我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息 如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
资讯
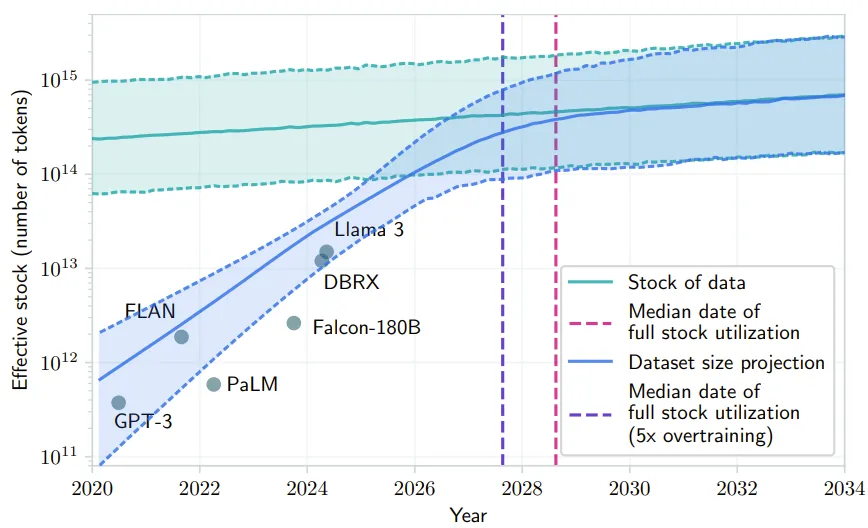
AI 发展遇到瓶颈:大模型扩展的技术挑战与突破方向 近期,关于大型语言模型(LLM)扩展潜力是否达到瓶颈的讨论引发了广泛关注。根据一项研究预测,2028年左右,人类生成的数据将被耗尽,届时基于大数据的LLM发展或将放缓甚至停滞。论文《Will we run out of data? Limits of LLM scaling based on human-generated data》探讨了这一问题,并揭示了AI行业正在寻找新途径以应对这一挑战。
OpenAI内部的研究者和知情人士透露,GPT模型的改进速度正在放缓,主要原因是高质量训练数据的供应减少。模型训练所需的文本数据源(如网站和书籍)已接近被全面利用。为此,OpenAI成立了一个专门的基础团队,研究如何延续模型扩展定律的有效性。 数据稀缺应对:为弥补数据不足,Orion模型部分采用了AI生成的数据进行训练。这种策略虽能增加数据量,但存在模型与早期版本趋同的风险,影响性能多样性。
为了克服当前扩展定律的限制,AI研究者正在探索训练后优化模型的新策略。推理时间计算(test-time computation)成为一种潜在解决方案,通过在模型回答问题时增加计算资源,提升输出质量。OpenAI的o1推理模型便是这种尝试的实例。此模型虽能提高推理质量,但因其计算成本是传统非推理模型的六倍,目前客户使用有限。 强化学习与人类反馈(RLHF):在训练后,AI模型通过学习大量已正确解决的问题进一步优化。人类评估员对模型在特定任务上的表现进行评分,指导研究者调整模型回答,如代码生成或复杂问题求解。
一些专家和投资者质疑LLM的性能是否已趋于平稳。风险投资人Ben Horowitz指出,即便增加了训练GPU的数量,智能提升并未达到预期效果。尽管如此,许多业内人士,如Meta和OpenAI的领导者,强调仍有空间探索创新,如多步骤任务处理和多任务整合等新功能。 推理时间计算的优势:在TEDAI会议上,研究科学家Noam Brown指出,通过增加每次查询的计算预算,模型性能可持续提升。这一策略开辟了在数据和训练瓶颈之外提升模型性能的新维度。
尽管合成数据可以补充训练数据缺口,但在涉及常识推理等任务时,其效果有限。Databricks联合创始人Ion Stoica指出,LLM在解决复杂问题上有所进步,但在分析文本情感或解释医学症状等常规任务上仍进展缓慢。他强调,合成数据不足以弥补事实数据的需求。 技术突破的未来:尽管AI扩展面临挑战,技术专家和开发者正尝试突破现有瓶颈,通过创新推理策略和数据处理方法推动LLM继续发展。 微调技术:LoRA与完全微调的技术差异及挑战 微调技术在大语言模型应用中极为重要,其中低秩自适应(LoRA)和完全微调是两种主要方法。近期,麻省理工学院的研究深入探讨了两者在微调效果和模型行为上的差异,尤其是在面对不同任务时的表现。
研究通过奇异值分解(SVD)分析微调后的权重矩阵,揭示了LoRA和完全微调在权重结构上的显著差异:
侵入维度:LoRA 微调中出现了新的高秩奇异向量,称为“侵入维度”,这些维度与预训练模型的奇异向量几乎正交。这些侵入维度使LoRA模型在任务之外的泛化能力较差。而完全微调不会产生此类维度,权重矩阵在光谱结构上与预训练模型保持一致。
实验结果:研究表明,随着LoRA秩增加到某个阈值(如r = 2048),侵入维度逐渐消失,LoRA变得接近完全微调的表现。然而,在较低秩(如r ≤ 8)时,侵入维度仍然明显存在。
在连续学习环境中,研究进一步比较了LoRA与完全微调在多个任务上的适应能力:
遗忘现象:低秩LoRA模型在训练新任务时表现出更显著的遗忘现象,即会丢失对之前任务的记忆。而完全微调在此方面表现得更加稳健。
任务顺序实验:在一系列下游任务中(如MNLI、QQP等),随着训练任务的推进,低秩LoRA的表现逐渐下降,尤其是当r = 1时,其性能甚至低于预训练基线。提高LoRA秩至r = 64或更高可以减轻这种遗忘,但过高的秩(如r = 768)又会导致过度拟合。
U形趋势:在持续学习中,LoRA的表现呈现U形趋势,过低或过高的秩都会导致更多遗忘,而中间值(如r = 64)则效果最佳。
伪损失分数:分析表明,当r = 8和r = 64时,LoRA的遗忘少于完全微调,但极低(r = 1)和极高(r = 768)会使遗忘增加。
侵入维度的影响:LoRA在低秩时虽能实现较好的任务表现,但其侵入维度导致模型在预训练分布外的泛化能力下降。
参数化的权衡:尽管LoRA能以更少的可训练参数实现良好效果,高秩参数化在提升泛化和稳定性上更为优越,但需保持秩稳定以避免过度拟合。
田渊栋专访:兼职小说家的AI科学家,讲述信息时代人类命运 《破晓之钟》通过细腻的笔触展示了高强度的科研日常及技术细节。故事围绕顶尖实验室的博士生科研经历展开,描写了从实验结果无法复现引发的怀疑到对代码、实验设计及理论等多个环节的深究。这些情节凸显了真实科研中的挑战与不确定性,揭示科学家们在创新过程中的反复试验和探索。 田渊栋在他的职业生涯中曾专注于多领域技术研究,从自动驾驶到深度学习,再到强化学习与大型语言模型(LLM)的优化。他在Meta FAIR实验室中的工作突出体现了技术细节,例如通过单个GPU实现OpenGo的推理,超越专业围棋选手,及在强化学习和神经网络中的系统优化。特别是在优化神经网络推理效率、研究稀疏化注意力机制、结合深度学习和决策优化方面,田渊栋探索了如何将理论研究成果高效应用于复杂问题的解决。 他还提出了链式思维(CoT)在推理中的局限性,认为其过长时训练难度增加,无法高效解决复杂问题。这与现实中的算法和模型优化息息相关,如研究梯度下降如何自动发现数据中的代数结构并在网络权重中体现。田渊栋的研究工作不仅揭示了深度学习的潜力,也探索了其“涌现”能力的机制。 此外,他通过科幻创作如《破晓之钟》表达对未来智能技术的反思,将科幻与技术结合,探讨在AI时代中人类价值、信息时代的外星文明冲突及社会动力。这类小说在描绘纳米机器人、外星生物等概念的同时,融入其对人工智能和研究经历的深刻思考,提供了对人类与技术关系的启示。 https://mp.weixin.qq.com/s/Mwt-NuGPUcsLSNPxxapdAA
微软开源MoE新路径
创新训练方法: GRIN MoE采用了新一代SparseMixer来优化专家路由梯度估计,解决了传统MoE训练中仅使用门控梯度代替路由梯度的问题。具体来说,SparseMixer-v2通过随机采样替代TopK函数,并应用Heun’s third order method近似计算梯度,提供更精确的专家路由梯度估计。相比于传统的GShard方法,SparseMixer-v2在训练后期显示出更好的性能。
计算并行策略: 与传统专家并行策略不同,GRIN MoE舍弃了专家并行,转而采用数据、pipeline和张量并行组合进行训练。这一调整避免了传统专家并行中的token丢弃问题,提升了训练效率。通过Megablocks库的grouped_GEMM内核等工程优化,该模型在训练效率上实现了比密集模型高出80%的提升。
性能表现: GRIN MoE的总参数量约42B,但推理时激活的参数仅6.6B,显示出极高的参数利用效率。其在GSM-8K数学测试中得分90.4,在HumanEval编码任务中取得74.4分,MMLU测试中得分79.4,超越了Mixtral和Phi-3.5等同类架构,甚至在某些任务上优于14B级别的Phi-3。
并行扩展和负载均衡: GRIN MoE通过结合pipeline和张量并行扩展专家数量至52个(132B参数),而不使用专家并行,以实现更大规模的模型划分。此外,通过全局计算负载均衡损失,进一步优化专家间的负载分配,虽然带来一定通信开销,但可通过计算重叠降低延迟。
应用示例: GRIN MoE在中国的高考数学测试中表现出色,展示了其卓越的数学推理能力,验证了模型在复杂实际问题中的应用潜力。这一性能验证表明该模型在严苛标准下的高效性和鲁棒性。
推特
00 Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格式
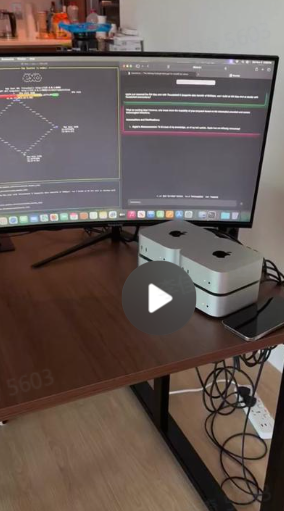
M4 Mac Mini AI 集群:仅仅两个苹果手机大小,目前运行 Nemotron 70B,速度为每秒 8 个 token,并且可以扩展到 Llama 405B 使用 @exolabs 和 Thunderbolt 5 互连(80Gbps),将 LLM 分布在 4 台 M4 Pro Mac Mini 上运行。 这个集群很小(iPhone 作为参考)。目前运行 Nemotron 70B,速度为每秒 8 个 token,并且可以扩展到 Llama 405B(基准测试即将发布)。
https://x.com/alexocheema/status/1855238474917441972 构建AI封装器的AI封装器?Fekri分享AI应用创建器,生成完整的 Next.js AI 应用
8周前我开发了一个AI封装器,它可以……构建AI封装器 🤯 • 生成完整的 Next.js AI 应用(包括后端 API 路由!) 今天我在 ProductHunt 上发布——期待你的支持 🙏🏽
https://x.com/fekdaoui/status/1855522108618748222
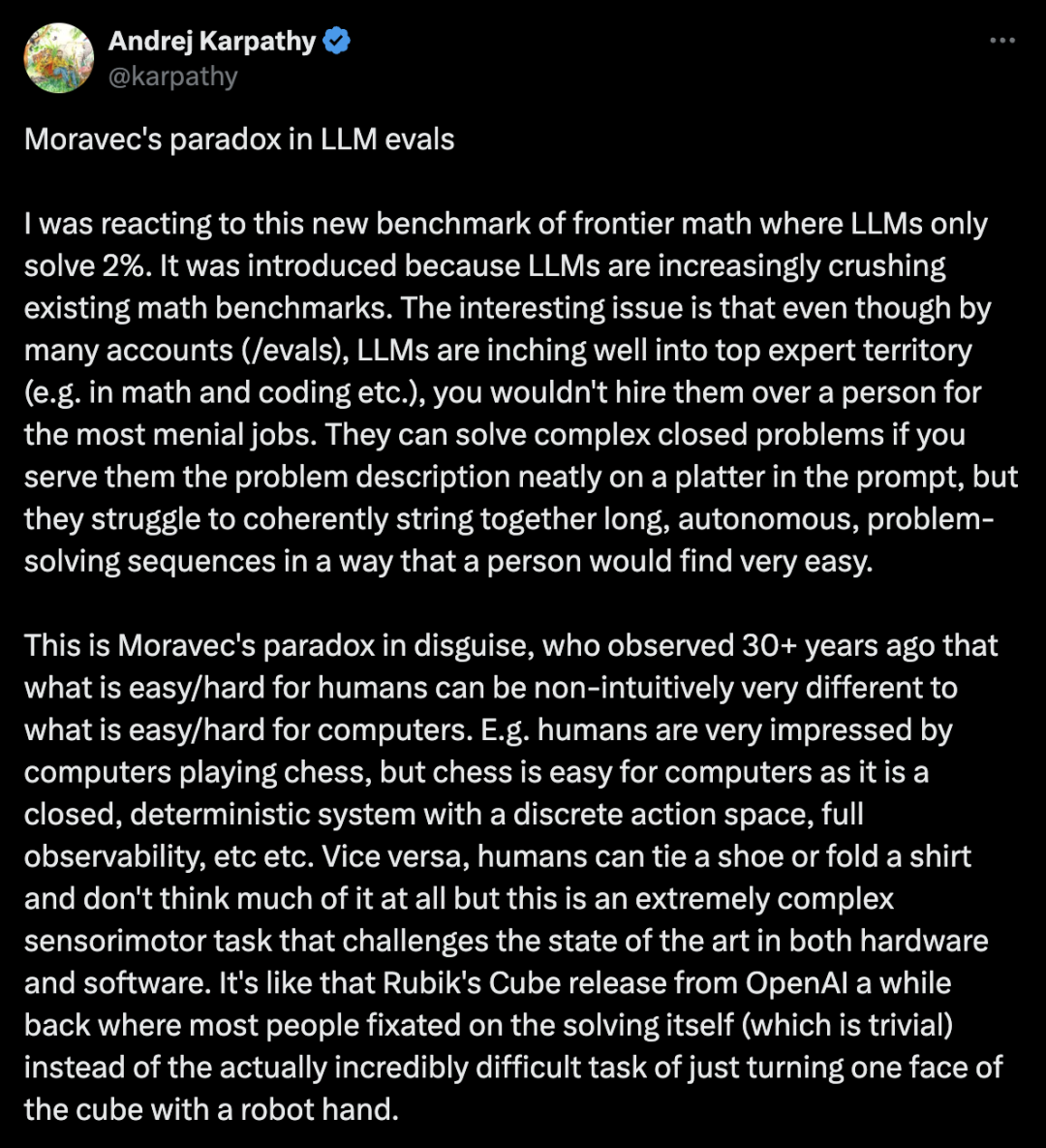
Gemini现可通过OpenAI库访问,三行代码使用最新Gemini模型 Gemini 现在可以通过 OpenAI 库访问了!更新 3 行代码即可开始使用最新的 Gemini 模型 :) 从今天开始,开发者可以通过 OpenAI 库和 REST API 访问最新的 Gemini 模型,这使得使用 Gemini 变得更加便捷。我们最初将支持聊天完成 API 和嵌入 API,未来几周和几个月内还会增加更多的兼容性。你可以在 Gemini API 文档中了解更多信息。如果你尚未使用 OpenAI 库,我们建议直接调用 Gemini API。 https://x.com/OfficialLoganK/status/1854980006927298577 Karpathy强推FrontierMath:用于评估 AI 在高级数学推理方面表现的基准 今天我们发布了 FrontierMath,这是一个用于评估 AI 在高级数学推理方面表现的基准。我们与60多位顶尖数学家合作,创建了数百道原创且极具挑战性的数学题目,目前的 AI 系统解题率不到 2%。现有的数学基准测试如 GSM8K 和 MATH 正在接近饱和,AI 模型在这些基准上得分超过90%,部分原因是数据污染。FrontierMath 大大提高了难度。我们的题目通常需要专家级数学家花费数小时甚至数天才能解决。我们评估了六个领先的模型,包括 Claude 3.5 Sonnet、GPT-4o 和 Gemini 1.5 Pro。即使给模型扩展了思考时间(10,000 tokens)、提供了 Python 访问权限并允许进行实验,成功率仍低于 2%,相比之下传统基准测试的成功率超过 90%。我们发布了带有详细解答的示例题目、专家评论和我们的研究论文(https://epochai.org/frontiermath)。 Karpathy评论:Moravec 悖论在 LLM 评估中的体现 我对一个新的前沿数学基准产生了兴趣,其中LLM只能解决2%的问题。这个基准的引入是因为LLM在现有的数学基准上表现越来越优异。一个有趣的问题是,尽管根据许多评估(如在数学和编程领域),LLM逐渐接近顶尖专家的水平,但如果是最基础的工作,你仍然不会选择它们而不是人类。LLM可以在提示中提供清晰的问题描述时解决复杂的封闭问题,但它们在连贯地串联长时间的自主解决问题的序列方面表现挣扎,而这是人类很容易做到的。 这是Moravec悖论的伪装形式。Moravec在30多年前观察到,对人类来说简单或困难的任务,对计算机而言可能非直观地截然相反。比如,人类对计算机下棋的表现印象深刻,但下棋对计算机来说很简单,因为它是一个封闭的、确定性的系统,具有离散的动作空间和完全的可观测性。反过来,人类系鞋带或叠衣服时不会觉得复杂,但这是一个极其复杂的传感运动任务,对最先进的硬件和软件来说都是挑战。这有点像OpenAI之前发布的机器人手解魔方的项目,大多数人都关注解题本身(这其实很简单),而忽略了用机器人手转动魔方一个面的极高难度。 因此,我非常喜欢这个FrontierMath基准,我们应该创造更多类似的基准。但我也认为这是一个有趣的挑战:如何为那些“看似简单但实际上很难”的任务创建评估。比如,长时间的上下文处理、一致性、自主性、常识、多模态I/O的有效工作……我们如何构建出良好的“基础工作”评估?就像你希望团队中任何入门级实习生具备的能力那样。 https://x.com/EpochAIResearch/status/1854993676524831046 Perplexity CEO分享构建产品的方式:“我们不做产品评测。” 在这个片段中,@AravSrinivas(Perplexity的CEO)分享了他如何通过以用户而非CEO的身份提供反馈,来帮助团队更快地发布产品。 Aravind 给我深入展示了 Perplexity 构建产品的方式,包括: 我也很喜欢他对想要成就一番事业的年轻人给出的真诚建议。 📌 立即观看我们的完整访谈:https://youtu.be/X1oxHy03ZF0
https://x.com/petergyang/status/1855634165976498249 产品 Genbler Genbler 是一个综合性的 AI 平台,可以为内容创作者提供强大且易用的工具,帮助他们快速制作高质量内容。其主要功能包括面部替换、背景更换、图像增强、文本转动漫视频等,适用于艺术家、营销人员和教育工作者等多种用户。Genbler 的使命是打破传统创作的限制,让所有创作者都能轻松实现他们的创意,推动无限的创造力。
投融资 「可栗口语」完成数百万元天使轮融资,打造AI个性化口语学习平台 近日,AI口语学习平台「可栗口语」宣布完成数百万元天使轮融资,投资方为嘉程资本和源合资本,本轮融资及后续融资由源合资本独家担任财务顾问。融资资金将用于团队扩展、核心技术研发及市场推广。 可栗口语创立于2023年,旨在通过AI提供个性化学习方案,提升用户的英语口语水平。创始人兼CEO周树帆具备深厚的技术背景,曾任职于微软互联网工程院,专注于深度学习、自然语言处理及多语言模型开发。团队核心成员在教育领域同样拥有丰富经验。 在全球化趋势下,成人英语学习需求不断增加,市场规模于2023年已达1.3万亿元。现有产品未完全满足用户的碎片化和场景化学习需求。可栗口语通过其“AI情景课”填补这一市场空白,课程涵盖职场、旅游等多种应用场景,共有2000多节课程,涵盖1.5万个高频词汇及3万个例句。用户可通过虚拟情景对话与AI互动,获得实时反馈,跟踪学习进展。 该平台依托深度学习和AI大模型,提供动态分析用户学习进度并推荐相应内容,实现高度个性化的学习体验。用户仅需每天投入短时间即可获得显著进步,逐步培养长期稳定的学习习惯。周树帆表示,未来将持续优化AI能力,扩展用户群体,并打造UGC生态系统,以提升用户学习体验与数据积累。 公司官网:https://www.oral-craft.com/ https://36kr.com/p/3027441691125252 Crypto-AI 初创公司 Pond 完成750万美元种子融资 Pond 是一家致力于开发面向加密货币领域的去中心化 AI 模型平台的初创公司,近期完成了750万美元的种子轮融资。本轮融资由 Archetype 领投,参与的投资者包括 Coinbase Ventures、Near Foundation、Cyber Fund 和 Delphi Ventures。著名的天使投资人如 Near Protocol 联合创始人 Illia Polosukhin、Plume Network 联合创始人 Chris Yin 以及 Matrixport 的联合创始人 Cynthia Wu 等也参与其中。 此次融资始于2023年4月,并于7月顺利完成。该轮融资采用了“未来股权简单协议(SAFE)”形式,并附带代币权证。尽管公司未公开此轮融资后的估值,Pond 表示,这笔资金将用于支持其建设一个涵盖数据、模型计算、训练和推理的完整 AI 模型生态系统,推动区块链数据在安全、推荐及 DeFi 等应用中的创新发展。 公司官网:https://cryptopond.xyz/ https://www.theblock.co/post/325044/crypto-ai-startup-pond-seed-funding 具身智能企业「千寻智能」完成天使+轮融资 近日,具身智能企业「千寻智能」完成了由柏睿资本独家注资的天使+轮融资,自成立半年多以来已实现三轮融资。本次融资将用于引进人才和推动产品在商业场景下的迭代及业务拓展。投资方柏睿资本由宁德时代天使投资人李平创办。此前,顺为在2024年领投千寻的种子轮并参与天使轮。 千寻智能以全栈技术能力见长,专注于打造通用人形机器人和具身大模型,支持多场景泛化应用。今年9月,该公司展示了通用机器人在非结构化环境下完成复杂任务的技术突破,标志着多任务泛化能力的提升。创始人兼CEO韩峰涛表示,依托伯克利的AI技术与硬件实力,千寻计划在2025年实现数百台具身智能产品的交付,形成物理数据飞轮闭环,加速模型和算法的迭代。 联合创始人高阳具备深厚的科研背景,在机器人跨模态交互与强化学习领域具有突出贡献,与知名学者如Pieter Abbeel和Sergey Levine展开了深入合作。他的研究强调数据质量对模型的核心作用,启发了高质量数据的广泛应用和“data scaling laws”的发现。这一研究推动了机器人零样本泛化能力的实现,提升了千寻在多场景作业中的竞争力。 千寻智能通过多维协同和商业化团队的高效运作,已在国内外市场开展80+场景调研,并在新能源、物流、餐饮等领域初显成果,奠定了稳健的发展路径。公司将继续深化其技术和商业布局,以引领具身智能技术的全球化普及。
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/11/21689.html