


MOLAR FRESH 2021年第13期
人工智能新鲜趣闻 每周一更新
谷歌、伯克利联合研究:为5种大型NLP模型,彻底算算这笔账
一项由谷歌和伯克利共同完成的论文,则针对几个大型模型(T5、Meena、GShard、Switch Transformer 和 GPT-3)的能源使用和碳足迹进行了计算,并对发现 Evolved Transformer 的神经网络架构搜索算法的早期估计进行了优化。

该研究突出强调了以下可以提高能源效率和二氧化碳当量(CO2e)的几个重要信息:
尽管使用了同样甚至更多的参数,在不损失精度的情况下,大型且稀疏激活的 DNNs 消耗的能量小于 1/10 的大型且密集 DNNs 的能量。
地理位置对于 ML 工作量调度很重要,即使是在同一个国家和同一个组织内,无碳能源和产生的CO2e的比例也可能相差约 5-10 倍。
特定的数据中心基础设施同样关键,因为云数据中心的能源效率比典型数据中心高出 1.4-2 倍。
尤其值得注意的是,DNN、数据中心和处理器的选择可以有效减少碳足迹,其数值高达 100-1000 倍。
研究更详细地讨论四个影响训练碳足迹的因素:算法和程序的改进、处理器的改进、数据中心的改进、能源结构的改进。团队致力于将训练期间的能源使用和推理(inference)纳入到行业标准基准之中。
(来源:数据实战派)
Nature:优于联邦学习的医疗数据共享技术Swarm Learning及应用案例
近年来,随着AI在医疗领域的广泛应用,数据合作与数据共享问题受到关注。2021年5月,Nature的一篇文章介绍了一种优于联邦学习的医疗数据共享方法Swarm Learning(SL)。
作者提出了一种去中心化的机器学习方法Swarm Learning(SL),将边缘计算和基于区块链的对等网络(Peer to peer networking)结合起来,用于不同医疗机构之间医疗数据的整合。SL通过Swarm网络共享参数,并在各个节点(Node)的私人数据上独立构建模型。Swarm Learning提供安全措施以支持数据主权、安全和保密性(这由私人许可的区块链技术实现)。
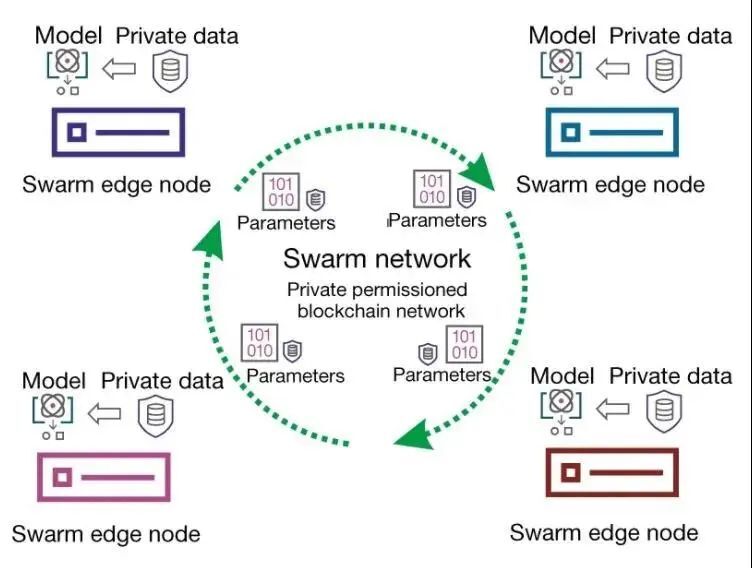
研究选择了四个异质性疾病的用例(结核病、COVID-19、白血病和肺部病变),来说明使用SL来开发疾病分类系统(基于分布式数据)的可行性。
结果表明,SL分类系统的性能优于在单个节点开发的分类系统。并且SL的设计完全满足保密要求。此外,SL通过设计提供了保密的机器学习,可以继承差分隐私算法、函数加密或加密转移学习方法的新发展。
作者Schultze认为,SL有可能成为真正的游戏规则改变者,可以帮助相关人员在全球范围内更容易获得丰富的医学经验。不仅研究机构,医院也可以联合起来形成这样的群体,从共享信息中受益。
(来源:集智俱乐部)
借助Transformer,DeepMind新模型自动生成CAD草图,网友:建筑设计要起飞了
在最近的一项研究中,DeepMind 提出了一种机器学习模型,能够自动生成高度结构化的 2D 草图,且结合了通用语言建模技术以及现成的数据序列化协议,具有足够的灵活性来适应各领域的复杂性,并且对于无条件合成和图像到草图的转换都表现良好。
研究者使用 PB(Protocol Buffer)设计了一种描述结构化对象的方法,并展示了其在自然 CAD 草图领域的灵活性;从最近的语言建模消除冗余数据中吸取灵感,提出了几种捕捉序列化 PB 对象分布的技术;使用超过 470 万精心预处理的参数化 CAD 草图作为数据集,并使用此数据集来验证提出的生成模型。

这些只是最初的概念验证实验。DeepMind 表示,希望能够看到更多利用已开发接口的灵活性优势开发的应用程序,比如以各种草图属性为条件,给定实体来推断约束,以自动完成图纸。
(来源:机器之心)
苹果公司华人研究员抛弃注意力机制,史上最快的Transformer!
近日,苹果公司在arxiv上上传了一篇论文,提出无需注意力机制的Transformer,即Attention Free Transformer (ATF)。
一个 AFT 层中,key和value首先与一组已学习的位置偏差组合在一起,其结果以元素级(element-wise)方式与query相乘。这种新的操作具有记忆线性复杂度(上下文大小和特征维度),使其既能兼容长输入文本,也能平衡模型大小。
AFT这个基础模型在文中又称为AFT-full,可视化的结果如下所示。对于每个时间步t来说,AFT都是value的加权平均值,结果就是和query的element wise的乘法。

除此之外,文中还介绍了 AFT-local 和 AFT-conv 两种模型,它们利用了局部性和空间权重分配的思想,同时保持了全局连通性。
这个模型在两个自回归建模任务和一个图像识别任务上进行了广泛的实验,证明了 AFT 在所有的基准测试中都表现出了很好的竞争性能。
论文的结论是AFT取代了原有attention机制中的点乘运算,并且在数据集上取得更好的结果,并且时间复杂度明显降低,这项工作将为Transformer类的模型提供参考。
(来源:新智元)
Yoshua Bengio:新步伐,迈向鲁棒泛化的深度学习2.0
在论文「Learning Neural Causal Models from Unknown Interventions」中,Bengio 等人使用神经网络表征了因果关系。假设有 A、B、C 三个变量,他们为每个变量应用了不同的神经网络,在给定任意其它变量的情况下,这些神经网络需要对其对应的变量进行预测。该模型在包含数十个节点的小型图上取得了很好的效果,这个具有前景的方向仍然具有很大的提升空间。
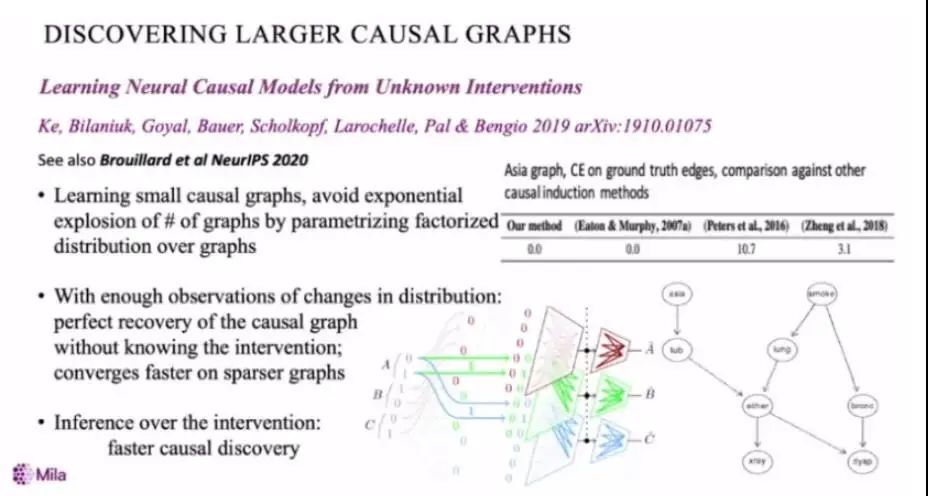
Bengio 等人在后续的一系列文章中引入了更多人类意识加工过程的特性。此外,Bengio 等人还试图将这些机制分离开来。在 ICLR 2021 上发表的论文「Object files and Shemata」中,他们将这些机制视为函数,并试图将这些函数与有待操作的变量分离开来。在普通的神经网络中,相同的神经元只能被用于特定活动存储的值,因此权值与活动有很强的关联。然而,通过使用注意力机制,我们可以迅速决定应该将怎样的机制、模型应用于工作空间中的哪些物体。而这些不同的函数、模型、物体之间也存在着竞争关系。
(来源:学术头条)
END






掌握AI咨询
了解更多科技趣闻
长按扫码 关注我们
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/06/8435.html