
产品二姐
读完需要
分钟
速读仅需 5 分钟
1
最近 AI 大模型上演的“上下文长度”之战确实有点热闹,我给大家整理了一个时间轴,并用图形化的方式展示出各个模型支持的上下文长度以及价格(图中黄色方块表示)。
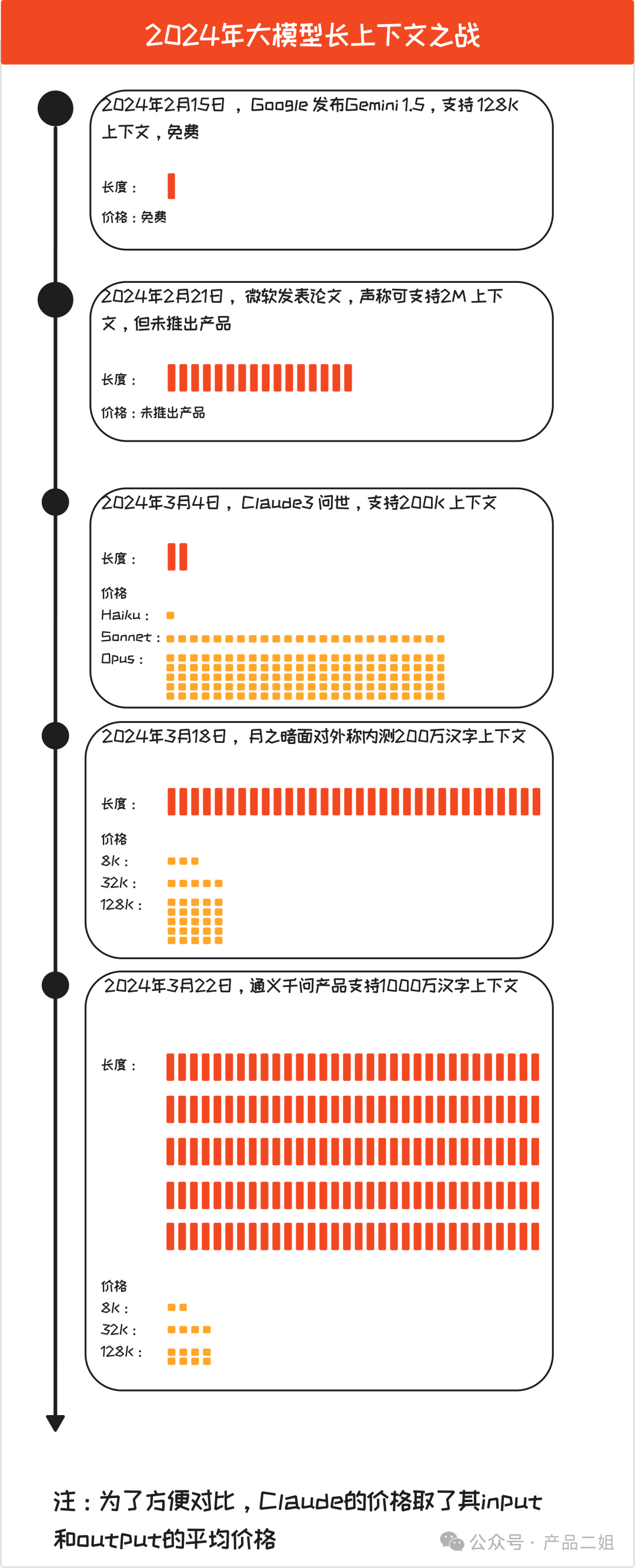

不难看出,上下文越长,相应的成本也成倍增加。所以,对于应用开发者,与其讨论模型是否应该在长度上卷来卷去,不如今天重点讨论一下如何压缩模型调用成本的问题。其中的经验和方法都是几个真实案例驱动下的探索总结,囊括了目前我所知道的降低模型调用成本的方法,希望对大家有所帮助,文章较长,适合收藏。
这也是之前之前一篇文章《做大模型AI应用一定要了解的成本计算公式》的续写,新同学也推荐阅读这篇比较受欢迎的老文章。
2
按照文章《一文讲清大模型AI应用架构》里定义的 AI 应用四层架构(算法算力数据层,模型层,应用层,用户层),我们能做的降本方法主要集中在模型层、应用层里。你将收获以下内容:
1.应用层降低 LLM 调用成本方法:
通过问答对向量库降低模型调用次数,从而实现降本,我会通过案例讲解。
借用昂贵模型生成问答对,将问答对作为 RAG 知识库,将优质问答对发给便宜模型以降低成本。
通过压缩 prompt, 降低 token 量实现降本,我会提供相应的开源代码。
优化 RAG 分块以降低 token 量实现降本。
2.模型层降低 LLM 调用成本方法:
借用昂贵大模型微调便宜小模型。
做好模型分发,好钢用在刀刃上,我会分享比较成熟的模型分发工具。
优先调用便宜模型,逐步升级调用不同等级的模型。
最后介绍一下大模型的成本监控工具:Langchain 的 LangSimith 的监控日志。
3
3.1
问答对向量库辅助问答,降低模型调用次数
用一张图来说明什么叫问答对向量库辅助问答,下图中红色部分就是问答对向量库的作用。
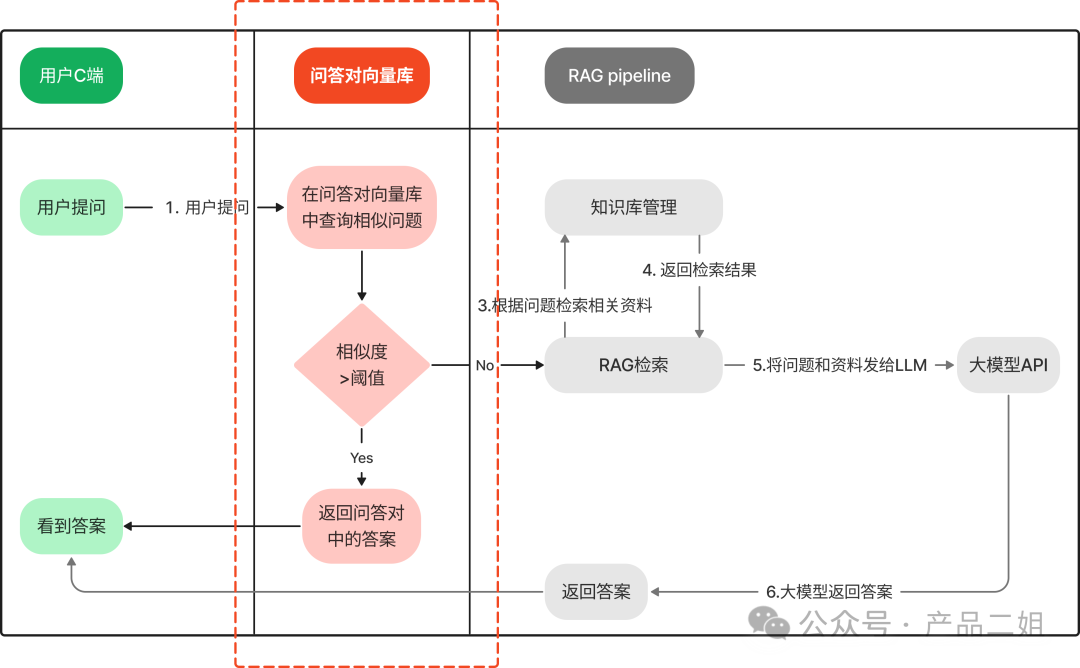
可以看出,在满足条件的情况下,系统完全可以脱离大模型完整执行一次问答。这个方法非常简单,事实上,它在大模型出来之前就很常见了。比如某个 SAAS 产品网站的帮助文档,可能用户 50%的问题都是相似的,那么产品运营人员把这些 FAQ 总结出来,存入向量数据库。下次当有用户问问题的时候,按照向量语义检索就可以找到对应答案,而无需调用大模型。
我对向量库语义检索的理解就是相当于原有 SQL 里运行了一条“Select * from vectorDB where query like …” ,尽管实际上向量库语义检索是通过下述方式来运行的。
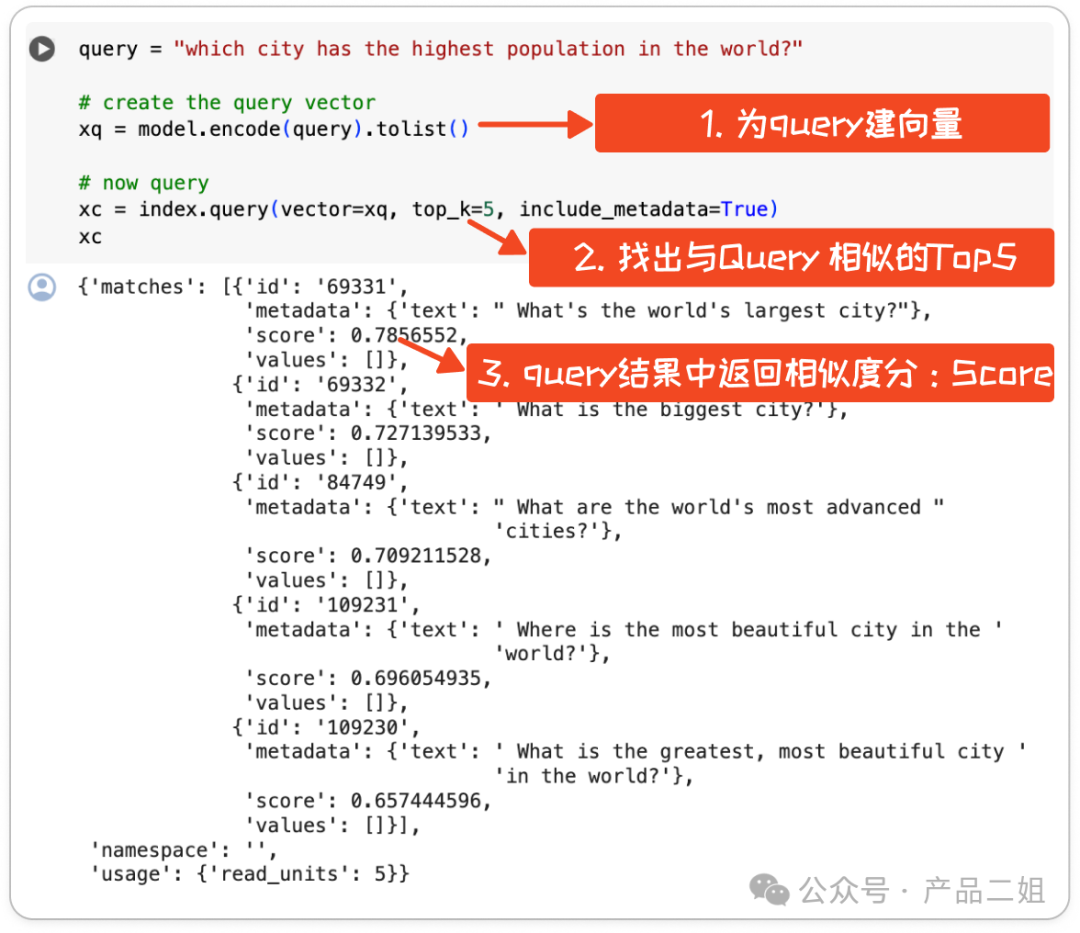
在这种场景下,个人觉得 LLM 更多的作用是大大加快了 FAQ 的生成速度,而非问答本身。我们试着对比在有、无大模型的情况下,完善 FAQ 的流程。
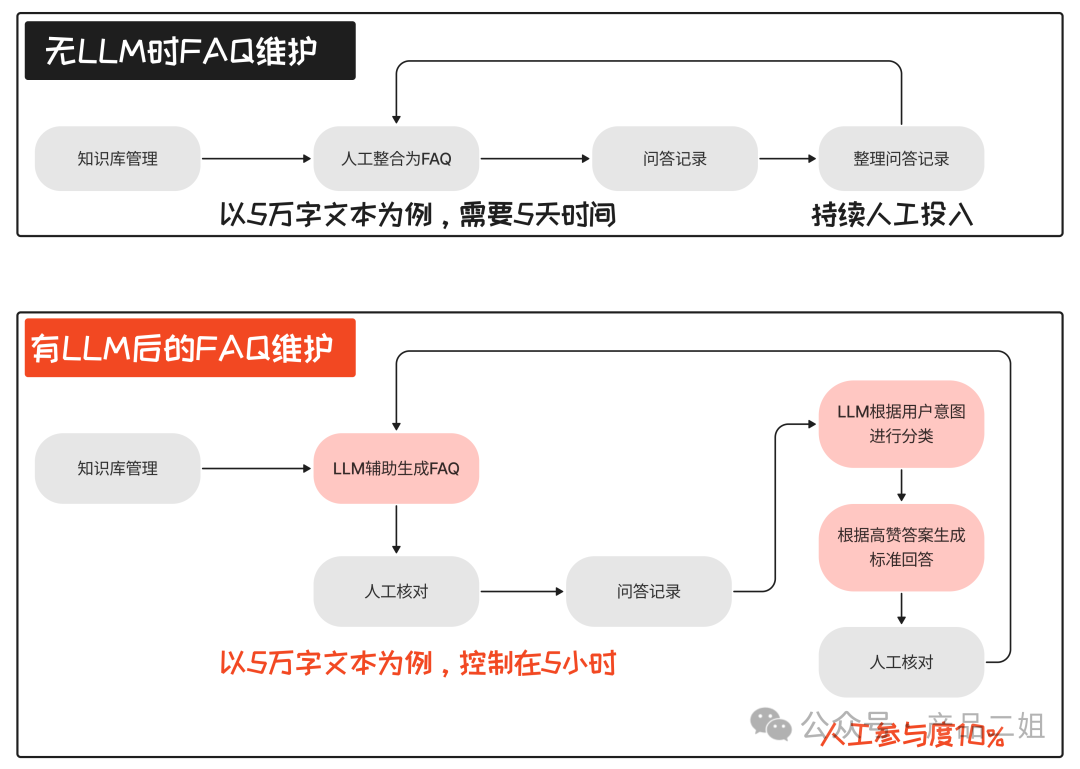
不难发现,FAQ 维护的速度在 LLM 的协助下有近十倍速的提升,更重要的是这背后也意味着迭代速度,服务效率和满意度的十倍速增长。在成本方面,在每次新知识产生的时候,会有一次模型调用的峰值,之后逐步下降。我概念性地绘制这样一幅图来说明大模型成本的曲线。
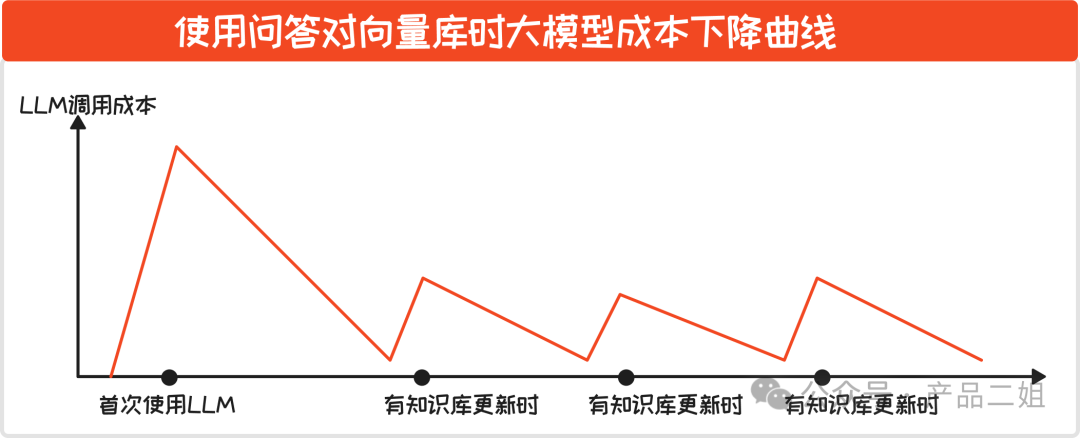
不过既然问答要依赖 FAQ,那么 FAQ 自身的更新也需要注意,FAQ 的维护方式分为两种:
1.由用户反馈驱动的被动更新:比如收到用户对某个答案的负面反馈(用户对回答点踩),运营人员需要核实问答库的答案是否准确、完备。
2.有 LLM 巡检驱动的主动更新:定期将 LLM + RAG 的答案和 FAQ 的答案进行对比,相当于“巡检”,来保证 FAQ 的准确性。
当然上述方法仅在有限场景中可以达到明显降本的效果,即:用户的问题比较集中,知识库的内容更新不会特别频繁或者更新前后差异不大。我们目前所接触的客户中,有两个都属于这种情况。其实,只要满足客户诉求,是不是大模型真的不重要。
此外,我也有看到类似方法也被升级使用:借用昂贵模型生成问答对,将问答对作为 RAG 检索出优质内容发给便宜小模型降低成本。原作者可以借助这种方法来优化 Agent 能力,这个方法我们没有实践,不过也可以拿出来和大家分享。
3.2
借用优质问答对+RAG 的方式来优化 Agent 能力
在论文 https://arxiv.org/abs/2310.03046 中,作者使用了一个多 Agent方案进行问答的。
方案中设计了一个代码 agent 专门负责撰写调用外部 API 的代码,比如根据给定某个 API 的接口文档,让这个 agent 写出调用 API 接口的代码。下面这种图是来自原文的架构图,紫色图标是我加上去用来说明过程的标注。
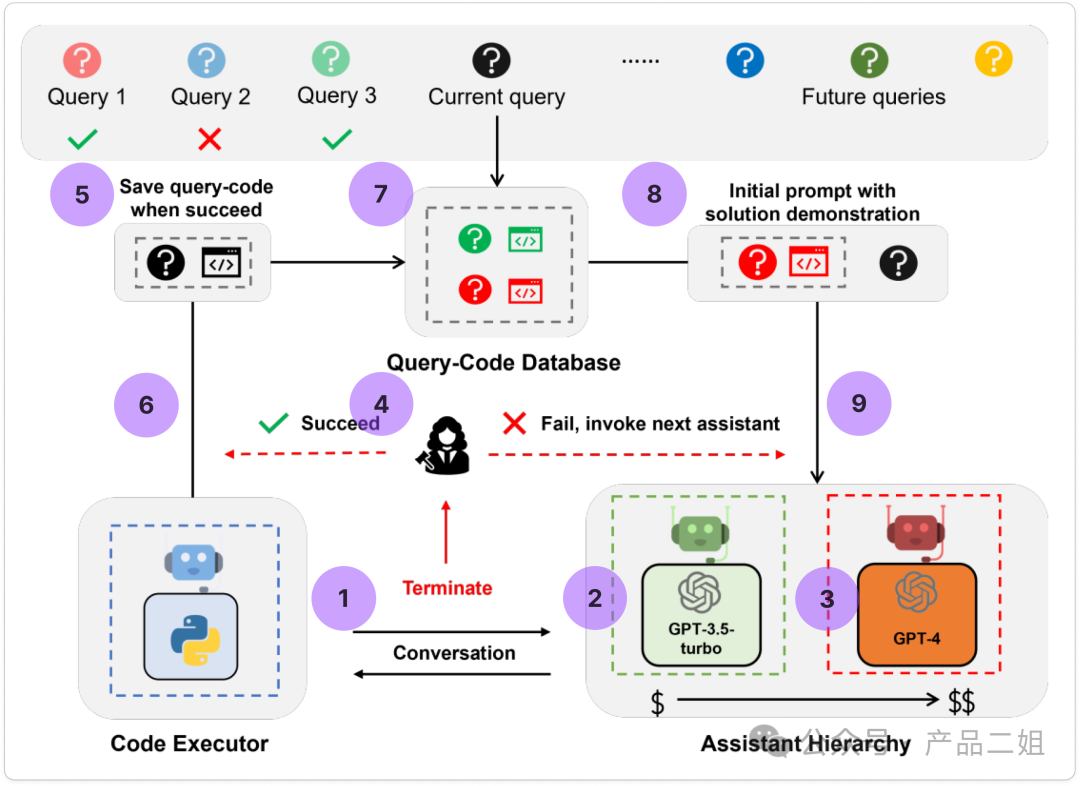
接下来我按照紫色序号来讲述 agent 的具体执行过程:
首先系统将用户诉求和大模型分发系统进行交互;
在大模型分发时,系统首先调用便宜模型 GPT 3.5 进行撰写,写好之后执行代码,如果成功,则接口返回成功,如果不成功,接口返回错误;
如果通过 GPT3.5 经过几轮还是不能返回成功,才开始调用 GPT4;
一旦有返回接口成功的记录;
系统就会将这次接口调用代码以及对应的用户诉求自动存入向量数据库;
当下次其他用户有诉求的时候,首先从向量数据库中检索是否有类似问题;
如果有类似问题,则提取出所有正确答案;
然后将答案加上本次用户的 query,一并合成 prompt;
将该 prompt 再发给大模型分发系统,首先调用低成本 LLM 模型,如果不能返回结果再调用高成本模型;
如此反复迭代反馈,最终可以得到一个比较能够自我进化的 code executor agent,且能迭代降低大模型使用成本。
这种场景与刚刚提到的单纯使用问答对辅助问答有两个不同的地方:
作者把“API 接口是否返回成功”作为一个高效的反馈,这相当于我们在 FAQ 的人工标注,达到了无人工介入即可达成目标的效果。
其次,作者把问答库作为一个 RAG 知识库在使用,但个人认为如果 FAQ 足够准确,问题相关度足够高,其实可以不用再发给大模型。
上述两种方法本质上是使用迭代方式构建优质问答对来降低大模型的成本,接下来就是通过压缩提示词的方式来实现降本了。
3.3
压缩提示词
首先说说这种方法的效果,以下是我自己日常使用提示词,经过压缩后文本长度压缩到原来的 70%(由 175 字压缩到 123 字) ,但模型返回答案非常相似。

这里用到的压缩神器就是微软LLM Lingua,他们开源了代码( 原创文章,作者:产品二姐,如若转载,请注明出处:https://www.agent-universe.cn/2024/03/8528.html