


1. PIN-14M 数据集简介
PIN-14M 项目链接: https://huggingface.co/datasets/m-a-p/PIN-14M
PIN(Paired and INterleaved)数据集是由 M-A-P 团队和 2077AI 等开源组织构建的新型多模态数据集格式,旨在解决现有多模态数据集在训练大型多模态模型(LMM)时存在的感知和推理错误问题。PIN 数据集通过结合Markdown文件和图像,采用知识密集型、可扩展和支持多种训练策略的设计理念,极大地增强了模型学习复杂任务的能力。为应对多模态大模型训练过程中的持续挑战,尤其是复杂视觉数据解释和多模态关系推断的问题,M-A-P 团队发布了开源数据集 PIN-14M,PIN-14M 包含1400万个样本,涵盖了丰富的科学和网络内容,并注重数据质量和伦理完整性。PIN-14M 数据集验证的初步结果表明,PIN 格式在改进大型多模态模型(LMM)性能上具有巨大潜力。

传统多模态格式与提出的 PIN 格式的比较分析
PIN-14M 研发团队由 M-A-P 团队和 2077AI 开源社区共同组织构成。M-A-P 团队以其在多模态数据研究领域的前沿贡献而闻名,专注于通过构建强大且多样化的数据集来推动 AI 驱动的解决方案发展。2077AI 开源社区则致力于 AI 数据标准化和生态系统建设,两者的合作结合了技术创新与战略愿景。PIN-14M 的开源,推动了开源领域的进步,也体现了团队为更高效、更繁荣的 AI 数据生态系统共同发力,不断取得突破进展。
2. PIN-14M 数据集的构建
PIN-14M 基于三大核心原则构建而成:知识密集型、可扩展性和支持多种训练策略。
知识密集型指每个样本包含了文本和图像的紧密结合,通过同时处理Markdown格式文档和全局图像,充分表达多模态信息。此外,文本部分还使用粗体、斜体、标题等标记语言对知识进行结构化,帮助模型理解知识之间的层次关系。
可扩展性体现在 PIN 数据集通过统一的格式能够兼容并转换现有的多模态数据集,无论是现有的图像-文本对数据集,还是交错文档数据集,都可以通过简单的处理流程转化为 PIN 格式,从而支持更大规模的数据集构建。
PIN 格式还能支持图像-文本配对、交错训练以及其他多模态训练等多种训练策略策略。这使得模型可以从不同的角度进行学习,提升推理能力,并提高其在复杂场景下的表现。
为了实现这些目标,M-A-P 团队采用了一系列处理流程:
在数据收集与清洗的过程中,团队从不同的学术论文、网络资源和专业平台(如arXiv、PMC等)收集文本和图像数据。接着,团队对数据格式进行了转换和统一,将原始的文本和图像数据转化为结构化的Markdown格式,并根据文档内容生成全局图像。为确保数据质量,团队为每个数据条目嵌入了质量信号,允许研究人员根据需求对数据进行选择性筛选。所有数据均遵循开源许可协议,以确保透明性和伦理合规。
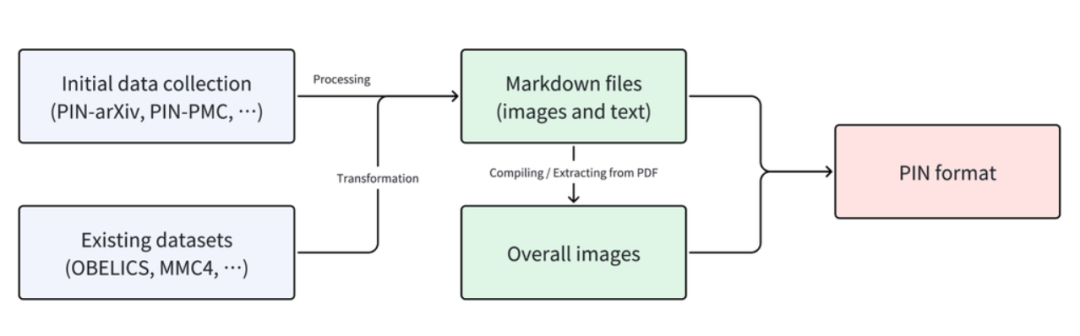
PIN-14M 工作流程概述
3. 多模态训练数据集建构新范式
整数智能信息技术(杭州)有限责任公司,起源自浙江大学计算机创新技术研究院,致力于成为AI行业的数据合伙人。整数智能也是中国人工智能产业发展联盟、ASAM协会、浙江省人工智能产业技术联盟成员,其提供的智能数据工程平台(MooreData Platform)与数据集构建服务(ACE Service),满足了智能驾驶(Automobile AI)、生成式人工智能(Generative AI)、具身智能(Embodied AI)等数十个人工智能应用场景对于先进的智能标注工具以及高质量数据的需求。

目前公司已合作海内外顶级科技公司与科研机构客户1000余家,拥有知识产权数十项,通过ISO 9001、ISO 27001、ISO 27701等国际认证,也多次参与人工智能领域的标准与白皮书撰写,也受到《CCTV财经频道》《新锐杭商》《浙江卫视》《苏州卫视》等多家新闻媒体报道。






原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/32816.html