答案;结论阶段综合推理结果生成最终答案。
为训练LLaVA-CoT,作者构建了包含99k图像问答对的LLaVA-CoT-100k数据集,使用GPT-4o生成详细的推理过程,并采用监督微调进行训练。此外,作者提出了一种阶段级束搜索方法,通过在每个推理阶段生成多个候选结果并选择最佳响应,进一步增强模型的推理能力。
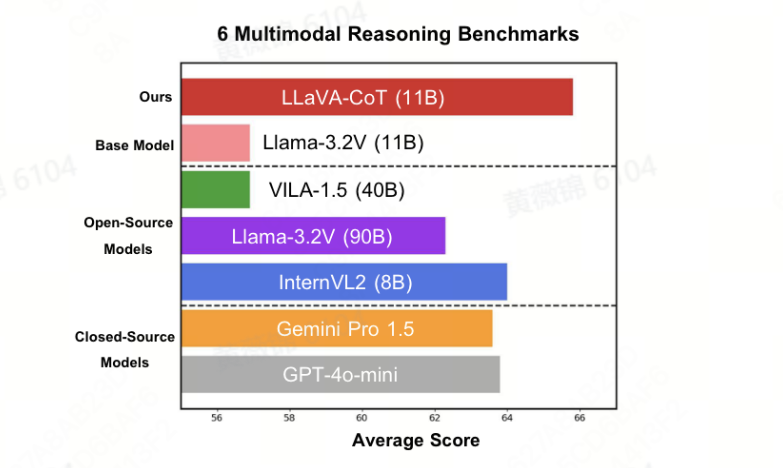
实验数据来自多个视觉问答数据集,包括ShareGPT4V、ChartQA等,共99k图像问答对。实验在六个多模态推理基准上进行,使用VLMEvalKit确保公平性和可重复性。结果表明,LLaVA-CoT在视觉问答、数学推理等任务上平均基准得分比基础模型提高了6.9%。消融研究显示,LLaVA-CoT-100k数据集比原始数据集更有效,结构化标签对性能提升至关重要。推理时间扩展方面,阶段级束搜索方法在增加候选响应数量时表现出显著的有效性。
总体而言,LLaVA-CoT通过结构化推理阶段和推理时间扩展方法,显著提升了多模态推理能力,未来可进一步探索结构化推理的外部验证器和强化学习的应用。
https://zhuanlan.zhihu.com/p/14011749432
尝试基于vLLM+Ray多机部署满血DeepSeek-R1
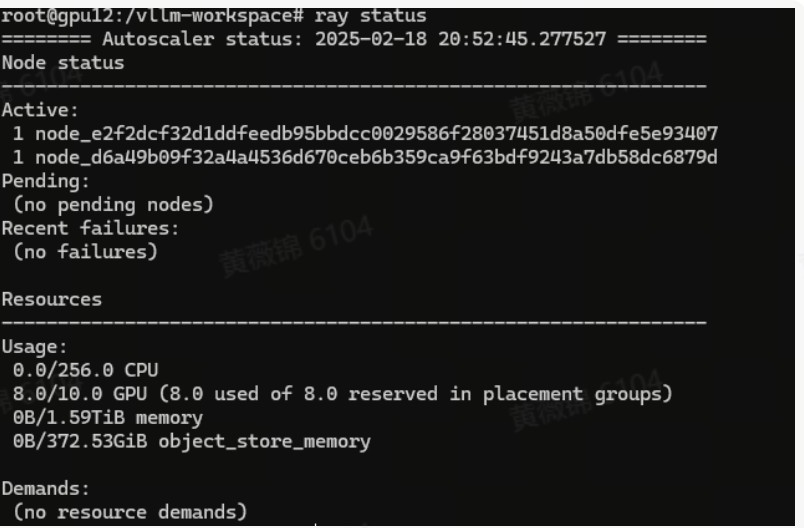
在部署大规模模型如DeepSeek-R1时,单机显存往往不足以容纳模型,因此需要采用多机部署策略。以Qwen2.5-72B-Instruct为例,可以通过vLLM框架进行多机部署,该模型在vLLM上部署时显存需求约为150GB。部署环境为两台服务器,每台配备8张A800 GPU(CUDA 12.2),网络互通且文件系统共享。部署过程中,首先拉取vLLM最新Docker镜像(v0.7.2),然后编写run_cluster.sh脚本以启动Ray集群,并通过Docker容器管理GPU资源。部署时,一台机器作为head节点,另一台作为worker节点,通过ray status检查集群状态。启动vLLM服务时,设置参数如--tensor-parallel-size为8,--gpu-memory-utilization为0.8等,以优化性能。
在性能测试方面,使用EvalScope对API服务进行压力测试,结果显示多机部署的性能略低于单机配置,这主要是由于多机通信带来的延迟。在尝试部署满血DeepSeek-R1时,由于模型权重加载需要约680GB显存,而A100、A800系列显卡不支持FP8格式,导致部署失败。如果将模型权重转换为FP16格式,则需要双倍显存,资源需求过高,因此未能继续测试。
作为替代方案,尝试单机部署量化后的DeepSeek-R1-AWQ模型。使用vLLM镜像启动服务时,设置参数如--dtype float16和--tensor-parallel-size 8等,但遇到不支持MLA的问题。尽管如此,最终仍成功部署,生成速度约为5 tokens/s,与预期存在差距,可能与未支持MLA的AWQ量化有关。
https://zhuanlan.zhihu.com/p/25033216546
本地部署DeepSeek671bQ4|单张4060ti 16G和它的伙伴们
本文介绍了一种基于KTransformers框架的高性能LLM推理优化方案,用于在有限硬件资源下实现高效的大语言模型推理。硬件配置包括两颗9275F CPU(24核)、64GB RDIMM内存和一块4060 Ti 16GB显卡,操作系统为Ubuntu 24.04,CUDA版本为12.4,PyTorch版本为2.6.0+cu124。在该配置下,推理速度在长上下文时可达12.5 tokens/s,表现出良好的可用性。
为了实现高效推理,作者使用了Ollama的671B模型镜像(实际大小377GB,Q4量化)。通过KTransformers框架(基于v0.2版本),在16GB显存下运行模型时,通过代码优化清理显存,确保显存充足。KTransformers支持多线程推理,最佳线程数为32,推理速度与输入token长度相关,长文本输入会增加显存占用,但不影响后续短文本推理。
搭建过程中,作者对BIOS进行了优化配置,关闭超线程,设置NUMA为2,开启内存交错,并优化xGMI链路配置。在软件环境搭建方面,使用virtualenvwrapper创建Python虚拟环境,并安装了必要的编译工具、CUDA工具包和Python依赖项,包括PyTorch、flash_attn和flashinfer等。
KTransformers代码通过Git克隆并修改,增加显存清理功能后编译安装。模型名称在配置文件中修改,以便在OpenWebUI中正确显示。Ollama通过安装脚本部署,并拉取671B模型镜像,通过软链接方便模型路径访问。
推理服务通过KTransformers启动,设置合适的线程数和最大新token数。OpenWebUI作为前端界面,通过配置连接到KTransformers的API服务,禁用了一些不适用的功能,以提高推理效率。推理速度通过日志中的prefill和decode指标监控,主要关注decode速度。
作者计划后续尝试使用4070 Ti Super显卡,进一步探索显卡算力和显存速度提升对推理效率的影响。

https://zhuanlan.zhihu.com/p/25491611225
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/43072.html