


MOLAR FRESH 2021年第23期
人工智能新鲜趣闻 每周一更新

2021.8.9
AI新资讯抢先看
01
Nat. Commun. | 用于持续学习心脏信号的临床深度学习框架
心律失常的诊断,即心脏功能异常的识别,有助于心脏病专家和广大临床医生做出正确的决策。进行心律失常诊断通常利用心电图(ECG)。深度学习系统的出现使得心律失常的自动诊断具有一定的规模和准确性,许多深度学习系统要求数据是独立同分布的。违反i.i.d.会不利于系统的学习行为,然而违反i.i.d.在临床环境中普遍存在。
应对动态环境带来的挑战是持续学习(CL)的重点。通过持续学习,学习系统可以在当前的任务中表现良好,而不影响在先前任务上的表现。牛津大学的Dani Kiyasseh等人发表于Nature Communications的研究成果提出了一种持续学习策略CLOPS.系统接收单导联心电图数据,并返回单一的心律失常诊断。这种深度学习系统可以在多种动态环境中执行心律失常诊断的临床任务,而不会灾难性地忘记如何执行先前的任务。
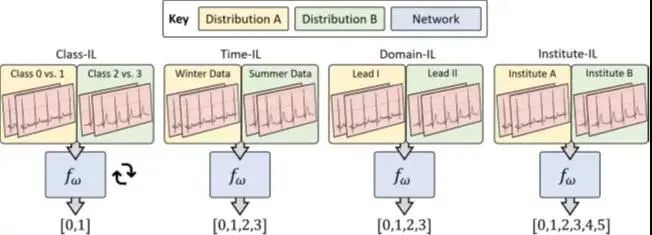
作者模拟了四种动态变化的环境,在这些环境中,深度学习系统依次执行心律失常分类的任务。在四个持续学习场景的三个场景中,CLOPS在泛化性能和后向转移两个方面都优于最先进的方法GEM和MIR。该框架有望为设计能够长期保持稳健的诊断系统铺平道路。
(来源:DrugAI)
02 ICRA 2021最佳论文 | 机器人“搭乐高”?上交大马道林提出“外部接触感知”理论,开拓机器人精细化操作新路径

“触觉传感与感知(Tactile Sensing and Perception)”是实现机器人精细化控制的主流研究方向之一,目前,相关研究主要集中在触觉传感器的研发设计上。
在近日结束的ICRA大会上,马道林发表的一篇题为 “基于触觉测量的相对运动跟踪和外部接触感知“的研究论文获得了ICRA 2021的最高荣誉——最佳论文奖。委员会认为,这篇论文基本解决了“刚性物体与外部环境的接触定位”问题,在机器人感知与操控研究方面做出了重要的理论贡献,同时论文中通过一系列缜密的实验过程和结果,有力地验证了“外部接触感知理论”在实践中的可行性。
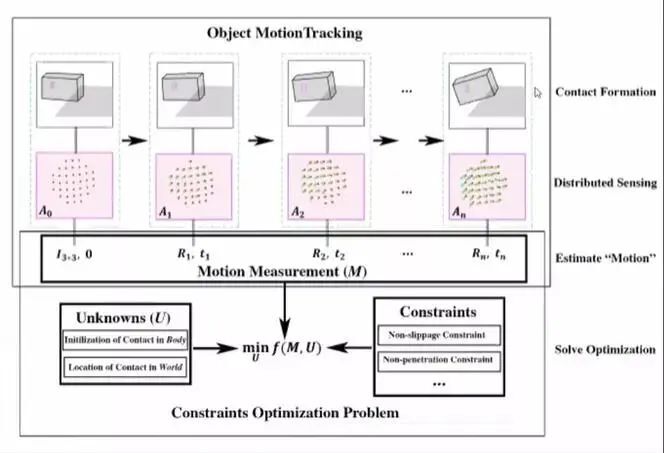
本论文中所使用的是一款由实验室自主开发的基于视觉的触觉传感器(视触觉传感器),它所尝试解决的问题是:机器人如何模仿人类手指完成灵敏度极高的装配任务?作者在论文中创新性地提出了一种“外部接触感知”理论框架。如果理论成立,通过触觉提供的关键状态估计信息,机器人可能执行自动化装配等富含接触操作的任务。马道林及团队通过三项实验验证了“外部接触感知”理论的合理性,为实现机器人构建空间感知和精细化操作提供了一条新的路径。不过,任何理论的提出到实践落地都是一个漫长的过程,机器人触觉感知也一样。从现阶段来看,无论是在驱动、传感、理论,还是规划、控制等方面,机器人实现精细化操作都有很长的路要走。
(来源:AI科技评论)
03 DeepFake噩梦来了!武大阿里团队提出FakeTagger,重新识别率达95%
我们已经生活在一个「眼见未必为实」的世界里了!
越来越多的软件可以让毫无专业知识的用户生成DeepFake图像,例如FaceApp等。
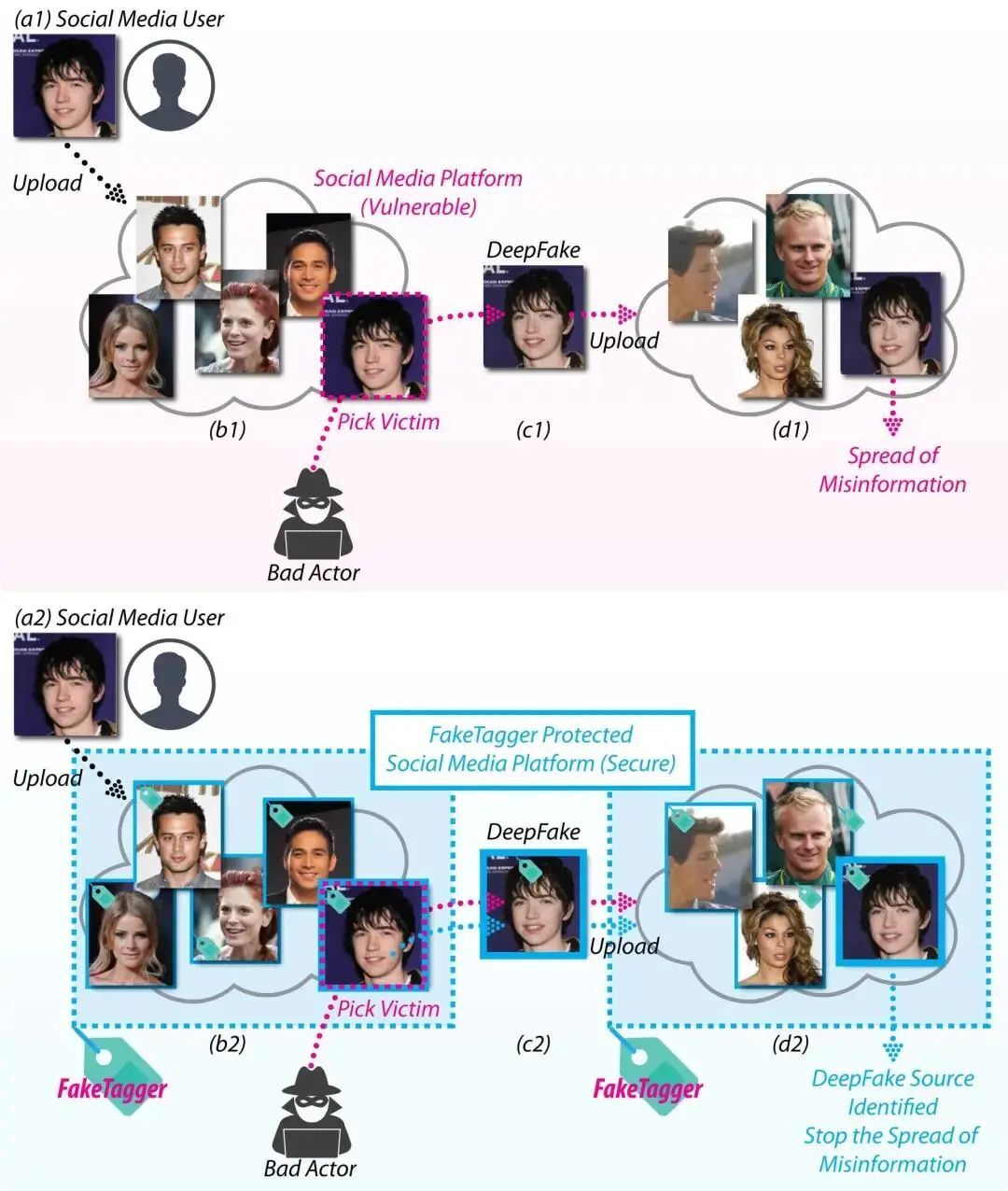
过去两年来,研究人员积极提出各种DeepFake检测技术。这些研究主要是在真实图像和合成图像之间,捕捉细微差异作为检测线索。为了更好检测出DeepFake,来自武汉大学的汪润等人合作开发了一个系统:「FakeTagger」。
FakeTagger利用编码器和解码器将视觉难以分辨的ID信息,以足够低的级别嵌入到图像中,使其成为基本的面部特征数据。 然后再通过嵌入的信息对图像进行恢复,从而确定是否为经过GAN处理的DeepFake图像。
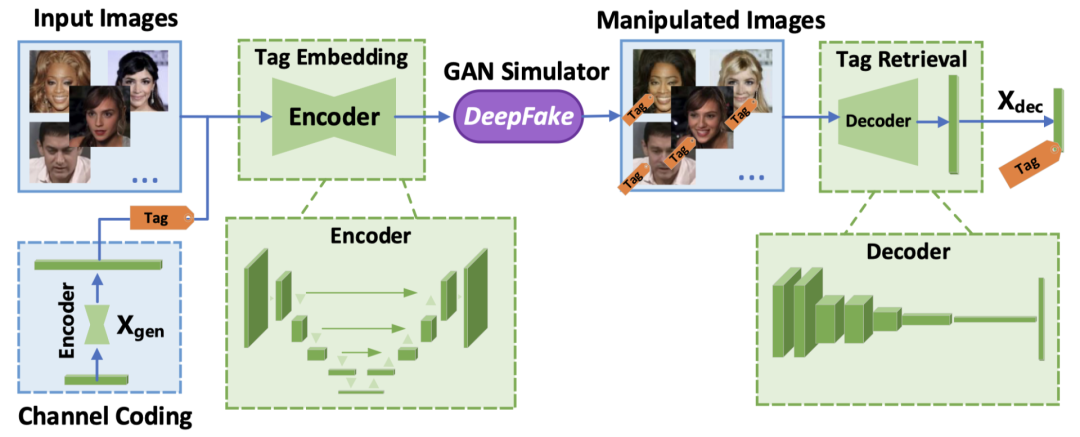
文中,作者采用了一个基于DNN的编码器和解码器,并对信息嵌入和恢复进行联合训练。同时,受到香农容量定理的启发,作者加入了冗余信息进而提高了信号通信的鲁棒性。在白盒环境中,FakeTagger在部分合成方面表现良好,如身份互换和脸部再现。 准确率最佳为97.3%,最差为95.7%。在黑盒环境中,FakeTagger的平均准确率超过了88.95%。与其他三个DeepFake相比,FakeTagger在整体合成中表现良好。
(来源:新智元)
04 这个GAN没见过猪,却能把狗变成猪
来自特拉维夫大学和英伟达的研究人员成功地盲训出领域自适应的图像生成模型——StyleGAN-NADA。也就是只需用简单地一个或几个字描述,一张目标领域的图像也不需要,StyleGAN-NADA就能在几分钟内训练出你想要的图片。
比如在人像上给出文字“Pixar”,就能生成皮克斯风格的图片;甚至把狗变成猪也行。


总的来说,StyleGAN-NADA的训练机制包含两个紧密相连的生成器Gfrozen和Gtrain,它俩都使用了StyleGAN2的体系结构。对于基于纹理的修改目标,该模型通常需要300次迭代,batch size为2,在一个NVIDIA V100 GPU上训练大约3分钟。在某些情况下(比如从“照片”到“草图”),训练只需不到一分钟的时间。
研究人员发现,对于纯粹是基于样式的图像生成,模型需要跨所有层进行训练,而对于较小的形状修改,则只需训练大约2/3数量的层数就能折中保持训练时间和效果。最后,将该模型与StyleCLIP(结合了StyleGAN和CLIP的域内图像编辑模型)、以及只用了Gfrozen生成器的模型对比发现,只有StyleGAN-NADA可以实现目标。再将零样本的StyleGAN-NADA与一些少样本的图像生成模型对比发现,别的都要么过拟合要么崩溃(MineGAN更是只记住了训练集图像),只有StyleGAN-NADA在保持多样性的情况下成功生成(但它也有伪影出现)。
(来源:新智元)
05
CALMS:多语言摘要中的信息抽取与共享 | ACL 2021 Findings

原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/08/8559.html