
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos
 https://arxiv.org/abs/2412.09621
https://arxiv.org/abs/2412.09621Byte Latent Transformer: Patches Scale Better Than Tokens

Clio: Privacy-Preserving Insights into Real-World AI Use

Bootstrapping Language-Guided Navigation Learning with Self-Refining Data Flywheel
-
自我精炼数据飞轮(SRDF):该方法通过导航器与指令生成器之间的循环反馈,提高生成的指令与轨迹的对齐质量。首先,使用现有的人工标注数据训练指令生成器,生成指令并与导航器共同优化,确保生成的指令在多场景下具有高保真度。 -
导航器作为数据筛选器:使用训练好的导航器评估指令-轨迹对的质量,采用路径保真度评分(nDTW和SPL)作为指令与轨迹对齐的衡量标准。导航器的高性能确保了对合成数据的有效筛选,避免了传统度量方法(如CLIP分数)对多场景语义和方向性对齐的局限性。 -
迭代优化:生成器和导航器通过多次迭代提升性能,生成器在优化过程中不断提高指令质量,导航器则借助更好的数据提升其在实际任务中的表现。 -
高质量数据集构建:通过该方法,不仅提升了指令生成的质量,还创建了一个更具挑战性的、高质量的合成VLN数据集。 -
性能突破:在R2R数据集上,SRDF方法显著提高了指令跟随和生成的表现,首次在指令跟随任务中超越了人类表现(76%的SPL)。此外,该方法还成功实现了跨任务的迁移能力,在多个下游VLN任务中表现出色。
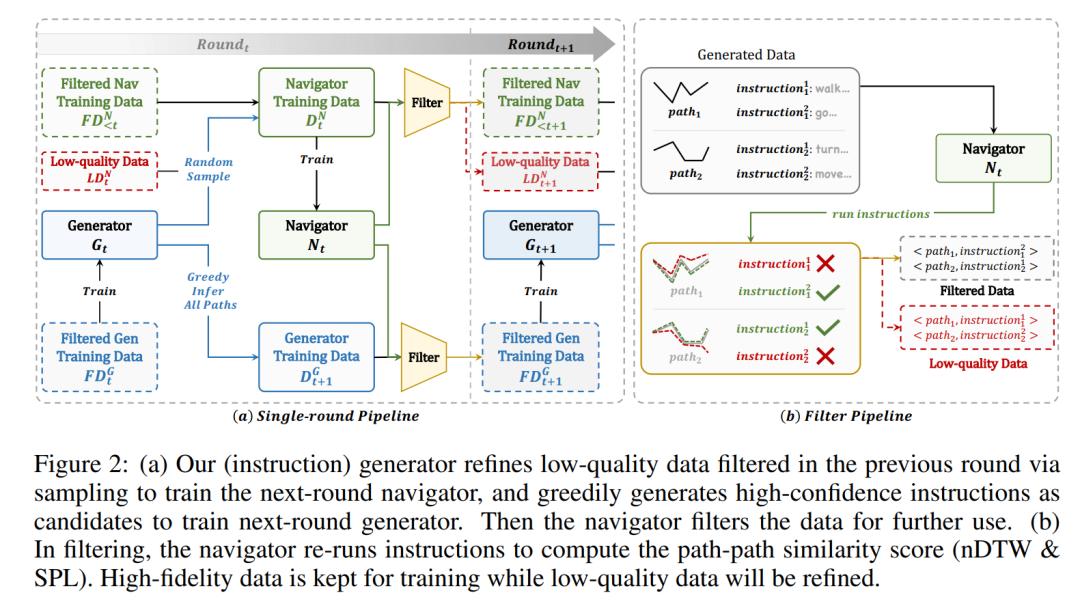
Large Concept Models: Language Modeling in a Sentence Representation Space
-
抽象层次的推理:与传统LLMs不同,LCM在抽象的概念嵌入空间中进行推理,而非基于词元。这意味着其推理过程不依赖于特定语言或模态,而是在语义层面建模,从而实现语言和模态的独立性,支持跨语言和跨模态的通用性。 -
概念嵌入(Concept Embeddings):LCM使用SONAR(一个预训练的句子嵌入模型)将输入文本分割成句子,并将每个句子编码成概念嵌入。然后,通过LCM进行进一步处理,生成新的概念嵌入,再通过SONAR解码回原始的词元或其他语言的表达。此方法避免了传统模型中的语言依赖,并可无缝地进行语言间转换。 -
显式层次化结构:LCM的架构支持长文本的层次化处理。通过在更高抽象层次进行推理和结构化,LCM能够更好地生成长文本,同时保持逻辑一致性和可读性。这种结构也方便了用户的交互式编辑,提升了文本的可修改性和可控性。 -
零样本泛化能力:由于LCM的推理是在语言和模态无关的概念层面进行的,因此能够在不同语言或模态之间进行零样本推理,无需额外的微调或数据支持。例如,LCM可以直接处理任何SONAR支持的语言和模态,实现跨语言的任务推理和生成。 -
模块化与可扩展性:与多模态LLMs可能出现的模态竞争问题不同,LCM允许概念编码器和解码器独立开发和优化,新增语言或模态时不必担心相互干扰,从而提高系统的灵活性和扩展性。 -
优化的推理架构:LCM通过更短的序列长度和有效的噪声调度策略,解决了传统transformer模型在处理长上下文时的复杂性问题。此外,LCM在推理过程中采用了基于扩散(diffusion)的多种架构设计,进一步提高了推理效率。
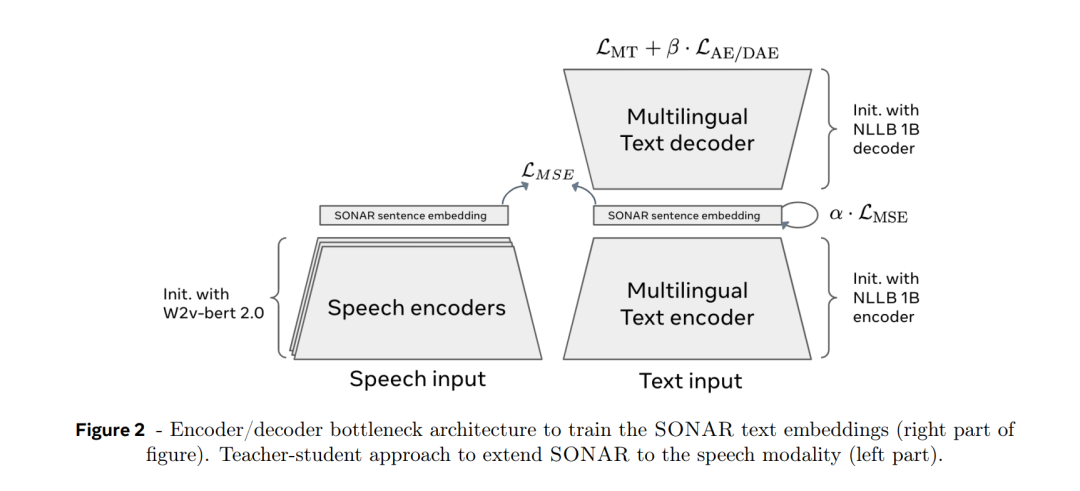
GPD-1: Generative Pre-training for Driving
-
统一场景表示:GPD-1将地图、代理和自车信息作为一组统一的token进行编码,采用自回归Transformer架构,并引入场景级别的注意力掩码,以捕捉自车、代理和地图之间的双向依赖关系。这种方法有效地整合了各个元素,使得模型能够在不同的任务中共同作用。 -
分层位置编码器:对于自车和代理,作者提出了一种分层位置编码器,能够有效地将鸟瞰图(BEV)中的位置和朝向转换为离散的token。这种方法显著减少了特征空间中的噪声,提高了位置编码的精确度。 -
地图信息的离散化表示:为简化地图信息的处理,GPD-1使用向量量化自动编码器(VQ-VAE)将自车视角下的语义地图压缩成离散token。这种方法避免了直接预测连续的地图坐标,从而简化了学习过程并增强了模型的泛化能力。 -
多任务能力:GPD-1在没有任何微调的情况下,能够执行场景生成、交通模拟、闭环仿真和运动规划等任务。例如,在场景生成中,模型可以初始化场景并平滑生成代理、地图和自车信息;在交通模拟中,给定真实地图和初始代理状态,模型能够预测后续帧的演化;在闭环仿真中,模型根据自车轨迹动态调整代理轨迹;在运动规划中,模型生成自车轨迹以响应提供的代理和地图信息。 -
状态-of-the-art表现:通过进一步的微调,GPD-1能够在多个下游任务中达到最先进的性能,特别是在nuPlan基准中的运动规划任务中表现突出。
Multimodal Latent Language Modeling with Next-Token Diffusion
-
连续数据的表示与生成:LatentLM使用变分自编码器(VAE)将连续数据表示为潜在向量,并通过引入下一步令牌扩散(next-token diffusion)技术,自回归地预测潜在向量。这种方法使得在Transformer隐藏状态的条件下,扩散头生成潜在向量,并通过VAE解码器重构生成的连续数据。 -
离散数据的生成:对于离散数据,LatentLM使用共享的Transformer骨干网络,通过软最大(softmax)头进行下一令牌预测。与传统方法不同,LatentLM通过σ-VAE维持潜在空间的方差,确保生成的表示适合自回归解码。 -
统一的多模态生成与理解:LatentLM通过语言建模的范式,将离散和连续数据的生成过程统一,从而简化了实现并可以共享信息。与基于量化的连续数据表示方法相比,LatentLM能够更高效地进行数据压缩,并保持较低的重建损失。
-
图像生成:在ImageNet上的图像生成任务中,LatentLM表现出与基于扩散模型或离散令牌的模型竞争的性能,尤其在模型规模扩展上,LatentLM的效果超过了DiT模型。 -
多模态大语言模型:在文本、图像-文本对和交织数据的训练下,LatentLM在语言建模、文本到图像生成和视觉语言理解等任务上,均优于Transfusion和基于向量量化图像令牌的模型。 -
语音合成:在文本到语音合成任务中,LatentLM也超过了传统系统。由于使用连续表示进行编码,LatentLM的压缩比远高于基于量化令牌的方法,这提升了训练和推理的效率。

3DSRBench: A Comprehensive 3D Spatial Reasoning Benchmark
-
3DSRBench基准的构建:本文首次提出了一个全面的3D空间推理基准,涵盖了12种问题类型,集中在高度、位置、方向和多物体推理四大类空间关系上。通过手动标注2,100个自然图像的视觉问答对,确保了问题覆盖了包括刚性物体、人类、动物及隐式概念(如车上的标志或广告牌上的箭头)等广泛的开放词汇实体。 -
多视角数据与复杂场景的挑战:为了进一步提高评估的全面性,研究还对672个多视角合成图像进行了标注,涉及不同的6D视角(3D位置和3D方向),这对于LMMs在复杂场景下的空间推理尤为重要。通过这些数据,能够有效评估模型在不同视角下的表现,尤其是对常见视角和不常见视角的推理能力,后者在机器人和嵌入式AI中的应用尤为常见。 -
FlipEval策略:为了增强评估的鲁棒性,3DSRBench引入了FlipEval策略,通过设计问题与答案的配对方式,使得模型在推理时能够面临不同类型的挑战,避免过于简单的回答,增强推理的多样性和复杂度。 -
数据分布和多样性:基准特别关注数据分布的平衡,包括不同类型问题的对称数据(如同一问题给出正反答案的图片对)和问题的多样性,确保3D空间推理评估的全面性和可靠性。

HuggingFace&Github
Sora 中文 提示词 指南
-
文本到视频 -
动画 -
扩展生成的视频 -
视频到视频编辑 -
连接视频 -
图像生成(文本到图像)
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/28912.html